In enterprises with vast proprietary data, sales teams waste hours searching for past proposals, legal teams scroll through endless contracts, and even operations teams often rely on tribal knowledge or personal bookmarks. These delays cost money and trust, and result in missed sales opportunities, poor customer experiences, and even compliance risks. In truth, enterprises don’t lack knowledge, but they lack retrievability.
This is where LLM Knowledge retrieval models step in. Think of these models as powerful engines that can understand, process, and generate human-like language. When applied to enterprise settings, LLMs help unlock hidden knowledge buried deep within emails, reports, chats, and other documents. 71% of enterprises have already adopted these models and have received mission-specific, protected knowledge without disrupting their workflows.
In this blog, we will cover the impact and benefits of LLM-based knowledge retrieval models. Then, will move on to the core components of these models, how we build them tailored to specific enterprise needs, and how we craft these models to integrate into existing legacy systems and scale with the enterprise. At Intellivon, we specialize in delivering enterprise AI development solutions for knowledge challenges. Our tools help businesses move from data chaos to intelligent decision-making, securely, scalably, and smartly.

The Right Time to Integrate LLM-Based Knowledge Retrieval Models
The global retrieval augmented generation market size was estimated at USD 1.2 billion in 2024 and is projected to reach USD 11.0 billion by 2030, growing at a CAGR of 49.1% from 2025 to 2030, per Straits Research.
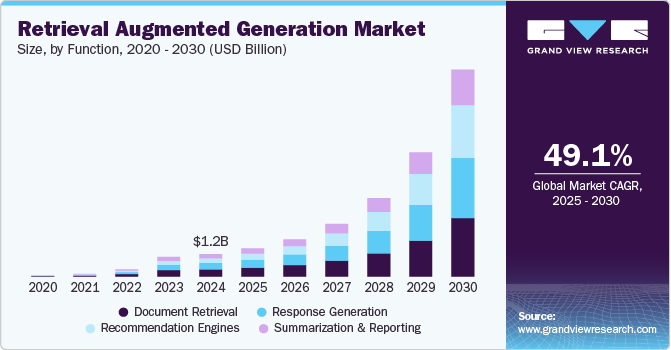
- The RAG market is expected to grow at a CAGR of 49.1%, reaching $11.0 billion by 2030
- The LLM market is projected to exceed $130 billion by 2034, with a CAGR between 29% and 37%, depending on the analysis.
- Enterprises in legal, healthcare, financial services, retail, and IT are increasingly adopting AI-driven knowledge management tools.
- RAG approaches provide the precision and real-time data grounding needed for effective LLM-powered generative AI outputs.
- Rapid innovation, lower infrastructure costs, and LLM integration into SaaS and industry applications are accelerating growth.
Why Do Modern Enterprises Need LLM Knowledge?
Modern businesses generate more data than they can manage. PDFs, chats, support tickets, emails, and internal wikis pile up. Searching through this manually wastes hours. Worse, decisions get delayed.
LLM Knowledge models offer smarter retrieval. They connect departments, reduce silos, and provide fast answers. They also adapt to each organization’s language, whether it’s legal terms, medical codes, or internal acronyms. This creates faster, more confident decision-making.
Why Traditional Enterprise Search Fails at LLM Knowledge Tasks
Legacy enterprise search tools may help find files, but they often fail to deliver accurate, context-aware answers. These systems weren’t designed to handle the complex, human-like understanding that LLM Knowledge tasks require. Here are some reasons why:
1. Keyword Dependency Limits Search Quality
Traditional search systems rely heavily on exact keywords. This means users must guess the exact terms used in a document. If one team says “customer service” and another says “client support,” a simple search might miss half the content.
This becomes frustrating when users deal with synonyms, abbreviations, or typos. To get the full picture, they’re forced to repeat searches using different variations. This wastes time and leads to missed insights.
2. No Understanding of Context or Intent
These tools treat each query as a standalone. They don’t “remember” what you’ve previously searched. So, if you type “Java,” the system might return results for the coffee, the programming language, or even the island, without knowing which one you mean.
Traditional systems also don’t adapt based on your role. A developer, HR manager, or sales rep would all see the same results, even if their needs are different. This lack of context makes information feel generic and unhelpful.
3. One-Size-Fits-All Results Hurt Productivity
Enterprise users span departments and job levels. Yet, most search tools show the same results to everyone. This lack of personalization slows teams down and increases cognitive overload.
What works for a legal analyst won’t help a support agent. Without tailoring, these systems deliver too much noise and not enough signal.
4. No Deep Understanding of Unstructured Data
Emails, chat logs, manuals, and policies are often unstructured. Keyword-based tools struggle here. They can’t extract insights or summarize complex paragraphs. As a result, vital knowledge stays buried.
Unlike traditional search, LLM knowledge systems understand language. They identify meaning, adapt to users, and surface the exact answer, even when it’s hidden in thousands of pages. This is why enterprises are rapidly shifting toward LLM-powered search.
Key Benefits of LLM Knowledge Retrieval Models for Enterprises
Enterprises are transforming the way they work by adopting LLM Knowledge systems. These models understand, adapt, and respond to modern enterprise knowledge retrieval missions. Here’s how they deliver real business value across departments:
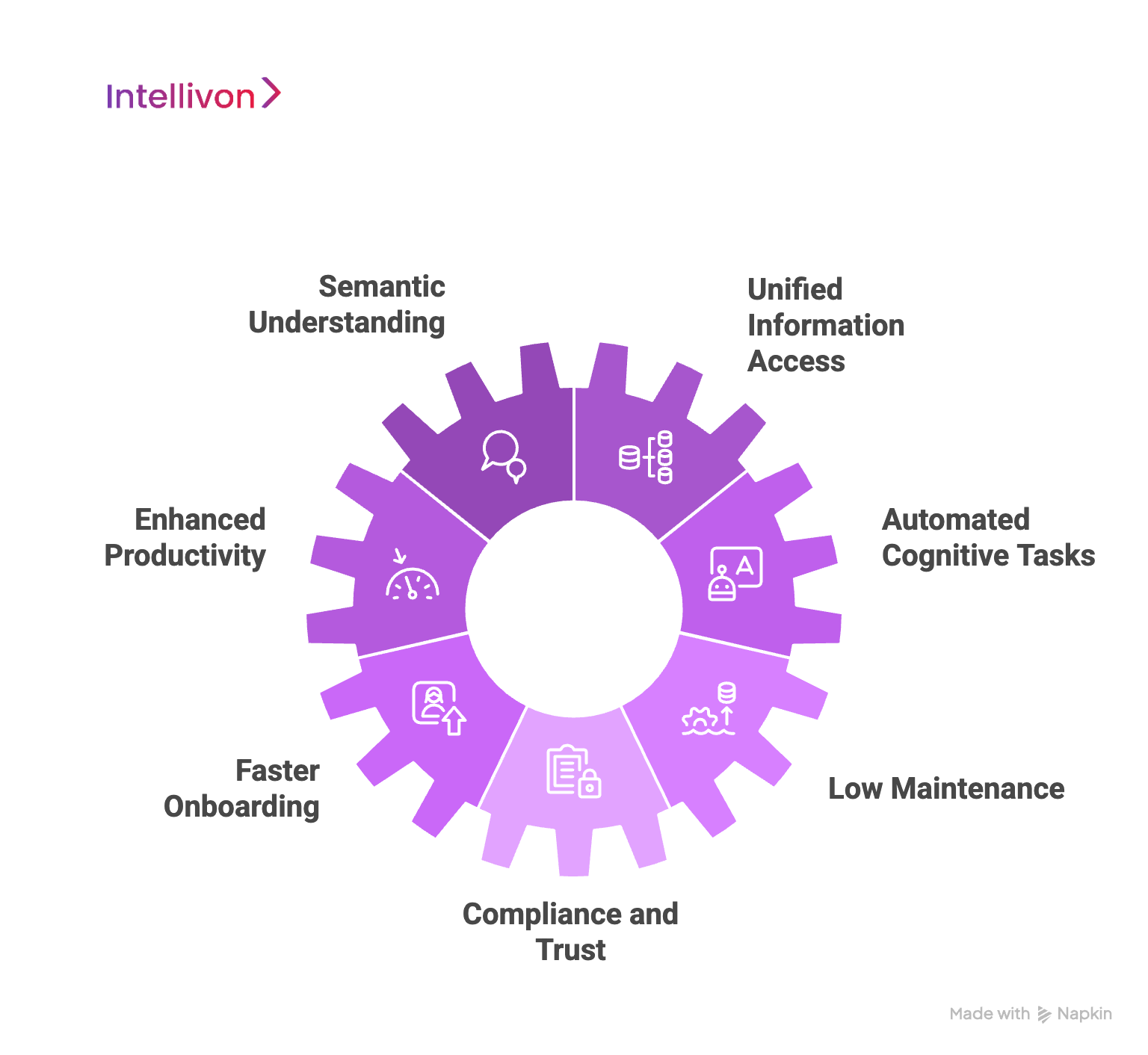
1. Semantic and Contextual Understanding
Unlike keyword-based tools, LLMs grasp meaning. They interpret natural language and vague questions with surprising accuracy. Employees no longer need to guess the right terms. Whether the query is clear or complex, LLMs deliver relevant, contextual answers quickly and confidently. This reduces search fatigue and improves knowledge access for everyone.
2. Unified and Intuitive Information Access
LLM Knowledge models integrate with portals, wikis, document systems, and cloud tools. They create a single interface that surfaces answers from across departments, HR, IT, finance, legal, or customer support. What was once scattered across silos becomes available in seconds, through a simple chat-like interface.
3. Dramatically Enhanced Productivity
When teams can get answers instantly, work speeds up. LLMs reduce time wasted in hunting for files, switching apps, or emailing for help. This leads to fewer errors, faster execution, and more time for strategic work, whether you’re in compliance, sales, or operations.
4. Intelligent Automated Cognitive Tasks
Beyond search, LLMs can draft emails, summarize reports, troubleshoot IT issues, or respond to FAQs. This brings AI into knowledge-heavy workflows, reducing manual load and improving scalability, without adding headcount.
5. Faster Onboarding
New hires don’t need to learn where everything lives. They can simply ask. With LLMs, even fresh employees can contribute from day one. Ramp-up time shrinks, and productivity rises faster.
6. Low Maintenance, High Agility
LLM-based models update continuously. As internal documents evolve, so do the answers, without retraining the model. This keeps systems current and reduces IT overhead.
7. Compliance, Trust, and Risk Management
LLMs provide citations with every answer. This traceability is essential for audits, legal reviews, and data accuracy. Enterprises in regulated industries benefit from this transparency and accountability.
LLM-based knowledge retrieval systems are a foundation for agile, intelligent enterprise growth.
Core Design Architecture of an LLM Knowledge Retrieval System
Behind every high-performing LLM knowledge system lies a thoughtful, modular architecture. It connects scattered data, translates it into machine-readable form, and delivers intelligent responses on demand. Let’s break down the four core layers that power these systems in enterprise environments.
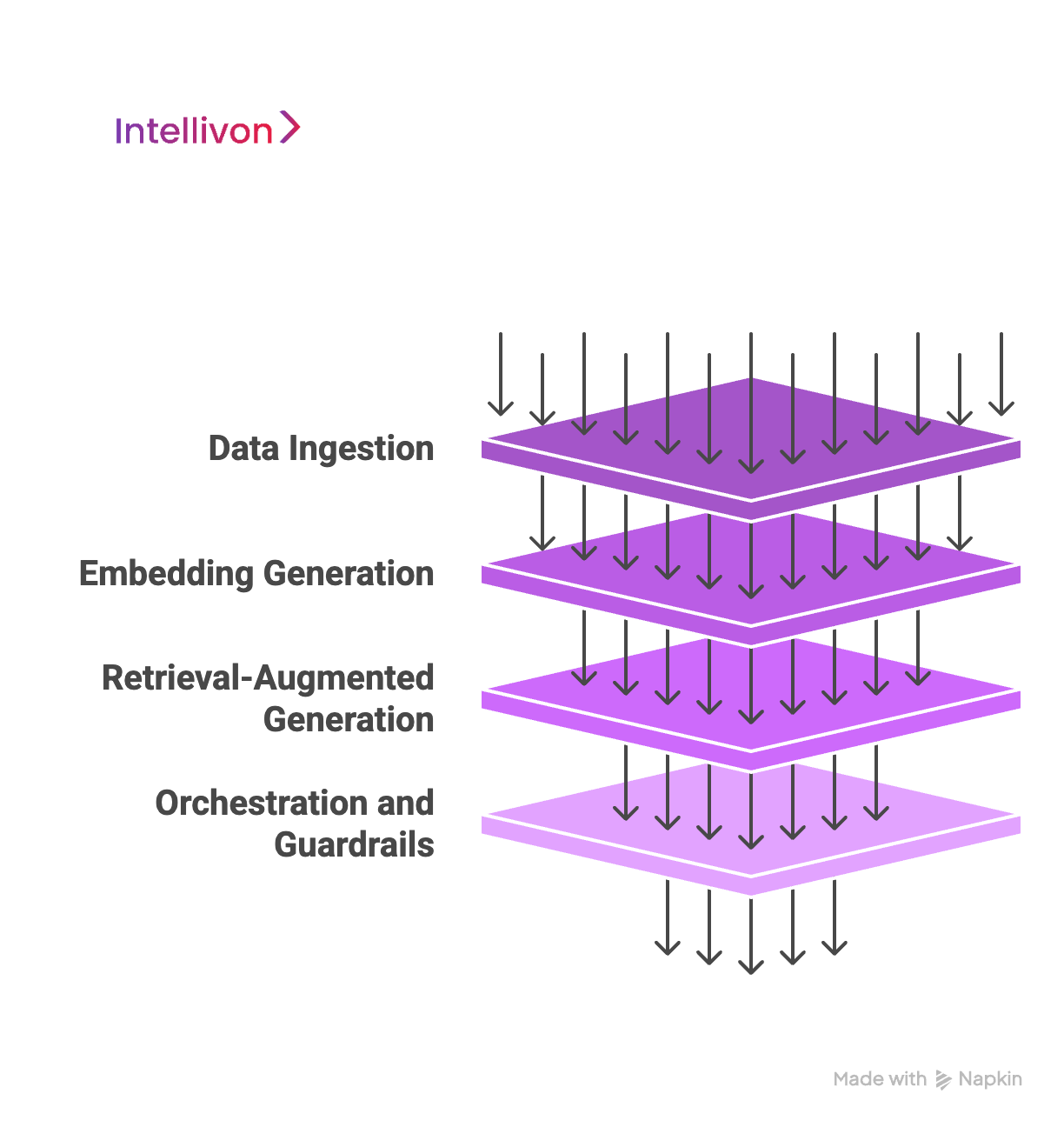
1. Source Systems & Ingestion Layer
Enterprise knowledge doesn’t live in one place. It exists in emails, PDFs, chats, spreadsheets, and portals, often in unstructured and siloed formats.
The ingestion layer gathers and prepares this raw information for processing.
- Unstructured sources include scanned documents, email threads, ticket logs, internal knowledge bases, and legacy web content.
- Extraction tools handle the messy work. They include:
- Apache NiFi automates data flow and large-scale file extraction.
- Airbyte seamlessly connects various platforms and databases.
- LangChain Loaders read specific formats, such as DOCX, PDF, or HTML, with precision.
Next comes preprocessing:
- OCR converts scanned text into readable data.
- Cleaning routines remove clutter like footers or system signatures.
- Chunking breaks documents into small, context-aware blocks.
- Metadata tagging adds helpful context like document type, source, or department.
2. Embedding Generation & Vector Store
Now the system turns chunks of text into semantic embeddings, which are numeric vectors that carry meaning.
This is crucial for contextual retrieval, where understanding matters more than matching keywords.
- LLM-agnostic embeddings (like BERT, Sentence Transformers, or Cohere) are flexible and open-source.
- Proprietary embeddings (like OpenAI’s) offer performance but may lock you into specific tools.
Once generated, vectors are stored in fast-access vector databases:
- FAISS offers blazing speed for high-volume use.
- Weaviate, Qdrant, and Milvus support scalable, cloud-native APIs with rich metadata search.
Each stored vector is linked to its source text, document ID, and context for traceability.
3. Retrieval-Augmented Generation (RAG)
RAG is the brain of the LLM Knowledge system. It bridges static LLMs with dynamic, real-world data.
Here’s how the cycle works:
- User Query: A team member asks a natural language question via a chatbot or internal portal.
- Query Embedding: The question is converted into a semantic vector.
- Vector Search: Matching vectors are fetched from the vector store.
- Prompt Fusion: Retrieved content is assembled into a context-rich prompt.
- LLM Generation: The LLM (e.g., GPT-4, Gemini, or Llama) generates an informed, grounded response.
- Response Output: The final answer is shown, often with citations and source links.
This approach ensures results are based on your data, and not the model’s training set. Prompt engineering refines how content is presented to the LLM, while RAG chaining helps break down complex questions into multi-step logic.
4. Orchestration & Guardrails
This layer ensures everything runs smoothly, securely, and responsibly.
Orchestration tools like LangChain or Semantic Kernel manage:
- Real-time API calls
- Document updates
- Model interaction
Efficiency is boosted with batch queries and parallel pipelines.
Guardrails protect both users and systems. They include:
- Human-in-the-loop workflows for validation or escalation
- Reinforcement tuning based on feedback
- Security controls like encryption, role-based access, and full audit trails
- Monitoring for hallucinations, drift, or failure patterns
An LLM-based Knowledge Retrieval system is a carefully engineered platform that turns enterprise data into real-time intelligence.
LLM-Based Knowledge Retrieval Models: Enterprise Use Cases
As enterprise data grows in volume and complexity, traditional search methods no longer suffice. LLM-based knowledge retrieval models, especially those using Retrieval-Augmented Generation (RAG), offer a way forward. They bring intelligence and context to data access, bridging the gap between what teams need and what systems can deliver.
Below are five impactful, real-world use cases where large enterprises are already gaining measurable value.
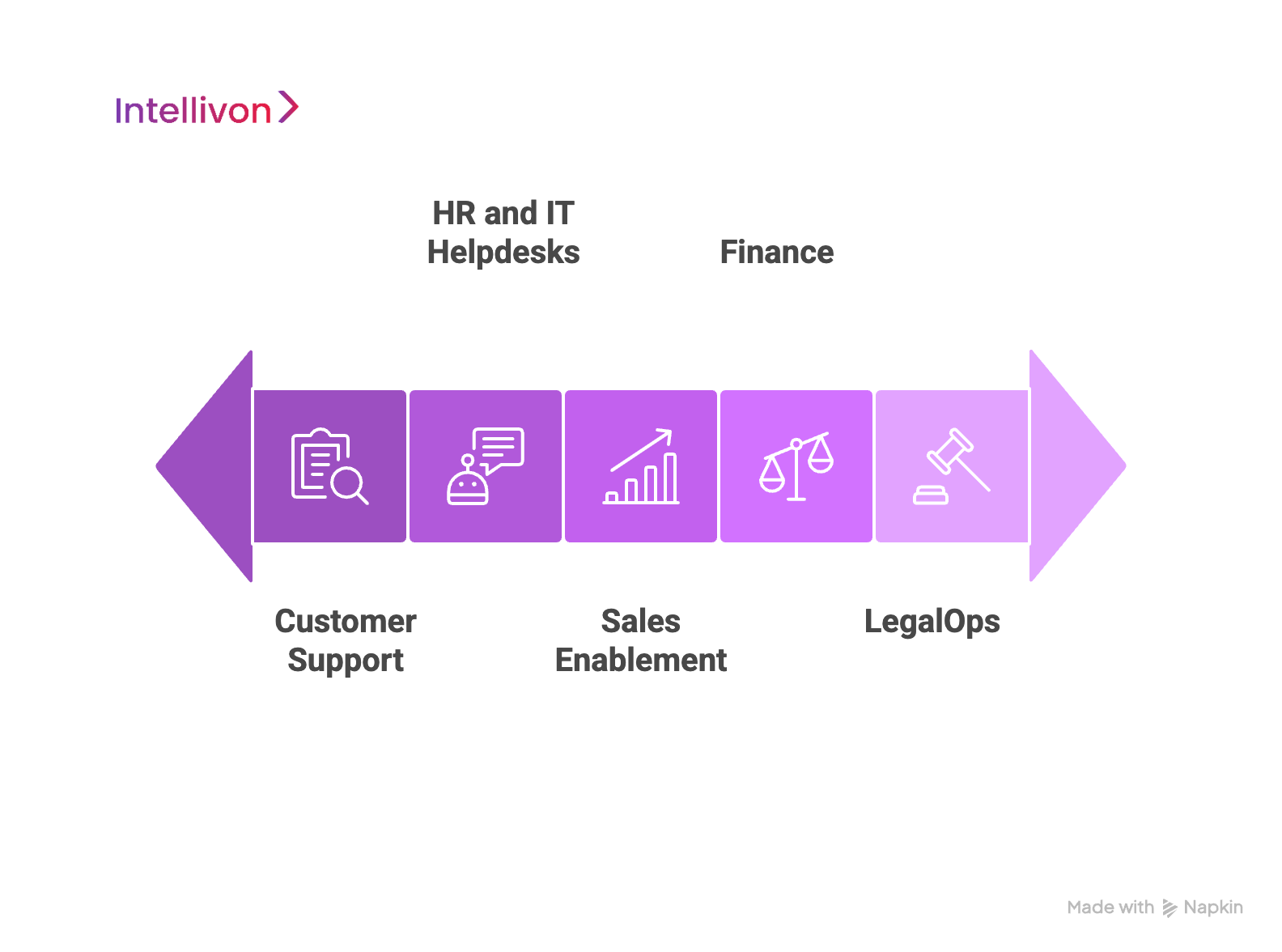
1. LegalOps: Clause Extraction and Risk Detection from Contracts
Legal teams often work with thousands of contracts, each with its own unique format and language. Finding clauses related to renewals, liabilities, or indemnifications is time-consuming and prone to oversight. With LLM-based retrieval, teams can ask natural language questions, such as: “Find indemnity clauses with first-party liability risks.”
The system retrieves exact matches along with the full document context.
Retrieval Type: Semantic. The model understands legal intent, allowing nuanced clause extraction that traditional search tools miss.
2. Customer Support: Instant Ticket Deflection and Resolution
Customer support teams handle repetitive queries daily. Many answers already exist, buried in previous tickets, help articles, or chat logs. LLM Knowledge models interpret intent and recommend responses in real time, often before a ticket reaches a human agent. This means faster resolution and improved customer satisfaction.
Retrieval Type: Hybrid. Combines semantic understanding with keyword precision for maximum accuracy. For instance, platforms like LinkedIn reported a 29% reduction in median issue resolution time using similar approaches.
3. Finance: On-Demand Policy and Audit Insight
Finance and compliance teams frequently need up-to-date information across evolving policies, audit logs, or spending rules. An analyst can now ask: “What’s our capital expenditure threshold this fiscal year?” Or “Show changes in procurement terms over the past six months.”The system searches across multiple sources to provide the most current and relevant information, complete with citations.
Retrieval Type: Semantic. Ideal for interpreting varied policy language across time and systems.
4. HR and IT Helpdesks: 24/7 Internal Knowledge Bots
Internal helpdesks often answer the same questions repeatedly, about PTO policies, onboarding steps, or software access. LLM-powered knowledge bots eliminate this burden. Employees can ask in plain English: “How do I apply for parental leave?” or “Where’s the checklist for onboarding contractors?” The system returns clear, policy-aligned answers instantly.
Retrieval Type: Semantic and similarity-based. The bot pulls from manuals, past tickets, and internal guides to provide consistent, accurate responses.
5. Sales Enablement: Surfacing Winning Content from Past Deals
Sales teams often struggle to locate pitch materials, ROI calculators, or case studies used in previous wins. The right content might exist, but it might be buried deep in shared folders. Now, a rep can ask: “Show me the proposal used for a Fortune 500 logistics client.” Or “Find slides used to win our last healthcare client in the US.” LLM Knowledge models retrieve tailored, proven content that accelerates deal cycles and enhances pitch precision.
Retrieval Type: Semantic. Enables discovery without needing exact filenames or keywords.
Across legal, support, finance, HR, and sales, LLM-based knowledge retrieval systems are enabling fast, context-aware access to the most trusted knowledge, streamlining operations and improving outcomes. At Intellivon, we design these systems with enterprise realities in mind, like security, compliance, scale, and usability. By grounding their outputs in data, LLM models empower teams to make better decisions more quickly.
How We Build LLM-Based Knowledge Retrieval Systems: A Step-by-Step Guide
Building a powerful LLM Knowledge retrieval model isn’t simply about choosing the latest AI model. It’s about designing a system that aligns with your enterprise’s data architecture, compliance requirements, and daily workflows.
At Intellivon, we’ve worked closely with leading organizations to develop scalable, secure, and reliable AI Development services. Based on that experience, here’s a practical five-step framework tailored for CIOs, tech leaders, and innovation stakeholders.
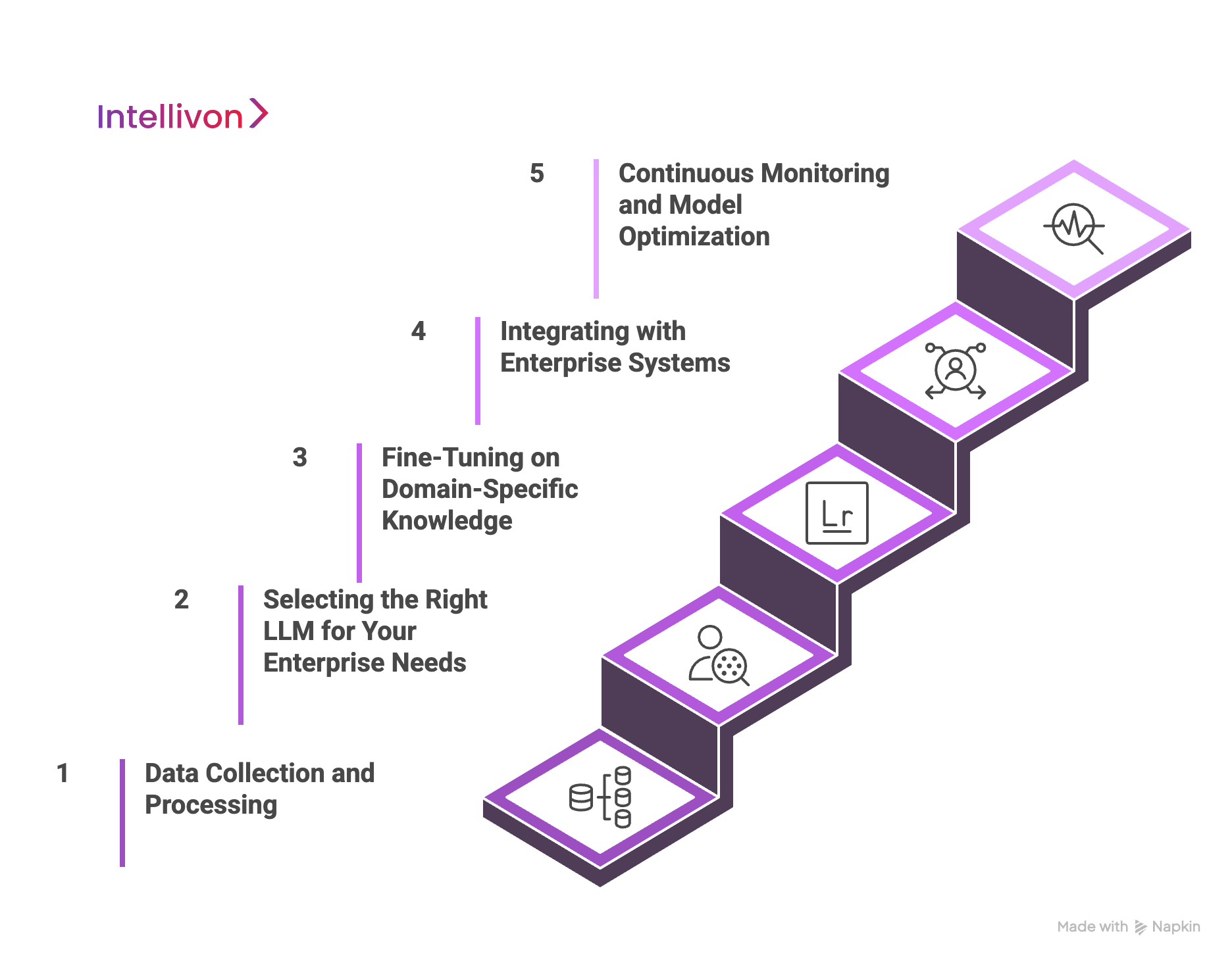
Step 1: Data Collection and Preprocessing
1. Understand Your Data Landscape
Enterprise data exists in structured formats such as spreadsheets and databases, semi-structured forms like XML or JSON, and unstructured content including emails, PDFs, scanned documents, presentations, chat logs, and wikis. We prepare this wide range of content into a usable state, which requires methodical extraction, cleaning, and transformation.
2. Ingest, Clean, and Structure
Organizations must ingest data from various enterprise systems such as CRMs, ERPs, support platforms, file servers, and document management systems. During preprocessing, it’s critical to remove noise such as headers, boilerplate text, duplicates, or irrelevant metadata. For scanned documents and images, OCR should be applied to ensure text extraction. We then normalize formats and enrich data with contextual metadata, which further boosts downstream performance.
3. Chunking for Semantic Search
To enable high-quality semantic search, long-form content must be broken into smaller, context-rich “chunks”, ideally between 200–500 words. Effective chunking improves the precision and relevance of retrieval by preserving the contextual integrity of documents during indexing.
Step 2: Selecting the Right LLM for Your Enterprise Needs
1. Align Model Capabilities with Enterprise Needs
Choosing the right LLM depends on your organization’s scale, compliance obligations, and domain needs. Cloud-hosted models offer scalability and faster integration, while on-premise or private models provide greater control over sensitive data, particularly in finance, healthcare, and legal domains.
2. Evaluate Key Decision Factors
Model selection should account for your operational size, peak usage volumes, and global user base. You’ll also want to assess whether the model supports your industry’s language requirements, such as legal or medical terminology, and if it offers the performance and response time needed to meet your SLAs. An experienced AI partner like Intellivon can help you weigh these variables in line with your infrastructure and long-term goals.
Step 3: Fine-Tuning on Domain-Specific Knowledge
1. Move from General to Enterprise-Specific Intelligence
Off-the-shelf LLMs are trained on broad internet datasets and lack the depth to handle enterprise-specific questions. Fine-tuning addresses this gap by re-training the model using proprietary knowledge, such as internal policies, process documents, contracts, product manuals, and past communication logs, so that it understands your business vocabulary and logic.
2. Zero-Shot vs. Fine-Tuned Models
While zero-shot learning lets a pre-trained model provide answers without retraining, it may struggle with accuracy and context. Fine-tuned models are better suited for high-stakes environments where factual consistency, legal compliance, and brand tone are essential. Though fine-tuning requires more effort upfront, it delivers more dependable results over time.
Step 4: Integrating with Enterprise Systems
1. Connect Where Teams Work
Knowledge retrieval becomes most effective when integrated directly into tools your teams already use, such as Salesforce, SAP, Jira, Zendesk, or SharePoint. APIs and middleware can facilitate this connection, enabling the LLM to interact with your business tools in real-time while accessing the most current information.
2. Ensure Security and Compliance
To operate safely at scale, the system must include role-based access control, audit logging, data encryption, and compliance configurations aligned with frameworks like GDPR, HIPAA, or SOC 2. These features protect sensitive enterprise knowledge while ensuring retrieval is reliable and secure. Intellivon specializes in embedding LLMs into critical business environments with full consideration for governance and risk.
Step 5: Continuous Monitoring and Model Optimization
1. Maintain, Evaluate, and Improve Over Time
Once deployed, your LLM Knowledge system needs to evolve with your organization. Our AI Engineers continuously monitor your model, which helps track query accuracy, latency, user satisfaction, and anomaly patterns. As new documents are generated or business priorities shift, retraining the model and refreshing embeddings ensures continued relevance and utility.
2. Establish Human-in-the-Loop Governance
A structured feedback loop lets employees flag irrelevant or incorrect responses. This feedback is used to refine the model, improve chunking logic, or retrain sections of the system. When combined with human validation pipelines and performance dashboards, this process fosters a cycle of continuous improvement and accountability.
Creating an enterprise-grade LLM Knowledge Retrieval System is a multi-phase journey. At Intellivon, we’ve built these architectures for scale, compliance, and performance, so enterprises don’t just store knowledge, they retrieve and use it when it matters most.
Cost Of Building LLM-Based Knowledge Retrieval Systems
We take a cost-effective approach to building custom LLM-based knowledge retrieval systems for enterprises. Our goal is to deliver high-quality, reliable solutions that fit your needs and stay within your budget. Intellivon focuses on creating smart, scalable systems that work efficiently for your business.
| Component | Description | Estimated Cost (USD) |
| 1. Discovery & Solution Design | Requirements gathering, architecture planning, compliance review | $4,000 – $8,000 |
| 2. Data Ingestion & Preprocessing | Connecting to SharePoint, CRMs, file systems; OCR; data cleaning & chunking | $8,000 – $15,000 |
| 3. Embedding Generation & Vector DB | Embedding pipelines (OpenAI/Cohere/GTR); FAISS, Weaviate, or Qdrant setup | $5,000 – $10,000 |
| 4. LLM Integration (API or Self-Hosted) | Connecting OpenAI, Claude, or Llama2; Prompt engineering; response formatting | $8,000 – $12,000 |
| 5. Retrieval-Augmented Generation (RAG) | Full RAG pipeline setup—embedding, retrieval, prompt injection, source mapping | $10,000 – $15,000 |
| 6. Fine-Tuning / Domain Adaptation | Optional. Training LLM on enterprise-specific docs (compliance, policy, legal) | $6,000 – $12,000 |
| 7. Frontend UX / Chatbot Interface | Basic UI layer (portal or Slack/MS Teams bot); user auth; source citation UI | $3,000 – $6,000 |
| 8. System Orchestration & APIs | LangChain/Semantic Kernel orchestration; secure API layer; logging | $3,000 – $6,000 |
| 9. Testing & QA | Functional, performance, and security testing | $2,000 – $4,000 |
| 10. Hosting & Infrastructure (6–12 mo) | Vector DB + LLM API usage + serverless functions (Azure, AWS, or GCP) | $4,000 – $8,000 |
| 11. Support & Monitoring Setup | Basic analytics dashboard, alerting, human-in-the-loop feedback channels | $2,000 – $4,000 |
| 12. Documentation & Training | End-user guides, admin manuals, internal training for ops or IT | $1,000 – $2,000 |
Total Estimated Range: $52,000 – $98,000
This is just an estimate of the cost to build LLM-based knowledge Retrieval models for large enterprises. Actual costs may vary depending on several factors. To determine the cost of building a similar model for your enterprise, schedule a complimentary 30-minute strategy call with Intellivon, and we will provide you with a tailored estimate.
Overcoming Common Challenges in LLM Knowledge Retrieval Models
While LLM knowledge retrieval systems are revolutionizing enterprise intelligence, deploying them at scale presents real challenges. These range from data freshness and hallucinations to explainability and domain relevance.
At Intellivon, we tackle these issues head-on with practical, adaptive solutions that prioritize enterprise integrity and performance.
1. Stale or Incomplete Knowledge
Challenge:
Most LLMs are trained on static datasets that don’t reflect recent developments or internal business changes. This creates a gap between what the model “knows” and what your team needs to know in real-time, making it unreliable for decisions tied to fast-moving data, evolving policies, or regulatory updates.
Our Solution:
We implement Retrieval-Augmented Generation (RAG) architectures that dynamically retrieve up-to-date knowledge from your enterprise content, regardless of its location. This ensures your LLM responses are always grounded in current, domain-specific data, rather than outdated pretraining.
2. Hallucinations and Inaccurate Responses
Challenge:
LLMs can sometimes generate content that sounds accurate but is factually incorrect. These “hallucinations” can be dangerous in high-stakes industries such as healthcare, finance, or legal where factual precision is critical.
Our Solution:
Intellivon’s approach ensures every answer is source-grounded and verifiable. We use context-aware RAG pipelines that cite exact documents and passages, and apply filters like source attribution and self-verification to reduce hallucinations and improve trust.
3. Inconsistent or Conflicting Knowledge
Challenge:
Enterprise data is fragmented and stored in different formats, systems, and departments. When a model pulls from these sources, it can return conflicting information, confusing users or causing operational delays.
Our Solution:
We use logic-based fusion and knowledge-aware filtering to resolve overlapping content and prioritize authoritative sources. Our orchestration layer reconciles inconsistencies so that users get unified, conflict-free answers, even across complex datasets.
4. Low Context Quality
Challenge:
Even the best LLM will fail if the context it receives is irrelevant or poorly structured. Weak retrieval pipelines can surface noisy or off-topic information, degrading output quality and user experience.
Our Solution:
Our systems use hybrid semantic retrieval to improve both recall and precision. This means your LLM gets the most relevant, context-rich input, thereby optimizing answer quality, reducing noise, and enhancing decision-making.
5. Limited Domain Expertise
Challenge:
Off-the-shelf models struggle with enterprise-specific language, workflows, or regulatory terminology. Without adaptation, they fail to deliver relevant or compliant responses for specialized queries.
Our Solution:
Intellivon fine-tunes LLMs using your internal manuals, policies, and historical documents. This domain-specific adaptation ensures the model understands your business language and generates accurate, role-aware responses.
Lack of Explainability and Traceability
Challenge:
In enterprise settings, it’s not enough to answer. You need to show where it came from. Without explainability, teams can’t audit outputs or trust the system in compliance-heavy scenarios.
Our Solution:
Our LLM knowledge systems are built with source-level attribution. Every answer links back to the document, database, or message it came from, giving users and auditors full visibility into how the answer was generated.
How To Future-Proof Your LLM Knowledge Retrieval Model
At Intellivon, we build systems that are prepared for tomorrow. Our future-proofing approach is based on three pillars: scalability and integration, advanced optimization, and readiness for emerging technologies. This ensures your enterprise stays ahead as AI capabilities and business demands evolve.
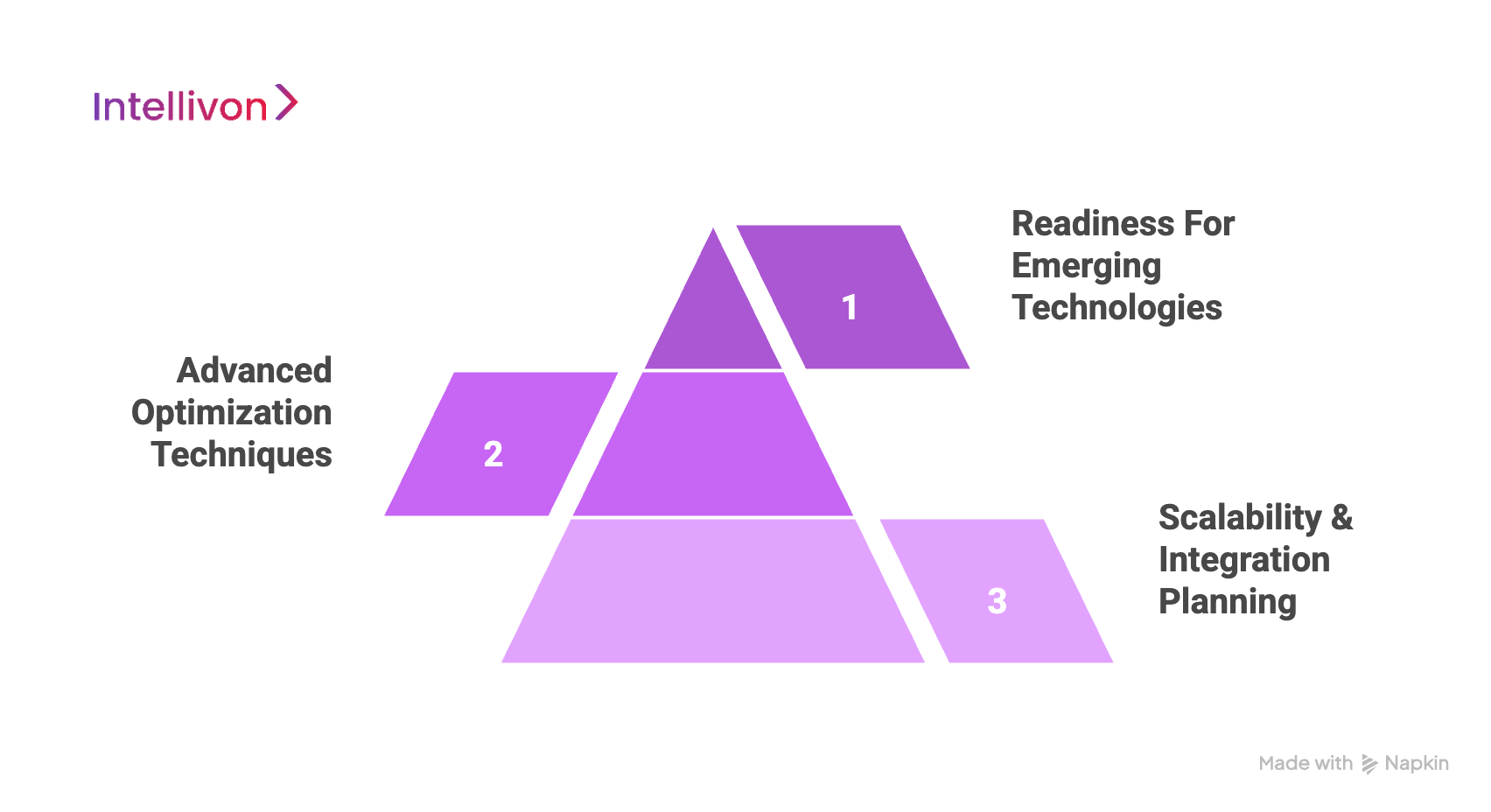
1. Scalability and Integration Planning
1. Elastic Cloud Infrastructure
We deploy on cloud-native platforms that grow with your business. Whether you’re scaling from hundreds to thousands of users or managing exponential growth in document volume, our infrastructure flexes to maintain high-speed performance and uptime.
2. Workplace Tool Integrations
We integrate the knowledge engine into your team’s daily tools, like Slack, Confluence, SharePoint, Zendesk, and Google Workspace. This enables employees to access trusted knowledge without switching platforms or interrupting their workflow.
3. API-First and Future-Proof Connectivity
Our architecture is built using API-first principles. That means your system connects smoothly to CRMs, ERPs, and any third-party platform, whether legacy or next-gen. As new systems emerge, integrating them into your LLM model is seamless.
4. Versioning and Change Auditing
We implement robust version control across all components, from data ingestion pipelines to retrieval prompts. Every change is tracked, logged, and reversible. This ensures compliance, traceability, and confidence in ongoing system updates.
2. Advanced Optimization Techniques
1. Smart Caching for Frequent Queries
We reduce infrastructure costs and latency by caching answers to recurring questions. This ensures instant responses for FAQs and reduces unnecessary LLM computation, saving both time and budget.
2. Dynamic Model Routing
Not all queries need the same level of AI power. We route simple lookups to lightweight models and direct complex questions to larger LLMs. This keeps response times fast while balancing system cost and efficiency.
3. Lightweight Retrieval for Everyday Use
For routine knowledge tasks, such as policy checks or IT FAQs, we use high-speed retrieval layers that bypass the need for generative responses. This increases throughput and frees up LLM resources for critical tasks.
4. Real-Time Monitoring and Tuning
We embed performance dashboards that track latency, accuracy, query success, and user satisfaction. These insights help our teams fine-tune the system proactively, ensuring it stays fast and reliable as usage scales.
3. Readiness for Emerging Technologies
1. Multimodal Compatibility
We’re preparing your knowledge systems to support text, tables, audio, images, and video, all within one retrieval framework. This unlocks future use cases in design, legal, HR, and field support.
2. Autonomous Knowledge Organization
Our models can self-organize information by tagging, summarizing, and clustering content without manual input. This makes your knowledge base smarter over time, reducing noise and enhancing relevance.
3. Predictive Intelligence for Knowledge Surfacing
By analyzing user behavior and historical queries, our systems begin to anticipate what users need. This predictive capability allows teams to make faster decisions, even before they think to ask.
4. Edge Support for Secure Environments
For industries with strict security and latency demands, we support local inference. Our systems can operate fully on the edge, ensuring data privacy and fast response times in air-gapped or offline deployments.
From scaling with your organization to adapting to new technologies, Intellivon ensures your LLM knowledge retrieval system grows smarter, faster, and more secure over time.
Conclusion
LLM-based knowledge retrieval systems transform how enterprises access and apply information, boosting productivity, accelerating decisions, and enhancing accuracy across departments.
By enabling natural language queries, grounding answers in real-time data, and scaling effortlessly with your needs, these systems offer a smarter, faster, and more secure way to manage knowledge.
Is Your Enterprise Ready to Operationalize Its LLM Knowledge?
With over 11 years of experience in AI for enterprises and 500+ successful implementations across industries, Intellivon is your trusted partner in building intelligent, scalable LLM Knowledge Retrieval Models. From transforming unstructured data into instantly accessible insights to empowering every department with real-time, contextual answers, we help enterprises turn knowledge chaos into clarity.
What Makes Intellivon the Right Partner?
- Tailored LLM Architectures
We design and deploy RAG-powered systems tailored to your industry, data formats, and compliance needs. - Seamless Enterprise Integration
Our models plug into your existing CRMs, ERPs, DMSs, and internal tools, ensuring knowledge flows securely across your organization without disrupting daily operations. - Guaranteed Performance SLAs
We commit to measurable response times, search accuracy, and uptime, so your teams always get trusted answers, fast. - 6-Month ROI Commitment
Our AI solutions are engineered for business outcomes. From faster decision-making to streamlined onboarding, we help you unlock tangible ROI in under 6 months. - Human-Centric Deployment & Support
We offer multilingual onboarding, training, and dedicated customer success managers to ensure adoption, satisfaction, and value realization. - Continuous Optimization
Our managed services include proactive tuning, new content ingestion, and regular model performance reviews to keep your system sharp and relevant.
Want to see your enterprise knowledge work as smart as your best employee? Let’s build your LLM knowledge retrieval system together.
Book a discovery call with our AI consultants today and get:
- A full audit of your enterprise knowledge landscape
- Integration-readiness and AI maturity assessment
- Custom use-case roadmap and implementation plan
- ROI forecast tailored to your specific operations
FAQ’s
Q1. What is LLM Knowledge in enterprise AI?
LLM Knowledge refers to the understanding and contextual reasoning that Large Language Models (LLMs) apply when retrieving or generating information. In an enterprise context, it means using LLMs to access and synthesize knowledge from internal systems, like documents, emails, CRMs, or wikis, to deliver accurate, natural language answers that support decision-making, operations, and customer support.
Q2. Can LLMs be fine-tuned on proprietary enterprise data?
Yes, LLMs can be fine-tuned using your enterprise’s proprietary data. This process involves training the model on domain-specific documents like policies, manuals, contracts, and customer queries. Fine-tuning enhances response accuracy, aligns the model with company-specific terminology, and reduces the risk of hallucinations, making the system more reliable for internal users.
Q3. What are the best tools for building LLM knowledge systems?
The most effective tools depend on your architecture, but typically include LangChain or LlamaIndex for orchestration, FAISS, Weaviate, or Qdrant as vector databases, Apache NiFi or Airbyte for data ingestion, OpenAI, Cohere, or open-source models (like LLaMA or Mistral) for language generation, OCR tools for scanned content, and embedding models (e.g., BERT, Sentence Transformers) for semantic understanding. Together, they form a robust Retrieval-Augmented Generation (RAG) system.
Q4. How secure are enterprise-grade vector databases?
Enterprise-grade vector databases like Weaviate, Qdrant, and Pinecone are built with security in mind. They support encryption at rest and in transit, access controls, API authentication, and role-based permissions. When deployed on-premise or in a private cloud, they offer additional layers of control, making them suitable for storing sensitive enterprise data.
Q5. What’s the ROI of deploying an LLM Knowledge system in an enterprise?
Enterprises typically see ROI within 3 to 6 months, thanks to faster decision-making, quicker customer support, reduced onboarding time, and improved compliance. When integrated across teams, LLM Knowledge systems often deliver 2x to 5x returns through greater productivity and efficiency.