

From customer service bots to internal copilots, LLMs are showing up in workflows everywhere. But as fast as adoption is rising, cracks are starting to show. Behind the impressive demos, many organizations are discovering something troubling: these models are powerful, but unreliable when it matters most. More than 44% of IT leaders said that security and data privacy are major barriers to wider and more dependable LLM adoption.
For enterprises dealing with sensitive data, compliance needs, and fast-changing internal knowledge, traditional LLMs are not enough. Data leaks from misuse or vulnerabilities in enterprise LLMs cost organizations an average of $4.35 million per breach. The compounding impact is evident in real cases, like Air Canada facing fines because its chatbot made up non-existent policies. That’s why a shift is happening. Instead of relying solely on standalone LLMs, companies are now turning to Retrieval-Augmented Generation (RAG) to make their AI systems more accurate, explainable, and grounded in their own knowledge base. RAG enhances LLMs by letting them pull in real-time data, providing more context-aware, real-time answers.
When it comes to implementing RAG into enterprise LLMs, Intellivon stands out as the partner you can rely on. With real-world experience and a hands-on approach, we help businesses seamlessly integrate RAG for better, more effective results. In this blog, we’ll show you how we implement enterprise-ready AI RAG stacks, our best practices and how we overcome enterprise RAG challenges.

Why Enterprises Are Moving Toward RAG for LLM Enhancement
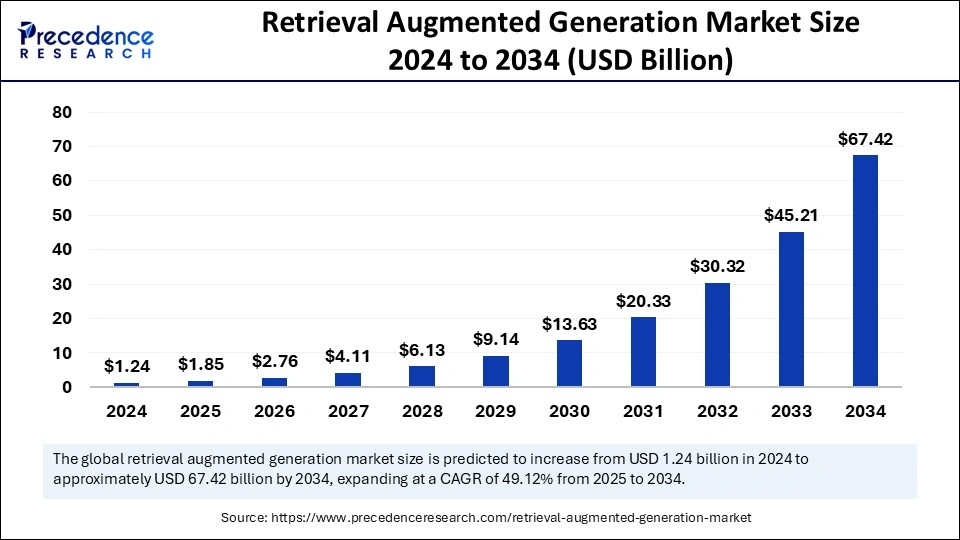
The global RAG market is valued at $1.85 billion in 2025 and is expected to grow to $67.4–74.5 billion by 2034, with a massive 49–50% CAGR, per Precedence Research reports. This astronomical adoption rate is driven by the growing demand for scalable, accurate, and context-aware AI solutions, particularly in regulated sectors like finance, healthcare, and knowledge management.
Key Takeaways:
- In 2025, over 73% of RAG implementations are within large enterprises, reflecting confidence in its scalability, security, and performance.
- Compared to standard LLMs, RAG reduces hallucinated (incorrect) AI outputs by 70–90%, leading to more accurate and reliable enterprise AI interactions.
- Organizations using RAG report 65–85% higher user trust in AI outputs and 40–60% fewer factual corrections.
- Enterprises also experience a 40% decrease in customer service response times and a 30% boost in decision-making efficiency with RAG-powered AI.
- RAG speeds up time-to-insight in legal, compliance, and research areas, improving onboarding and revenue generation by delivering faster, more context-rich intelligence.
- Enterprises in regulated industries, like banking and pharmaceuticals, report better risk and compliance alignment and stronger audit readiness, thanks to traceable, source-backed answers.
Addressing Limitations of Traditional LLMs
Traditional LLMs have changed how we interact with technology. Their ability to understand and generate human-like language is groundbreaking. Yet, when enterprises attempt to apply them at scale, the cracks begin to show. These models often fall short in delivering the accuracy, adaptability, and transparency that modern businesses demand.
This is exactly why RAG for enterprises has become so important. It fills the gaps LLMs can’t cover alone.
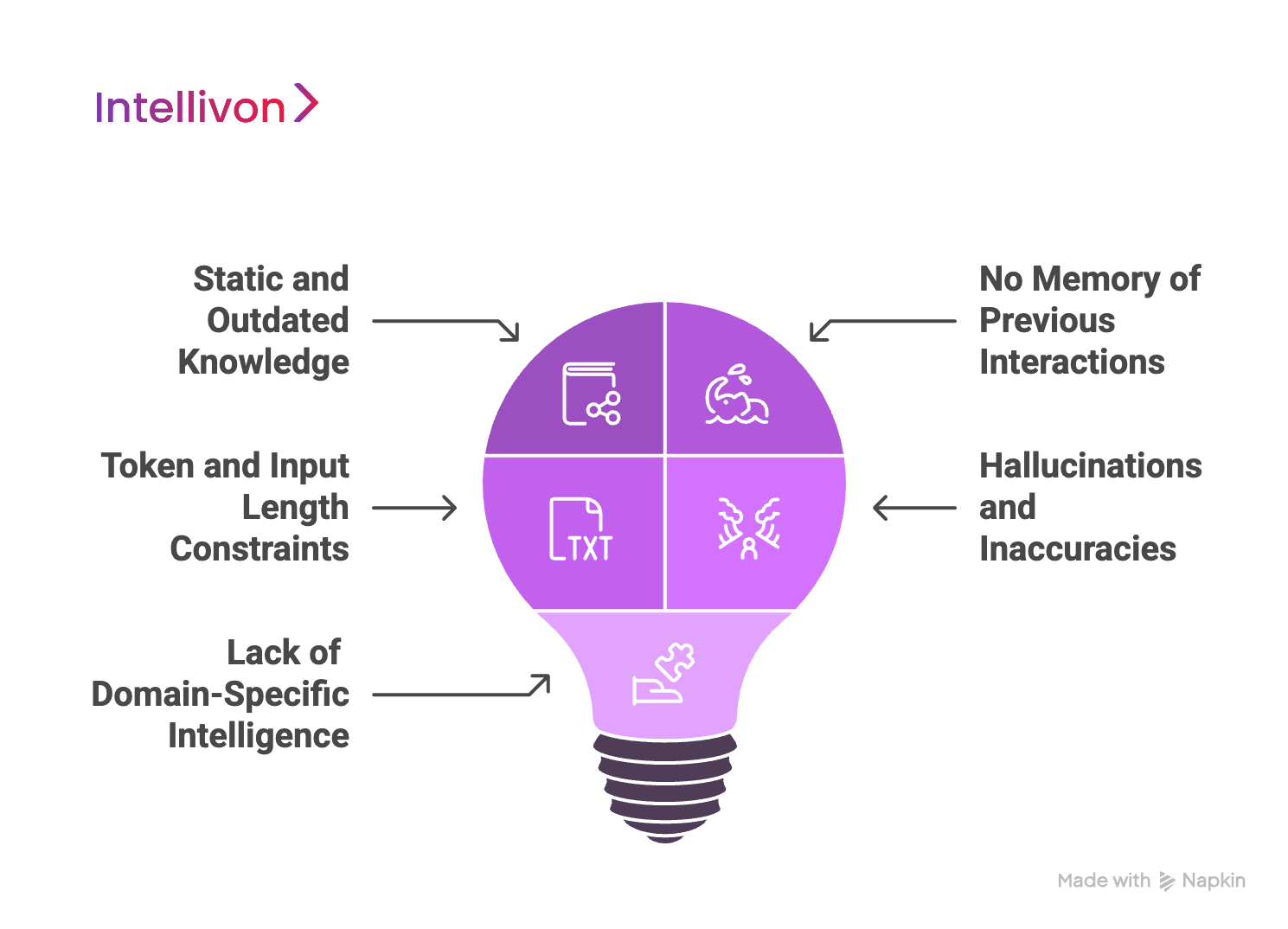
1. Static and Outdated Knowledge
Traditional LLMs are trained on a large dataset up to a certain cutoff point. Once deployed, they operate with no ability to access or learn from new information. In industries like finance, healthcare, or law, where things change daily, this becomes a serious problem. The model may confidently give answers that are outdated, misaligned with company policy, or no longer legally accurate. Enterprises need models that evolve with their knowledge. LLMs alone simply can’t provide that.
2. No Memory of Previous Interactions
Another key limitation is the lack of memory. Traditional LLMs treat each interaction as isolated. They don’t recall past conversations, which means they can’t build context across sessions. For enterprise applications like internal helpdesks or customer support assistants, this results in inconsistent responses and a frustrating user experience. It also prevents any long-term learning from taking place, which limits personalization and productivity gains.
3. Token and Input Length Constraints
LLMs can only process a limited number of tokens, or words, at a time. For enterprises, this restricts the AI’s ability to handle long documents like contracts, compliance manuals, or technical guides. It also means the model might miss key context buried deeper in the input. The result? Answers that are incomplete, misleading, or oversimplified.
4. Hallucinations and Inaccuracies
Perhaps the most well-known flaw of LLMs is hallucination. They can generate information that sounds right but is completely false. Since they don’t fact-check or pull from verified sources, their answers are based solely on patterns in training data. For enterprises, this is a legal and reputational risk.
5. Lack of Domain-Specific Intelligence
Because LLMs are trained on internet-scale data, they inherit the biases of the web. They also struggle with niche topics unless specifically fine-tuned. This creates challenges in specialized industries where accuracy and sensitivity are crucial.
Traditional LLMs have their strengths, but they’re not built for enterprise-grade intelligence. That’s where RAG for enterprises offers a powerful solution, helping businesses overcome these limitations with real-time, context-aware, and reliable AI output.
Why RAG Is a Game Changer for Enterprise LLMs
Enterprises need truth, context, and accountability from their search queries. That’s where RAG changes everything. Unlike traditional LLMs that rely solely on pre-trained knowledge, RAG connects live, relevant information to every generated response. It retrieves facts from enterprise-approved sources before generating an answer, giving your AI system the power to be both smart and grounded.
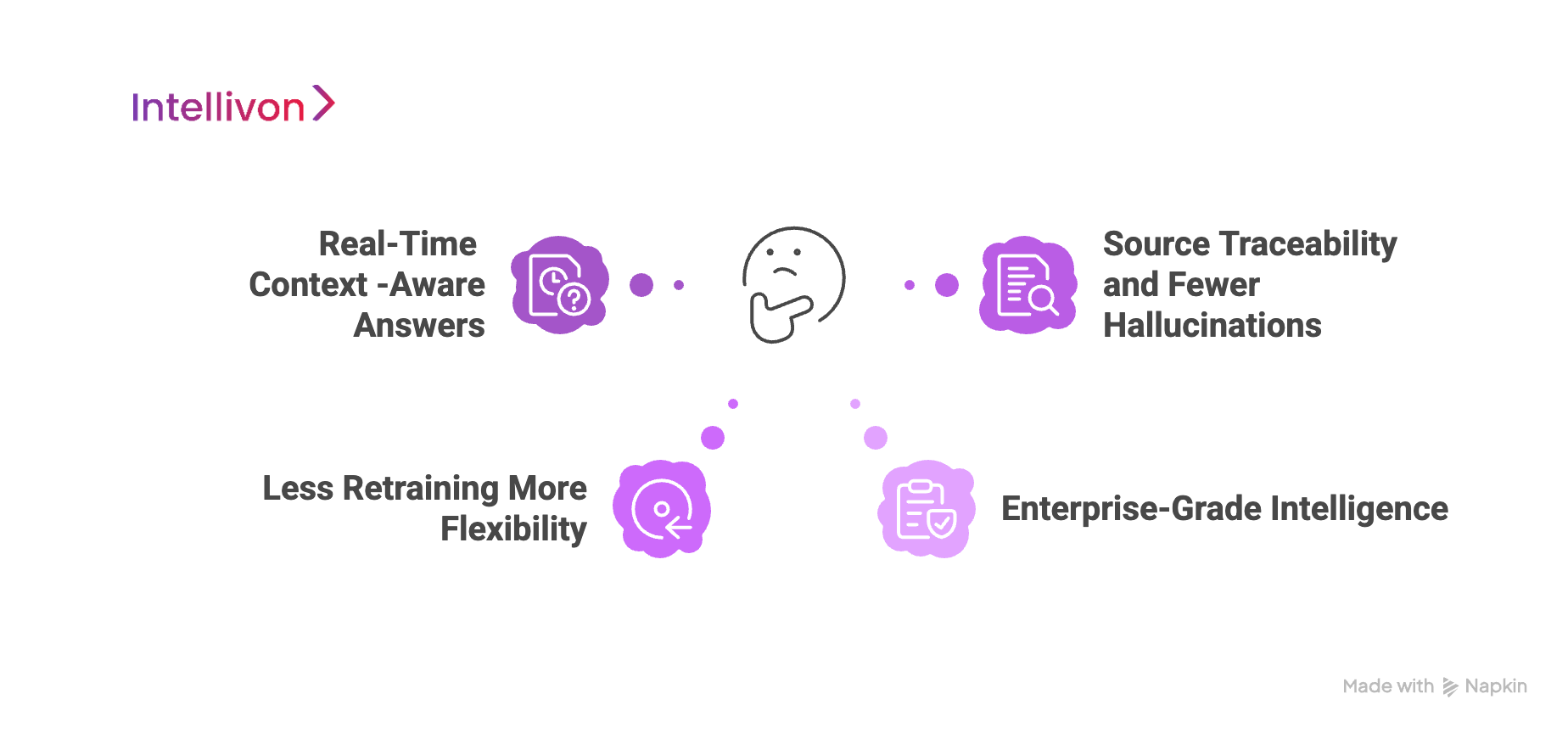
1. Real-Time, Context-Aware Answers
One of the biggest advantages of RAG for enterprises is its ability to stay current. Rather than pulling from static data, RAG systems fetch the most recent and relevant content from internal documents, databases, or even websites. This means responses are tailored to what’s true right now, not just what was true during training.
This feature is especially critical in industries where knowledge changes rapidly. Whether it’s an updated HR policy, a revised product spec sheet, or new compliance regulations, RAG keeps your AI in sync with reality.
2. Source Traceability and Fewer Hallucinations
RAG goes over the entire guesswork and retrieves reliable information. Every answer is backed by a document, file, or snippet that can be traced and verified. This makes it dramatically less prone to hallucinations compared to standalone LLMs.
Enterprises benefit from this transparency. When employees or customers ask questions, the system can show where the information came from. That builds trust and simplifies audit trails, particularly in sectors such as finance, legal, or healthcare.
3. Less Retraining, More Flexibility
Fine-tuning an LLM can be time-consuming and expensive. And each time your internal knowledge changes, you’d need to repeat that process.
RAG offers a smarter path. By separating knowledge retrieval from generation, you can simply update your knowledge base, with no retraining needed. The model dynamically retrieves the most relevant content when needed. This leads to faster updates, reduced costs, and greater adaptability.
4. Enterprise-Grade Intelligence
From compliance bots to AI-powered research assistants, enterprises need AI that works within their real-world constraints. RAG makes it possible. It adds the missing layer of control and context that pure LLMs lack.
Legal teams can rely on it to reference only approved documentation. Customer support can give accurate product answers pulled from internal manuals. Executives can query business reports with confidence in the source.
RAG for enterprises bridges the gap between LLM power and enterprise precision. It ensures that your AI is as articulate as it is accountable.
Real World Industry Use Cases of RAG-Integrated LLMs
Enterprises across industries are reimagining what’s possible with AI by pairing LLMs with RAG. This powerful combo bridges the gap between raw language fluency and fact-grounded decision-making. Here’s how RAG for enterprises is driving real impact across sectors, from finance to healthcare and beyond.
1. Healthcare
Healthcare is one of the most information-rich yet regulated industries. RAG-integrated LLMs are helping bridge the gap between clinical expertise and digital tools.
A. Clinical Decision Support
Doctors and nurses use AI assistants powered by RAG to retrieve relevant guidelines, clinical trial summaries, and patient history in real time, without risking hallucinated advice.
B. Medical Coding and Billing Automation
With RAG, systems can accurately match clinical notes to ICD-10 or CPT codes by referencing up-to-date databases and insurance rules, improving accuracy and speed.
C. Patient Support Chatbots
AI bots enhanced with RAG provide accurate, traceable answers to patient FAQs by pulling from approved care documentation, reducing the risk of misinformation.
Example: Nuance (a Microsoft company)
Nuance’s DAX Copilot leverages retrieval-augmented methods to create clinical summaries and reduce physician workload while integrating with EHR systems.
2. Financial Services
Banks and financial institutions require both precision and compliance. RAG is helping AI systems stay accurate and auditable.
A. Regulatory Compliance Assistance
AI copilots can retrieve real-time updates from internal policy documents, FATF guidelines, or SEC rules, thereby reducing the manual effort needed by compliance teams.
B. Personalized Financial Advisory
RAG helps generate tailored investment advice by retrieving a client’s portfolio history, market data, and firm-specific financial instruments.
C. Risk Assessment Automation
Underwriting and credit analysts use RAG-based systems to extract and analyze customer risk profiles using internal credit policies and historical case data.
Example: JPMorgan Chase
JPMorgan has developed internal AI copilots that use retrieval-enhanced models to support financial analysts and legal teams with regulatory compliance and portfolio assessments.
3. Legal and Contract Management
In legal environments, traceability and accuracy are non-negotiable. RAG makes legal AI both smarter and safer.
A. Case Law Research
Legal researchers can query RAG-powered LLMs to pull summaries from thousands of past cases and statutes, saving hours of manual work.
B. Contract Review and Analysis
RAG enables AI to highlight risks, inconsistencies, and missing clauses in contracts by comparing them to internal templates and regulatory standards.
C. Litigation Support
Law firms use RAG-enhanced tools to extract relevant precedents, expert testimony, or document references from internal databases.
Example: Harvey AI (partnered with Allen & Overy)
Harvey AI uses a RAG architecture to assist lawyers with contract review, legal research, and litigation support, helping them navigate complex legal databases.
4. Retail and E-Commerce
Retailers are using RAG to enhance customer experience and streamline backend operations.
A. Intelligent Product Search
By retrieving structured data like specs, inventory, and reviews, RAG improves search relevance on e-commerce platforms.
B. Customer Support Assistants
Support bots can access warranty terms, order history, or shipping policies in real-time, providing accurate, human-like responses.
C. Supply Chain Optimization
AI tools integrated with RAG retrieve supplier contracts, real-time inventory, and shipping updates to make smarter logistics decisions.
Example: Shopify
Shopify uses retrieval-augmented models in its AI assistant to help merchants answer platform-specific questions by pulling from documentation, inventory, and account data.
5. Manufacturing
Manufacturers rely on RAG to optimize maintenance, training, and safety operations.
A. Equipment Troubleshooting
Technicians use RAG-powered assistants to retrieve fault diagnostics from manuals, logs, and maintenance records on the factory floor.
B. Compliance and Safety Guidance
RAG helps generate workplace safety checklists and compliance documentation tailored to machine type, location, and local regulations.
C. Employee Training and SOP Access
AI assistants retrieve step-by-step procedures and video manuals from internal training libraries to support just-in-time learning.
Example: Siemens
Siemens has piloted retrieval-augmented LLM systems in its smart factory environments to assist technicians with real-time maintenance documentation and safety protocols
6. Education and Research
Institutions are using RAG to personalize learning and streamline academic workflows.
A. Automated Literature Review
Researchers query RAG-based systems to find relevant studies, datasets, or historical theories, saving significant time.
B. AI Tutoring Assistants
Educational platforms use RAG to help students access updated academic resources and policy-compliant responses in real-time.
C. Grant and Policy Writing Support
RAG helps university staff draft proposals or policy documents by pulling relevant funding criteria and institutional history.
Example: OpenAI + Arizona State University
ASU is piloting ChatGPT Enterprise with retrieval-based features to help students and faculty access internal syllabi, research guidelines, and administrative policies.
Across industries, RAG for enterprises is transforming how work gets done. By grounding outputs in trusted data, enterprises are turning LLMs into tools that are not just fluent, but functional.
How RAG Works in Enterprise LLMs
LLMs are excellent at generating fluent responses. But on their own, they lack up-to-date or domain-specific knowledge. That’s where RAG makes a huge difference, especially for enterprise applications that require precision, context, and transparency. Let’s break down how RAG for enterprises actually works.
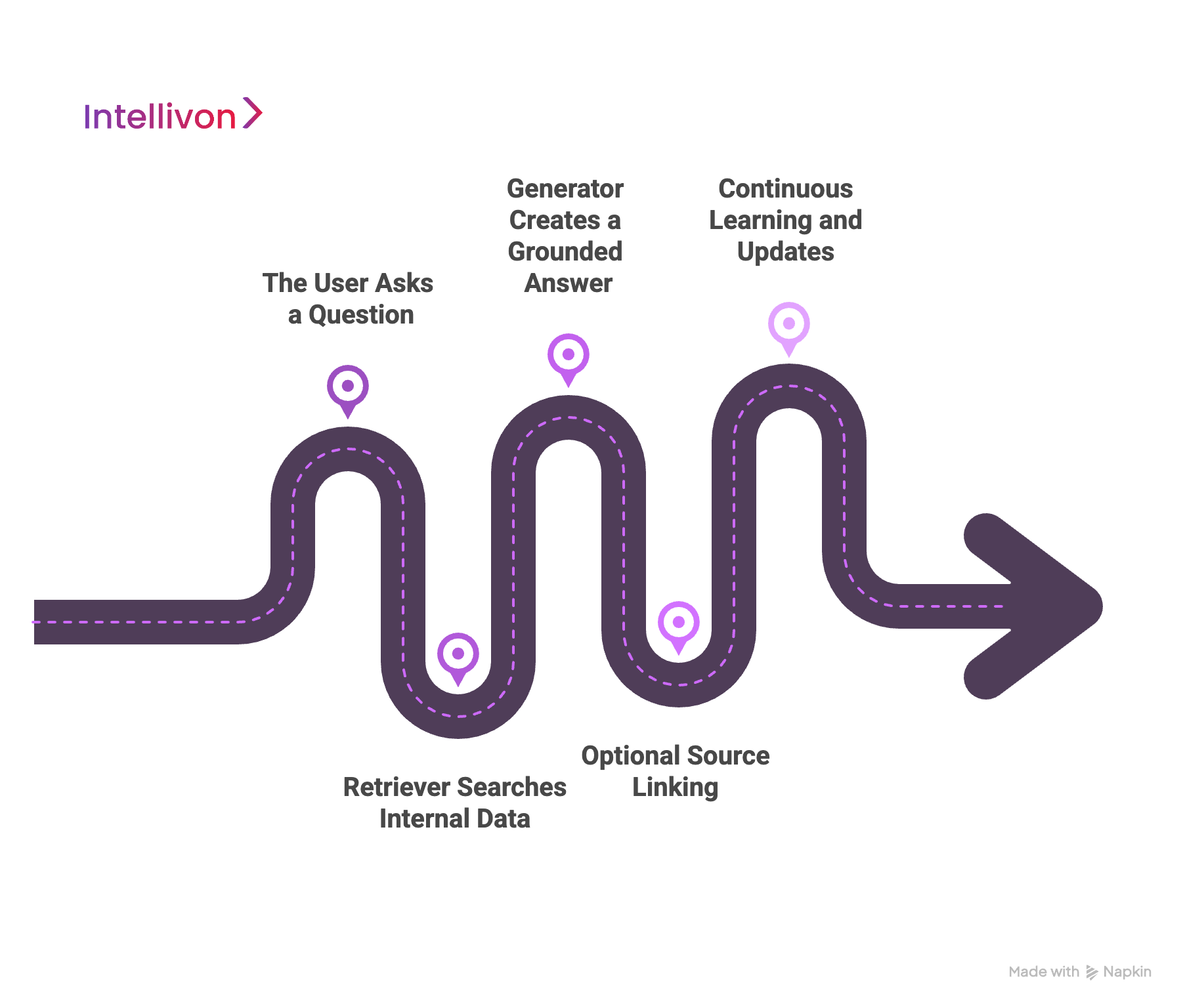
Step 1: The User Asks a Question
The process starts when a user inputs a query. This could be typed into a chatbot, internal tool, or AI copilot. For example, someone might ask, “What’s our refund policy for enterprise accounts in Europe?”
Step 2: Retriever Searches Internal Data
Instead of letting the LLM answer blindly, the RAG system first uses a retriever. This component searches across trusted internal sources like PDFs, policy documents, databases, and wikis. It identifies the most relevant content, often using vector search to match the user’s intent with enterprise data.
This ensures that only the most accurate, recent, and permission-approved information is considered.
Step 3: Generator Creates a Grounded Answer
Now the LLM steps in. But instead of guessing, it reads the retrieved documents and builds a response based on them. The result is a natural-sounding answer that’s grounded in real company knowledge.
For example, the LLM might say:
“According to the policy updated in March 2024, enterprise customers in the EU are eligible for full refunds within 30 days.”
The key? The answer is not hallucinated. It’s based on actual company documentation.
Step 4: Optional Source Linking
To build trust, many RAG systems include references or citations. The AI can show exactly which file or section it pulled the information from. This helps users verify accuracy and improves auditability.
Step 5: Continuous Learning and Updates
Enterprise RAG pipelines often update on a schedule, daily, weekly, or in real time. This ensures that your AI tools are always referencing the latest knowledge, without needing to retrain the model itself.
By combining smart retrieval with powerful generation, RAG for enterprises creates a system that is intelligent and dependable.
Technical Architecture Behind a Scalable Enterprise RAG System
Building a scalable RAG system for an enterprise involves careful planning, robust infrastructure, and the right tools to ensure performance, accuracy, and compliance. Let’s explore the key components of a successful architecture for RAG for enterprises.
1. Vectorization and Embedding Strategies
The foundation of any RAG system is the ability to understand enterprise data. To do this, text must first be converted into vectors, which are mathematical representations of meaning. This process is called embedding.
Enterprise-grade RAG systems use advanced embedding models like OpenAI’s Ada, Cohere, or open-source alternatives like Instructor-XL. These embeddings allow the system to measure how semantically close a document is to a user’s query.
However, not all embeddings are created equal. Enterprises often need to fine-tune these models using their domain-specific terminology. This improves accuracy when users ask technical or internal questions.
2. Document Chunking and Metadata Tagging
Enterprise documents are usually long and complex. Feeding an entire 100-page PDF into an AI system is inefficient and often useless.
That’s why documents are broken into smaller parts, called chunks. These might be split by paragraph, section, or logical breaks. The ideal chunk size balances completeness with searchability, often between 100–300 words.
Each chunk is then enriched with metadata such as:
- Document title
- Department (HR, legal, sales)
- Creation date
- Access level (public/internal/confidential)
This tagging makes it easier for the retriever to filter and prioritize the right pieces of content.
3. Hybrid Search and Ranking Models
A smart retrieval system is at the heart of a performant RAG pipeline. Semantic search, powered by vector similarity, helps match user intent. But it’s often combined with keyword-based search to improve precision.
This hybrid approach ensures that the system can find relevant answers, even when the query wording is ambiguous or technical.
Additionally, ranking models are used to sort retrieved chunks by relevance. These models evaluate:
- How well the chunk answers the query
- Source trustworthiness
- Recency of the data
The result? Only the most useful, high-confidence content reaches the generator.
4. On-Prem vs. Hybrid vs. Cloud Deployment
Security and control are critical in enterprise environments.
- On-premises deployment is ideal for organizations in heavily regulated sectors, such as healthcare, defense, or finance. It offers complete control over data storage and processing but comes with higher maintenance overhead.
- Hybrid deployment allows sensitive data to remain on-premises while using cloud services for computation.
- Cloud deployment is faster to scale and easier to manage. It’s best for teams with less sensitive data or strong vendor compliance frameworks.
Intellivon helps enterprises choose the right deployment model based on their compliance needs, IT readiness, and scalability goals.
5. Integration with Enterprise Data Sources
RAG systems must be able to pull from trusted, internal sources. This includes:
- CRMs like Salesforce or HubSpot
- Knowledge bases like Confluence or Notion
- Document repositories (SharePoint, Google Drive)
- Data lakes and warehouses
- Ticketing systems like Jira or Zendesk
Enterprise integration is often the most complex part of a RAG implementation. It requires secure APIs, custom connectors, and fine-grained access control to ensure only the right users get the right answers.
With the right architecture in place, RAG for enterprises becomes a highly scalable, secure, and intelligent solution, ready to handle real-world complexity at scale.
How We Add RAG to Your Enterprise LLM Stack
Integrating RAG for enterprises is a carefully engineered transformation. The goal is to create a scalable, context-aware solution that enhances accuracy, traceability, and performance across the board. Here’s how we bring enterprise-grade RAG to life in eight structured steps.
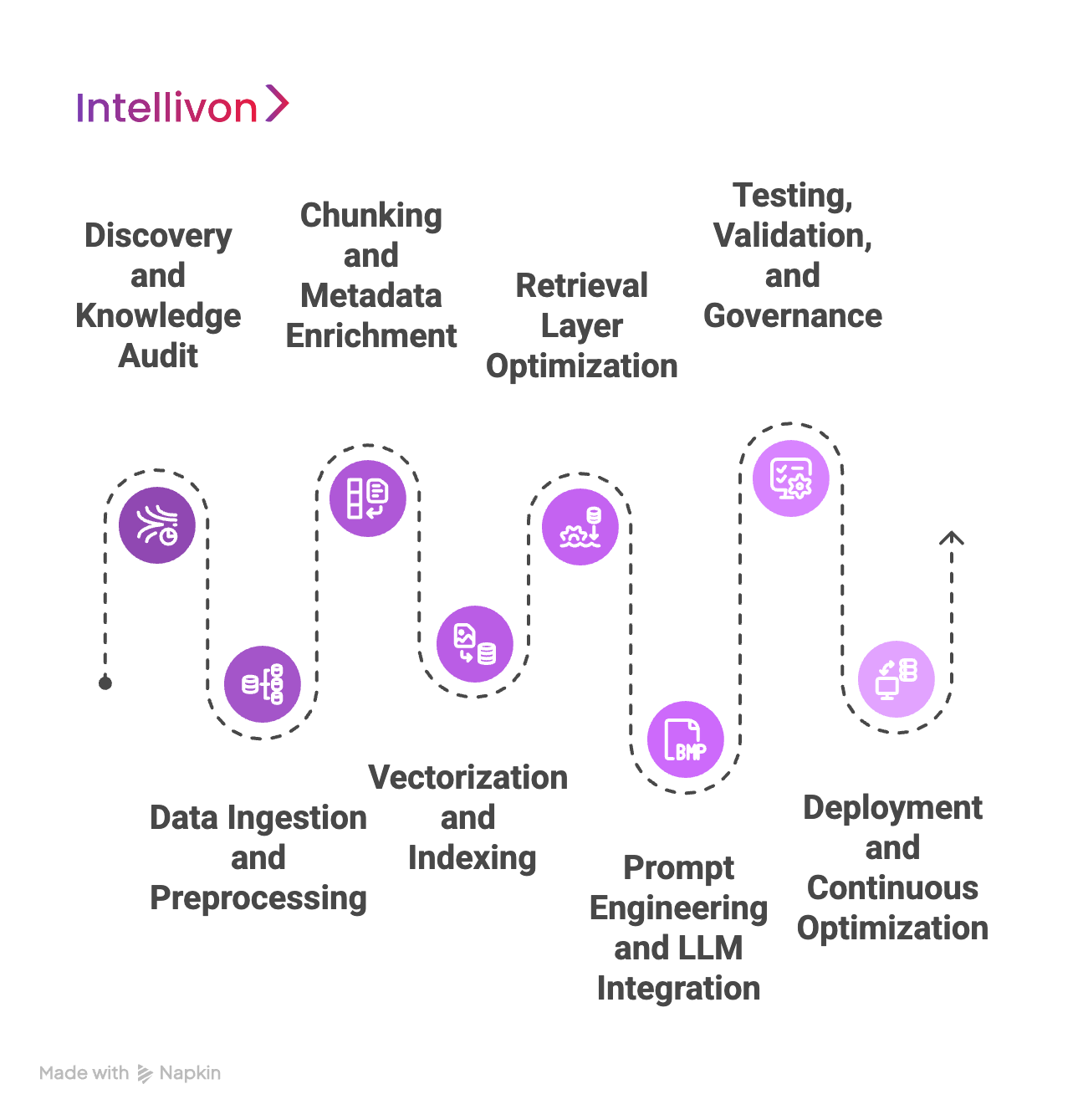
1. Discovery and Knowledge Audit
Every enterprise is different, and the first step is understanding how yours works. We begin with an in-depth discovery phase to map your internal data landscape. This includes identifying your core knowledge sources, key business units, and end-user needs. We also analyze how information flows between departments and where gaps or redundancies may exist. This audit sets the foundation for a RAG system that fits your unique goals rather than applying a generic template.
2. Data Ingestion and Preprocessing
Next, we bring your unstructured data into the pipeline. This involves collecting documents from across platforms, whether they’re stored in SharePoint, Google Drive, Confluence, or legacy systems. We then clean and normalize the content. Formatting inconsistencies, outdated files, and low-quality inputs are filtered or corrected. This step ensures that only accurate, useful, and compliant content is prepared for the next stages of processing.
3. Chunking and Metadata Enrichment
Instead of working with entire documents, we break them into smaller, semantically meaningful units, often paragraphs or sections. These “chunks” are easier to retrieve accurately based on user queries. During this process, we also tag the content with metadata like author, department, version, and access level. These tags help the retriever find contextually appropriate information and enforce role-based data access.
4. Vectorization and Indexing
Once chunked and enriched, each piece of content is transformed into embeddings using a selected vectorization model. This mathematical representation allows the system to measure semantic similarity between user questions and internal content. The embeddings are then stored in a secure vector database optimized for high-speed retrieval. This infrastructure forms the heart of your RAG pipeline, allowing for fast, relevant lookups.
5. Retrieval Layer Optimization
At this stage, we fine-tune how the retriever pulls information. Depending on your use case, we may use a hybrid search strategy combining semantic and keyword search. We also implement ranking models that score retrieved content based on relevance, recency, and trust level. This ensures that only the most accurate, high-confidence responses are passed to the generation layer, reducing the risk of irrelevant or outdated information reaching the end user.
6. Prompt Engineering and LLM Integration
Now, we bring the language model into the loop. The generator receives both the user query and the retrieved content. But before that happens, we craft intelligent prompts that instruct the LLM on how to respond, such as citing sources or prioritizing compliance-based language. This step ensures the generated output is not only fluent but grounded in enterprise-approved knowledge. At this point, your RAG system can already answer real user questions with context, accuracy, and traceability.
7. Testing, Validation, and Governance
Before going live, we run rigorous testing. This includes technical evaluations like precision, recall, and latency, as well as human-in-the-loop reviews for tone, factual accuracy, and legal risk. We also establish governance rules, such as access permissions, redaction logic, and fallback responses when confidence scores are low. These safeguards are vital in industries where accountability and compliance matter.
8. Deployment and Continuous Optimization
Finally, we deploy the full RAG stack into your chosen environment, on-prem, hybrid, or cloud. After launch, we don’t just walk away. Continuous monitoring ensures system health, user satisfaction, and response quality. Over time, we update content indexes, improve embedding models, and refine prompts based on user feedback. With this adaptive approach, your RAG system grows smarter and more valuable every day.
This eight-step process enables us to deliver RAG for enterprises that is designed to perform at scale in real-world environments where trust, security, and speed matter most.
Best Practices for RAG Implementation in Enterprise LLMs
Building a RAG-enhanced LLM is one thing. Making it enterprise-grade is another. At Intellivon, we ensure they’re usable, scalable, and trustworthy in real-world business settings.
Over time, we’ve developed a proven set of best practices that drive consistent results for our enterprise clients.
1. Balance Chunk Size and Context Window
One of the first technical decisions involves how to split your documents into chunks. If chunks are too large, they may exceed the model’s token limit or dilute relevance. If they’re too small, you risk missing context. We carefully balance chunk sizes based on your LLM’s capabilities and your document structure to ensure retrieval precision and context integrity.
2. Select the Right Embedding Models
Embedding models are the foundation of any RAG system. Choosing the wrong one can cripple retrieval quality. We evaluate several embedding strategies, from open-source models like Instructor-XL to proprietary ones, and run side-by-side tests using your actual enterprise data. This allows us to select models that truly “understand” your domain language and workflows.
3. Fine-Tune Retrieval with Real Business Queries
Off-the-shelf retrieval rarely works for enterprise needs. We test retrieval precision using actual employee queries gathered during discovery sessions. By scoring hits and misses, we fine-tune search parameters and re-rankers until the system consistently surfaces the most helpful content. This human-in-the-loop tuning ensures the system performs under real conditions, not just in demos.
4. Engineer Prompts for Grounded Responses
Even with perfect retrieval, your LLM still needs clear instructions. Our AI engineers prompt templates that guide the model to cite sources, avoid speculation, and use a formal or casual tone depending on the use case. We iterate these prompts through structured testing to ensure every output reflects your brand’s voice and compliance standards.
5. Keep the Knowledge Base Fresh
No RAG system is set-and-forget. We implement automated pipelines that refresh document indexes based on schedule or triggers, like when a new policy document is uploaded or a CRM entry is edited. This keeps your RAG responses accurate and relevant over time without needing model retraining.
These best practices ensure RAG for enterprises becomes a reliable, high-impact capability embedded in how your teams work.
The Cost of Ignoring RAG in Your Enterprise LLM Stack
Enterprises that delay adopting RAG often do so out of caution. But the risks of sticking with traditional LLMs, or worse, doing nothing, can be far more costly in the long run.
In enterprise environments, accuracy and accountability are non-negotiable. Without RAG, your LLM stack lacks both.
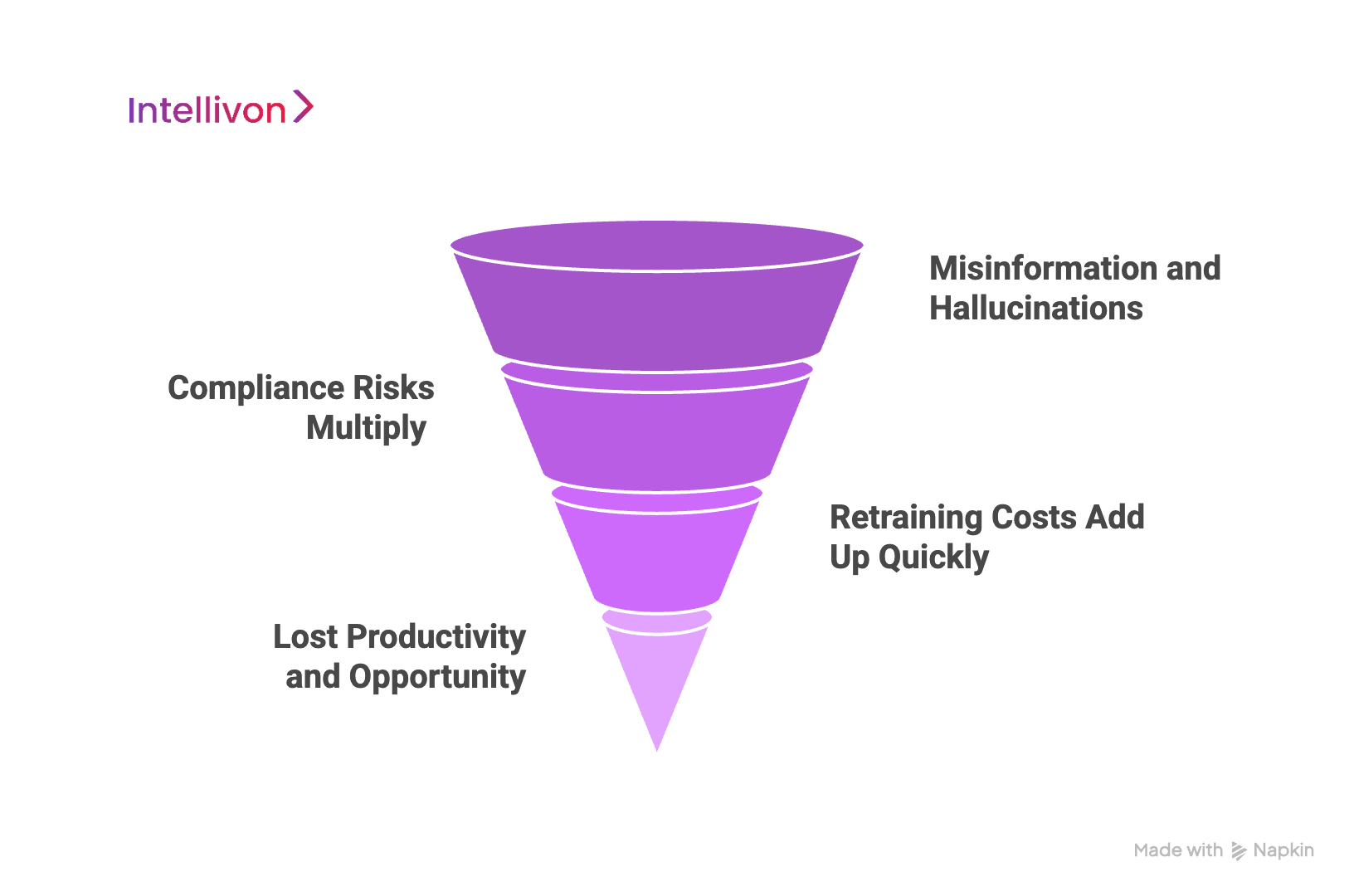
Misinformation and Hallucinations
Without access to your internal knowledge base, a standalone LLM can only generate responses based on its static training data. That means it will sometimes guess,and get it wrong. These hallucinations may seem harmless in casual conversations, but in enterprise use cases, they create serious problems.
For example, an HR assistant bot could give incorrect information about employee leave policies. Or a customer support AI might provide outdated warranty terms. Each of these errors erodes trust and may require manual corrections later.
2. Compliance Risks Multiply
In regulated industries like finance, law, or healthcare, incorrect information is a liability. An AI assistant that suggests a non-compliant process or cites the wrong regulation can put your business at legal and financial risk.
With RAG for enterprises, answers are grounded in verified internal documentation, reducing the risk of policy violations and audit failures. Ignoring this capability means exposing your systems, and your reputation, to unnecessary risk.
3. Retraining Costs Add Up Quickly
Traditional LLMs require frequent fine-tuning to stay relevant. This process is costly, time-consuming, and difficult to scale. Every time you update a product, policy, or regulation, your AI’s knowledge goes out of date.
RAG solves this by separating knowledge from the model. You update your content repository, and the system reflects it immediately. Ignoring RAG means you’re stuck in a cycle of retraining and revalidation that wastes resources without solving the core problem.
4. Lost Productivity and Opportunity
Perhaps the biggest cost is invisible: missed potential. Teams spend hours chasing documents, clarifying policy details, or correcting AI-generated errors. Meanwhile, AI systems that could be accelerating workflows and improving decision-making remain underpowered.
By not investing in RAG, enterprises miss the chance to turn their LLMs into truly intelligent assistants, ones that understand, adapt, and deliver results with confidence.
How We Overcome Limitations of RAG During Implementation
While RAG for enterprises offers a powerful framework, it’s not without its technical and operational challenges. Poor data quality, irrelevant retrievals, and latency issues can all limit performance if left unaddressed.
That’s why we’ve built a proven approach to solve these limitations head-on, ensuring every deployment is not just functional, but enterprise-ready from day one.
1. Dealing with Unstructured and Noisy Data
Many enterprises store their knowledge across inconsistent formats, like scanned PDFs, PowerPoint slides, outdated wikis, or handwritten notes. These materials often lack structure and clarity, which can disrupt chunking and retrieval.
To address this, we apply preprocessing techniques that clean, normalize, and enrich content before it ever enters the RAG pipeline. Optical character recognition (OCR), text hierarchy tagging, and semantic cleanup help ensure the AI is learning from clean, reliable content, not noise.
2. Improving Retrieval Relevance
One of the most common complaints with early RAG systems is irrelevant or shallow retrieval. When the retriever surfaces the wrong chunks, even the best LLM will fail to generate useful responses.
We solve this by testing and calibrating the retrieval engine using real user questions and fine-tuning the ranking layer. We also blend semantic and keyword search to ensure a hybrid model that can capture nuance and technical intent. This results in sharper, more targeted outputs.
3. Managing Latency and Performance
Real-time interaction matters, especially for customer-facing or productivity-critical applications. Without optimization, a RAG system can lag due to embedding computation, large index queries, or slow generation.
To avoid these bottlenecks, we optimize index structure, reduce unnecessary API hops, and cache frequent queries. In cases where performance is mission-critical, we also set up distributed search layers and lightweight fallback models to ensure users get answers quickly, even under load.
4. Extending Beyond Text-Based Content
Many enterprises rely on non-text assets like charts, voice notes, and images. Traditional RAG pipelines ignore these formats, but we don’t. Our multimodal extensions allow integration with OCR outputs, transcription layers, and even structured datasets, so your system doesn’t miss out on valuable context.
5. Adding Safety Nets and Guardrails
We embed safeguards to prevent overconfidence in low-confidence scenarios. These include confidence scoring, fallback messages, human-in-the-loop escalation, and restricted content filters. The system knows when not to answer, protecting both accuracy and brand integrity.
By addressing these common limitations head-on, we ensure that RAG for enterprises not only works, but works where it counts: in the complexity of your real-world operations.
Conclusion
For enterprises aiming to scale AI responsibly, RAG is a necessity. It adds context, traceability, and control to your LLM stack, transforming generic responses into reliable business intelligence.
As data, risk, and user expectations grow, grounding your AI with RAG ensures it stays accurate, compliant, and usable. Now is the time to treat RAG as core infrastructure, and not a future upgrade.
Ready To Get Your Enterprise-Grade RAG System Built?
With over 11 years of enterprise AI expertise and 500+ successful deployments across industries, Intellivon is your trusted partner in building secure, scalable, and intelligent RAG-powered systems that go far beyond generic AI integration. From real-time knowledge retrieval to domain-specific grounding, we help enterprises move from hallucination-prone LLMs to trustworthy, context-aware AI performance.
What Sets Intellivon Apart?
Enterprise-Tuned Retrieval Systems: We architect RAG pipelines with domain-specific embeddings, adaptive chunking, and vector search tuned to your internal content and workflows.
Secure, Scalable Deployments: Our solutions support on-prem, hybrid, and cloud environments with enterprise-grade encryption, RBAC, and full audit trails to meet your compliance and IT standards.
LLM-Agnostic Flexibility: We integrate RAG into open-weight and commercial models alike, ensuring maximum interoperability across your existing stack.
Real-Time Indexing and Updating: We build automated pipelines to keep your RAG system in sync with evolving documents, CRMs, knowledge bases, and databases—no retraining required.
Use Case-Centric Design: From support bots to legal research assistants to finance copilots, we tailor the experience to your specific enterprise needs for maximum impact and adoption.
Our AI strategy experts will deliver:
- A full audit of your internal data ecosystem and AI maturity
- Use case identification aligned with enterprise ROI
- Deployment blueprint customized for your stack and regulatory environment
- RAG pipeline design built for speed, scale, and knowledge accuracy
Book your free strategy call with an Intellivon expert today and start building the intelligent, grounded AI infrastructure your enterprise needs to lead the future.
FAQs
Q1. What is Retrieval-Augmented Generation (RAG) in enterprise AI?
A1. RAG is an AI framework that enhances LLMs by retrieving information from internal knowledge bases before generating responses, ensuring context accuracy.
Q2. Why do LLMs need RAG for enterprise use?
A2. LLMs lack access to private, real-time knowledge. RAG provides them with secure, up-to-date, and relevant context, minimizing hallucinations.
Q3. Can RAG be integrated into our existing LLM setup?
A3. Yes. Intellivon integrates RAG with both cloud and on-prem deployments, adapting to your current AI infrastructure.
Q4. What kind of data sources can RAG retrieve from?
A4. RAG can connect to PDFs, CRMs, ticketing systems, ERPs, databases, knowledge wikis, and even audio transcripts.
Q5. How fast can an enterprise RAG system be deployed?
A5. With Intellivon’s modular approach, most systems go live within 4–6 weeks, depending on scale and security needs.



