Our clients trust us to engineer solutions that combine cutting-edge AI with industry-leading reliability, ensuring unmatched performance in every project.





Our services include end-to-end reliability engineering, risk management, automated testing, and performance optimization, ensuring seamless AI deployment and performance.
We take a comprehensive, phased approach to reliability engineering, utilizing predictive analytics, robust testing, and real-time monitoring to ensure sustained AI performance.
Align reliability goals with business objectives.
Assess current system performance and identify gaps.
Define key reliability metrics and success factors.
Conduct risk assessments to uncover potential vulnerabilities.
Design scalable and fault-tolerant AI architectures.
Prioritize performance features based on business needs.
Evaluate technical feasibility of proposed solutions.
Test initial concepts using iterative feedback and prototypes.
Apply best practices for reliability engineering and AI systems.
Implement rigorous testing, automation, and monitoring.
Integrate continuous improvement and risk mitigation strategies.
Provide post-launch support to ensure ongoing performance.
We partnered with a leading semiconductor manufacturer to enhance their production line’s reliability. By implementing predictive maintenance systems and continuous monitoring, we reduced machine downtime and improved operational efficiency.
We partnered with a leading semiconductor manufacturer to enhance their production line’s reliability. By implementing predictive maintenance systems and continuous monitoring, we reduced machine downtime and improved operational efficiency.
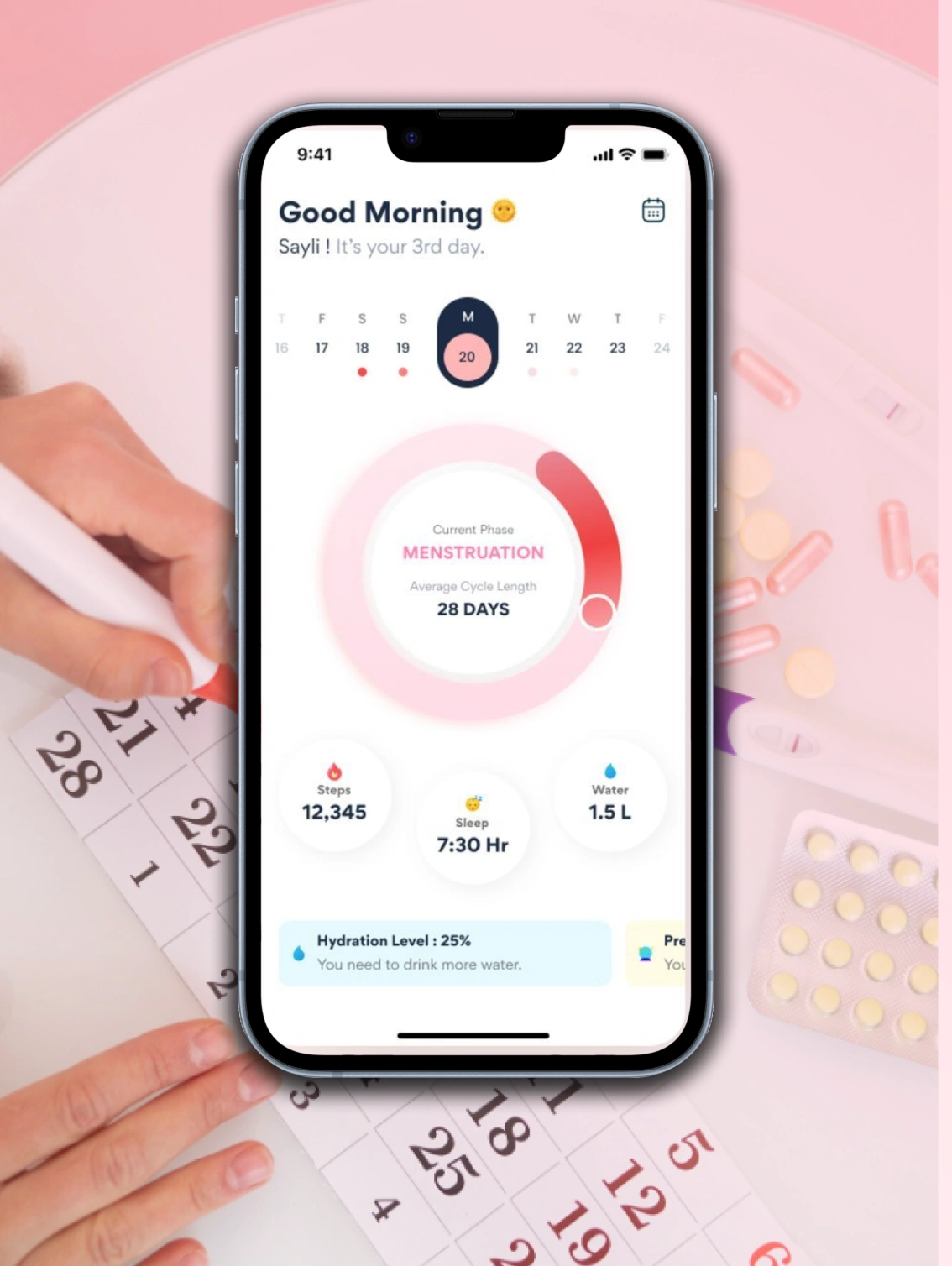
For a major pharmaceutical firm, we enhanced the reliability of their lab equipment by integrating IoT-based monitoring and real-time diagnostics. This minimized equipment failure and ensured uninterrupted research activities.
For a major pharmaceutical firm, we enhanced the reliability of their lab equipment by integrating IoT-based monitoring and real-time diagnostics. This minimized equipment failure and ensured uninterrupted research activities.

We assisted a global fintech firm in optimizing the reliability of their core banking system, focusing on fault-tolerant infrastructure and automated failover mechanisms. This reduced system outages and ensured continuous financial services.
We assisted a global fintech firm in optimizing the reliability of their core banking system, focusing on fault-tolerant infrastructure and automated failover mechanisms. This reduced system outages and ensured continuous financial services.
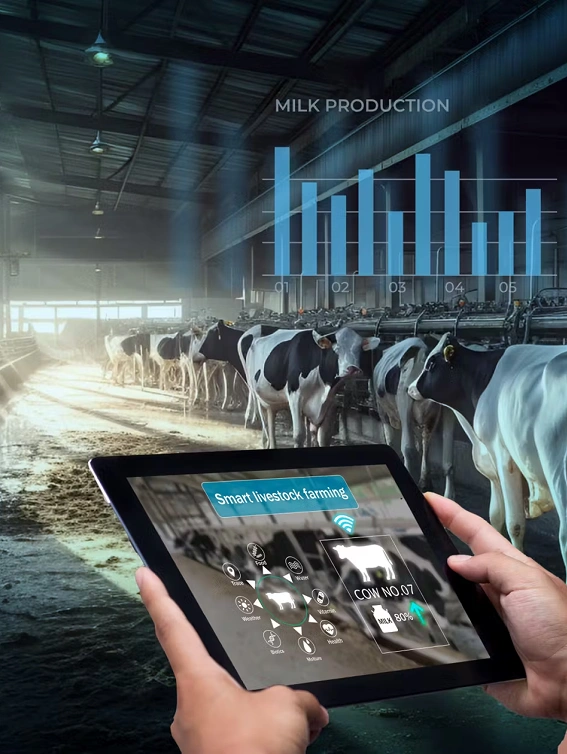
We worked with an energy provider to implement advanced monitoring systems for their grid infrastructure, enabling real-time detection and correction of anomalies. This enhanced grid stability and reduced energy disruptions.
We worked with an energy provider to implement advanced monitoring systems for their grid infrastructure, enabling real-time detection and correction of anomalies. This enhanced grid stability and reduced energy disruptions.

For a leading retail brand, we optimized the reliability of their e-commerce platform by deploying load balancing, fault tolerance, and automated failover processes, resulting in improved transaction success rates and operational efficiency.
For a leading retail brand, we optimized the reliability of their e-commerce platform by deploying load balancing, fault tolerance, and automated failover processes, resulting in improved transaction success rates and operational efficiency.

With deep industry knowledge and specialized AI reliability engineering experience, we craft solutions that address the unique challenges of modern enterprise systems.
We design reliability frameworks that grow with your business, ensuring seamless performance as data volumes, users, and operational demands increase over time.
Our predictive analytics models foresee potential failures and performance bottlenecks, empowering your team to resolve issues before they impact operations or system stability.
We provide 24/7 monitoring services, identifying early signs of issues, ensuring that your AI systems perform optimally and stay resilient under any circumstances.
Intellivon offers comprehensive risk management strategies that proactively address vulnerabilities across your AI systems, ensuring long-term reliability without compromising security or performance.
We specialize in building high-availability, fault-tolerant infrastructures that ensure your AI solutions maintain performance and reliability, even during peak loads or unforeseen disruptions.
We leverage industry-leading tools like automated testing platforms, predictive analytics, and AI-powered monitoring to ensure reliable performance across all AI solutions.
Faster modernization cycle
Lower engineering costs
Fewer bugs and reworks
Faster launch timelines
Reliability engineering for AI systems ensures that your AI-driven products are built to perform consistently, remain fault-tolerant, and scale effectively while minimizing downtime.
Reliability engineering helps prevent system failures, optimize performance, and ensure scalability, which is critical for enterprises that rely on AI systems for continuous operations and business success.
Intellivon employs a combination of predictive analytics, automated testing, continuous monitoring, and scalable infrastructure design to ensure that AI systems perform reliably under all conditions.
Intellivon uses cutting-edge technologies like AWS, Google Cloud, Prometheus, Kubernetes, TensorFlow, Jenkins, and Terraform to provide reliable, scalable, and secure AI solutions.
By identifying weaknesses, optimizing workflows, and predicting potential failures, reliability engineering ensures that AI systems operate at peak efficiency, reducing downtime and improving overall performance.
Predictive analytics helps identify system vulnerabilities before they cause failures, allowing businesses to take proactive measures, reduce downtime, and optimize system performance in real time.
Intellivon designs fault-tolerant, high-availability infrastructures and implements automated performance optimization to ensure AI systems scale seamlessly as demands increase, without sacrificing reliability.
Intellivon offers continuous post-deployment support, including system health checks, patch management, and real-time monitoring, ensuring your AI solutions stay reliable and optimized long-term.