As healthcare systems modernize, there’s an interesting divide. Here, HL7 handles daily clinical tasks while FHIR focuses on digital platforms, analytics, and external access. Data must flow between these two areas, and that flow has to be reliable. The issue is that over time, managing that flow becomes very complicated.
Most organizations already have a method to convert HL7 to FHIR. Here, messages are parsed, mapped, and sent to their respective destinations. But as volumes increase and use cases expand, things begin to falter. Because of this, errors emerge downstream, where they are much harder to identify and correct. What should enable interoperability ends up causing obstacles instead.
That’s why HL7 to FHIR transformation engines cannot simply be quick integrations thrown together at the last minute. They must be planned as governed enterprise platforms from the beginning.
In this blog, we will discuss how to create transformation engines that scale safely, maintain clinical meaning, and remain auditable as complexity increases. We will also share what Intellivon has learned from building and delivering HL7 to FHIR platforms that work effectively in production.
![]()
Why Invest In Data Transformation Engines Right Now
Data transformation engines act as specialized platforms that ingest raw healthcare data from different systems and convert it into consistent, standardized formats. This process prepares data for interoperability, analytics, and AI-driven use cases.
By handling normalization, validation, and structure alignment, these engines make complex healthcare data usable at an enterprise scale. The healthcare data integration platforms market continues to expand steadily. In 2025, the market is valued at USD 1.15 billion and is projected to reach USD 2.80 billion by 2034. This growth reflects a CAGR of 10.39% over the forecast period.
A key driver behind this momentum is the growing use of predictive analytics within healthcare data platforms, which enables more informed and timely decision-making across enterprise operations.
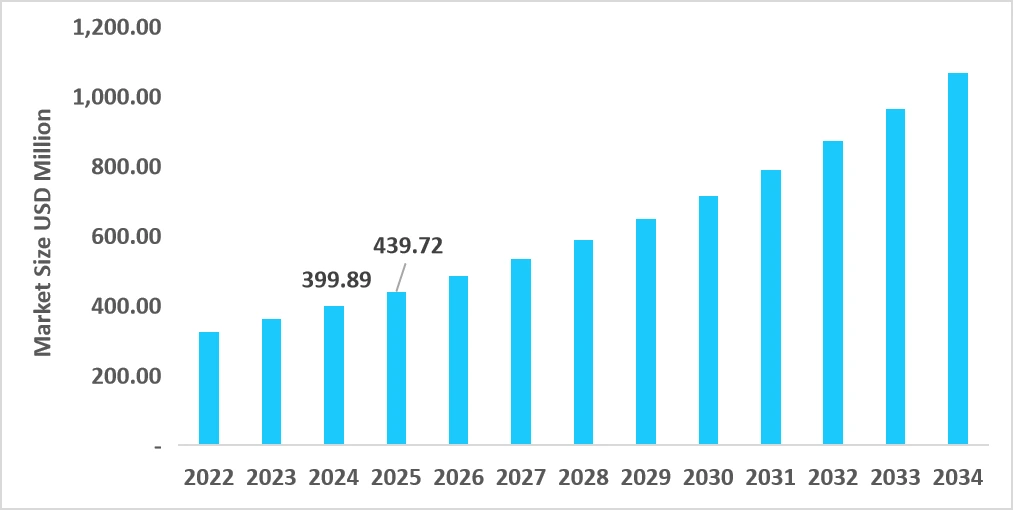
Market Insights:
- FHIR and regulatory pressure: New mandates in the US and EU push real-time FHIR data exchange by 2026. As a result, enterprises must translate legacy HL7 data reliably at scale.
- Rapid growth in AI and analytics adoption: Healthcare analytics spending is accelerating sharply through 2030. However, advanced models depend on clean, enriched data extracted from fragmented systems.
- Rising healthcare data volumes: Telehealth, IoT, and connected devices generate large volumes of unstructured data. Therefore, real-time ETL and ELT pipelines are becoming operational necessities.
- Acceleration of digital health transformation: Enterprise investment in digital healthcare platforms is expanding rapidly. Interoperability infrastructure underpins this growth by enabling data reuse across initiatives.
Together, these trends show why healthcare data transformation can no longer be handled through isolated integrations. Regulatory timelines, analytics growth, and digital care models all depend on timely, structured data.
HL7 to FHIR data transformation engines give enterprises a consistent way to modernize legacy data while supporting scale, compliance, and future innovation.
Why Healthcare Enterprises Need HL7 to FHIR Data Transformation Engines
Healthcare enterprises operate in two parallel realities. HL7 continues to power core clinical workflows, while FHIR increasingly supports apps, analytics, external access, and automation. Data must move between these formats continuously and reliably. When that movement relies on scattered logic and one-off mappings, risk and cost rise quietly over time.
HL7 to FHIR data transformation engines address this gap directly. They provide a structured, governed way to modernize legacy data without disrupting live operations. For enterprises managing scale, regulation, and long-term digital growth, this capability is no longer optional.
1. HL7 and FHIR Must Operate Together for the Long Term
HL7 is deeply embedded in daily healthcare operations. Admissions, lab results, orders, and documents still depend on HL7 messages. Replacing these systems is neither fast nor realistic at enterprise scale.
At the same time, FHIR is required for modern interoperability. Apps, APIs, and analytics platforms depend on it. A transformation engine allows both standards to coexist, ensuring data flows forward without forcing risky system replacement.
2. Point Integrations Do Not Scale Across Enterprise Ecosystems
Early interoperability efforts often rely on direct integrations. Teams map HL7 to FHIR where the need is immediate. Over time, these mappings multiply across applications and departments.
As a result, consistency erodes, validation rules differ, and changes require rework in multiple places. HL7 to FHIR data transformation engines centralize this logic, reducing duplication and restoring control as ecosystems grow.
3. FHIR App Access Increases Downstream Risk
FHIR app adoption exposes transformed data to many consumers at once. Once data leaves the enterprise boundary, errors become harder to detect and correct. Small mapping issues can affect analytics, automation, and decision support.
Transformation engines reduce this risk by enforcing consistent rules before data is published. They ensure that HL7 data is validated, normalized, and contextually accurate before it reaches downstream systems.
4. Analytics and AI Depend on Reliable Data Foundations
Enterprise analytics and AI initiatives depend on structured, trustworthy data. HL7 messages were not designed for this purpose. They vary by system and often lack consistency across sites.
HL7 to FHIR data transformation engines create a stable data foundation. They normalize structure and meaning so insights can scale reliably across populations, regions, and use cases.
5. Regulatory and Audit Pressure Require Centralized Control
Regulatory timelines continue to expand the scope of required data exchange. At the same time, audits demand traceability and consistency across data flows.
Transformation engines provide a single control point. They support versioning, audit trails, and policy enforcement. This reduces compliance risk while simplifying oversight at enterprise scale.
Healthcare enterprises need HL7 to FHIR data transformation engines because interoperability has moved beyond isolated use cases. Data now supports apps, analytics, and automation across the organization.
Without a centralized transformation layer, scale introduces risk instead of value. Transformation engines provide the structure, consistency, and governance required to modernize safely while keeping core operations stable.
Risks Enterprises Face Without HL7 to FHIR Transformation Engines
As FHIR adoption expands, data transformation moves closer to the center of enterprise operations. What once sat quietly inside interface engines now influences analytics accuracy, app reliability, and regulatory exposure. When HL7 to FHIR conversion lacks structure and governance, risk accumulates in places that are difficult to detect early.
These risks rarely appear as system outages. Instead, they surface gradually through slower execution, higher costs, and reduced confidence in data-driven decisions. For large enterprises, the absence of a dedicated transformation engine creates fragility that compounds over time.
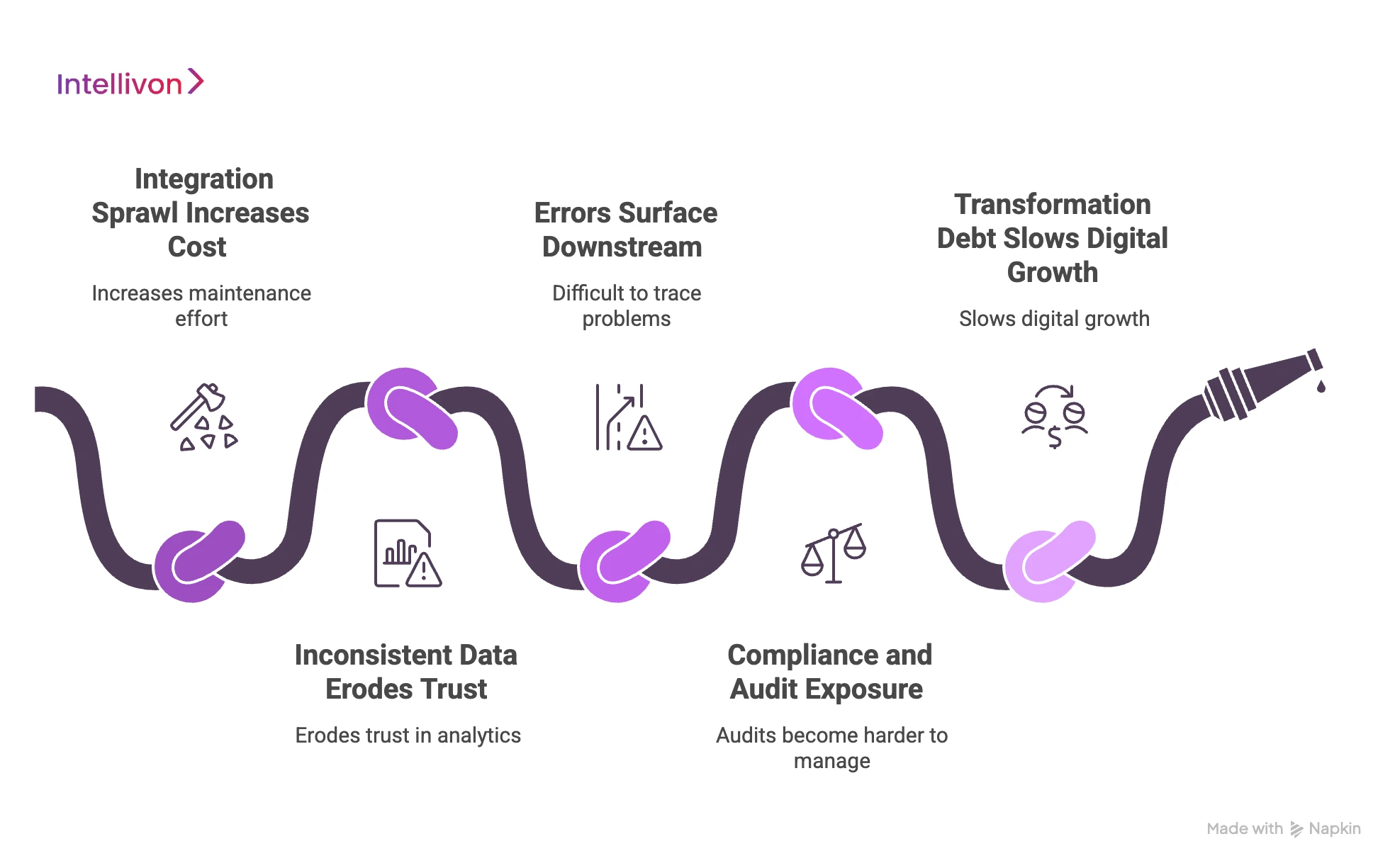
1. Integration Sprawl Increases Cost
Without a centralized transformation engine, HL7 to FHIR mapping logic spreads across teams and tools. Each application solves the problem locally. Over time, the same data is transformed in different ways for different use cases.
This fragmentation increases maintenance effort. Updates require changes in multiple places. Small adjustments turn into coordinated projects. As a result, integration costs rise quietly while delivery timelines stretch.
2. Inconsistent Data Erodes Trust
FHIR consumers expect consistency. When HL7 to FHIR transformations vary by source or application, analytics teams receive conflicting signals. Here, reports disagree, dashboards lose credibility, and leaders hesitate to rely on insights that cannot be reconciled easily.
These issues often trace back to transformation logic, not the analytics layer itself. Without a governed engine, enterprises struggle to correct the root cause and restore trust in their data.
3. Errors Surface Downstream
Poor transformation rarely fails at the point of conversion. Instead, issues emerge downstream in apps, automation workflows, or decision support systems. At that stage, tracing the problem back to a specific HL7 message or mapping becomes time-consuming.
As FHIR app access grows, these downstream failures affect more consumers at once. Without a transformation engine that enforces validation and traceability, containment becomes difficult and expensive.
4. Compliance and Audit Exposure
Regulatory requirements increasingly focus on data accuracy, provenance, and consistency. When HL7 to FHIR transformations are distributed and undocumented, audits become harder to manage. Demonstrating how data was transformed, validated, and shared turns into a manual effort.
A lack of centralized control increases compliance risk. Enterprises may meet functional requirements while still failing to prove governance during audits.
5. Transformation Debt Slows Digital Growth
Every shortcut taken in transformation logic creates future friction. New initiatives must work around existing inconsistencies. At the time, teams hesitate to reuse data pipelines. Innovation slows because the foundation feels unstable.
HL7 to FHIR transformation engines reduce this debt by standardizing how data is prepared and shared. Without them, growth introduces drag instead of momentum.
The absence of HL7 to FHIR data transformation engines does not usually cause immediate failure. Instead, it introduces gradual business risk through rising costs, unreliable data, and slower execution.
As FHIR becomes central to enterprise workflows, unmanaged transformation shifts from a technical concern to a strategic liability. Addressing this risk early allows enterprises to scale interoperability without sacrificing control, trust, or speed.
![]()
70% of Hospitals Now Support FHIR Apps, Raising HL7 to FHIR Risk
FHIR-based app access has moved firmly into mainstream healthcare operations. In 2024, ASTP and ONC analysis showed that 70% of hospitals supported FHIR app access, while 81% enabled some form of app-based data exchange.
At this level of adoption, FHIR is no longer a future initiative. It is already embedded in daily enterprise workflows.
1. FHIR App Access Pushes HL7 to FHIR Transformation Into Production Scale
Early FHIR implementations often focused on limited use cases. Patient-facing apps and pilot integrations were common starting points. However, as app access expands across departments and partners, transformation workloads increase rapidly.
HL7 messages now feed multiple downstream consumers through FHIR. A single admission or lab result may support care coordination, reporting, population health, and AI models at the same time.
Without a centralized HL7 to FHIR data transformation engine, these mappings are spread across teams and tools. Over time, that fragmentation becomes difficult to manage and expensive to correct.
2. App-Based Access Raises the Cost of Poor HL7 to FHIR Mapping
FHIR apps assume data consistency. They rely on stable structures, predictable semantics, and reliable context. When HL7 to FHIR mapping varies by interface or application, errors surface downstream rather than at the source.
This creates a compounding problem. Incorrect transformations do not fail loudly. Instead, they quietly affect analytics accuracy, workflow automation, and clinical insights. As app adoption grows, enterprises lose the ability to contain these issues locally.
A governed transformation engine becomes the only practical way to enforce consistency before data is exposed.
3. Why App Adoption Shifts Transformation From Integration to Infrastructure
At lower adoption levels, HL7 to FHIR conversion can survive as a supporting function. At scale, it becomes infrastructure. App access turns transformation engines into shared enterprise services rather than project-level components.
This shift brings new expectations. Transformation logic must be versioned. Validation must be enforced before data is published. Audit trails must be available when issues arise. Enterprises that treat HL7 to FHIR conversion as middleware struggle to keep up once FHIR access becomes widespread.
The rise of FHIR app access marks a clear turning point. When 70% of hospitals support FHIR-based applications, HL7 to FHIR transformation can no longer be informal or fragmented.
Data transformation engines become the control layer that protects data quality, supports scale, and enables safe reuse across enterprise initiatives. As FHIR adoption accelerates, building these engines correctly becomes a foundational requirement, not an architectural preference.
What an HL7 to FHIR Data Transformation Engine Actually Does in Practice
HL7-to-FHIR data transformation engines operate at the center of modern healthcare data flows. They sit between legacy clinical systems that produce HL7 messages and digital platforms that require structured FHIR data. As data moves between these environments, accuracy and consistency become critical.
For enterprises, this layer directly influences analytics quality, application reliability, and regulatory confidence. These engines do not simply convert formats. Instead, they shape whether data can be trusted and reused safely across the organization.
1. Receive HL7 Data Without Disrupting Operations
Transformation engines continuously ingest HL7 messages from core systems. These messages include admissions, lab results, orders, and clinical documents. Volumes often fluctuate throughout the day.
In practice, the engine must handle this variability without data loss. It manages retries, sequencing, and fault handling in the background. As a result, upstream systems remain stable while downstream platforms receive reliable input.
2. Normalize Inconsistent and Fragmented HL7 Data
HL7 implementations differ widely across hospitals and regions. Optional fields may be missing. At the same time, custom segments are common, and data formats are rarely uniform.
The engine parses each message and normalizes its content. Timestamps, units, identifiers, and codes are aligned into consistent structures. This step reduces variability before the data is exposed to other systems.
3. Convert HL7 Messages Into Meaningful FHIR Resources
Mapping HL7 to FHIR is rarely straightforward. A single HL7 message can generate multiple FHIR resources. In addition, several messages may contribute to one resource over time.
Transformation engines manage this complexity centrally. They preserve clinical context and relationships rather than copying fields mechanically. This approach ensures that downstream systems receive data that reflects real-world care events.
4. Validate Data Before It Is Shared Externally
FHIR-based systems expect data to follow defined structures and profiles. When validation is skipped, errors often surface later in apps or analytics tools.
Transformation engines apply validation rules before publishing data. Required fields are checked. Value sets are enforced. Invalid resources are quarantined and logged. This prevents silent failures and protects downstream workflows.
5. Maintain Traceability and Support Audits
Enterprises must understand how data moves and changes. When issues arise, teams need to trace outputs back to their source.
In practice, transformation engines record lineage across each step. HL7 messages can be linked to resulting FHIR resources. Mapping versions and timestamps are preserved. This visibility supports audits, investigations, and compliance reviews.
6. Publish Consistent FHIR Data for Reuse
Once data is transformed and validated, the engine publishes it through governed FHIR interfaces. Multiple applications can consume the same data simultaneously.
Because transformation logic is centralized, all consumers receive consistent outputs. As a result, enterprises can scale apps, analytics, and AI initiatives without rebuilding integrations repeatedly.
In practice, HL7 to FHIR data transformation engines act as control layers, not conversion utilities. They absorb variability, enforce consistency, and protect data quality as reuse increases. For enterprises, these engines determine whether FHIR adoption accelerates growth or introduces hidden operational risk. When designed as governed infrastructure, they provide a stable foundation for long-term digital strategy.
Types of Clinical and Operational Data Handled by HL7 to FHIR Engines
HL7 to FHIR data transformation engines handle far more than simple clinical messages. They sit at the intersection of care delivery, operations, analytics, and compliance. As enterprises expose data through APIs and apps, the range of data flowing through this layer expands quickly.
Understanding the types of data involved helps clarify why transformation accuracy matters. Each category carries different sensitivity, structure, and downstream impact. When handled correctly, these data streams support scale. When handled poorly, they introduce risk across the organization.
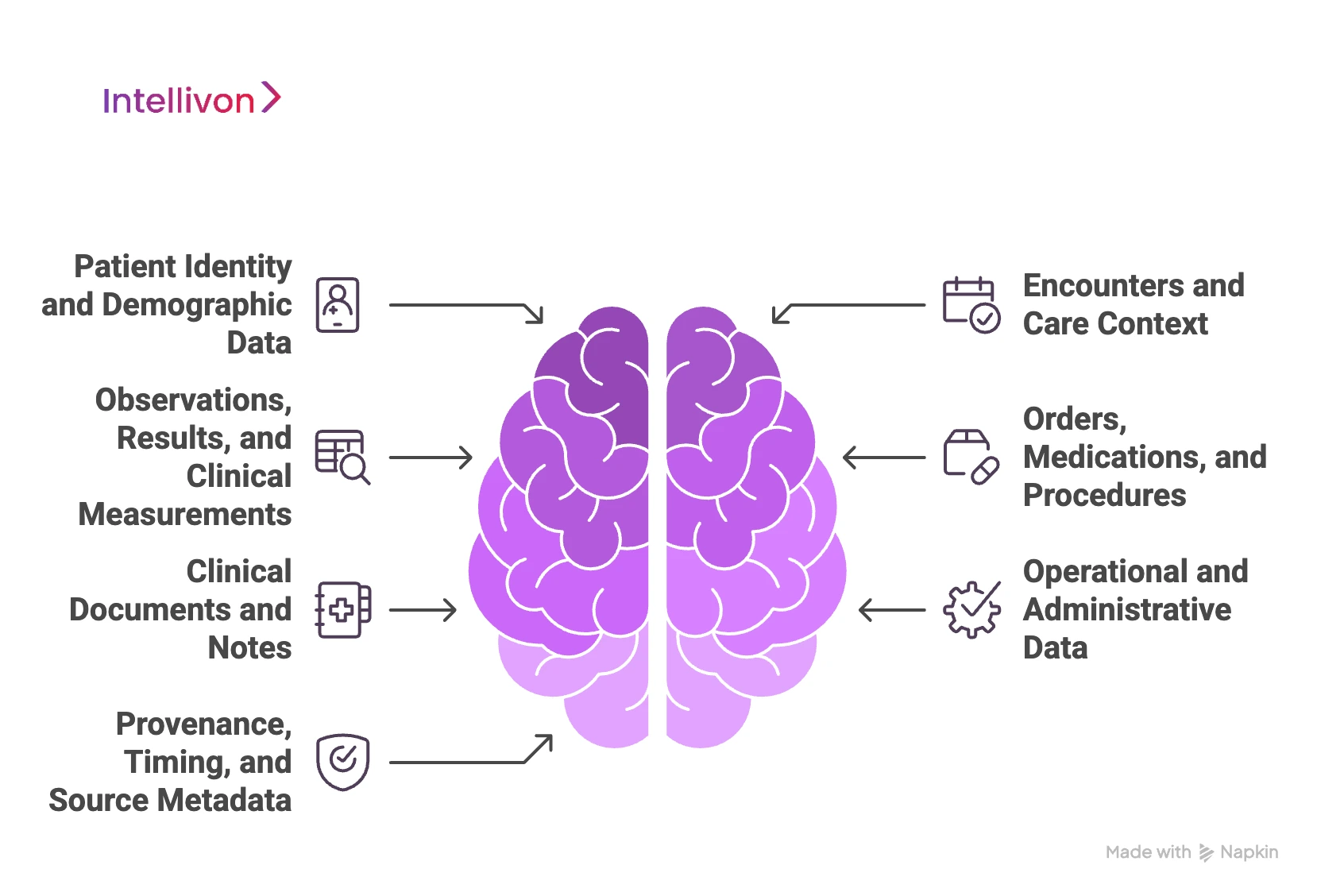
1. Patient Identity and Demographic Data
Patient identity data forms the foundation of interoperability. It includes identifiers, names, demographics, and contact information. Errors at this level propagate across every downstream system.
HL7 to FHIR engines reconcile identity fields and maintain consistent references across encounters and systems. This reduces mismatches and supports reliable patient-level aggregation. As app access grows, accurate identity handling becomes critical for safety and trust.
2. Encounters and Care Context
Encounter data provides clinical context. It links patients to visits, locations, providers, and timeframes. Without this context, clinical data loses meaning.
Transformation engines convert HL7 encounter details into structured FHIR Encounter resources. They preserve relationships between admissions, transfers, and discharges. This context allows analytics, reporting, and workflows to reflect real care events accurately.
3. Observations, Results, and Clinical Measurements
Observations represent one of the highest-volume data streams. Labs, vitals, imaging results, and device readings flow continuously through HL7 messages.
Engines normalize units, timestamps, and codes before mapping them into FHIR Observation resources. This consistency supports analytics, monitoring, and AI use cases. Without normalization, comparing results across systems becomes unreliable.
4. Orders, Medications, and Procedures
Orders and medication data drive both care delivery and operational workflows. These messages often involve multiple HL7 segments and evolving states.
HL7 to FHIR engines consolidate this information into structured FHIR resources. They track status changes, relationships, and timing. This enables downstream systems to support decision support, automation, and audit requirements.
5. Clinical Documents and Notes
Clinical documents include discharge summaries, reports, and care plans. These are often semi-structured and linked to specific encounters.
Transformation engines manage document metadata and references through FHIR resources such as DocumentReference. This allows documents to remain accessible and traceable while supporting reuse across platforms.
6. Operational and Administrative Data
Beyond clinical content, HL7 feeds carry operational data. Scheduling details, provider information, and facility identifiers often travel alongside care data.
Engines separate and structure this information for operational reporting and coordination. This supports enterprise planning, performance monitoring, and system optimization without mixing operational logic into clinical workflows.
7. Provenance, Timing, and Source Metadata
Metadata is essential for trust and governance. Provenance shows where data originated and how it was transformed. Timing data establishes sequence and relevance.
HL7 to FHIR engines preserve this metadata during transformation. They attach source references, timestamps, and version information to FHIR resources. This visibility supports audits, investigations, and safe reuse.
By handling these data types consistently and transparently, enterprises create a foundation that supports analytics, automation, compliance, and growth without compromising data integrity.
This breadth of responsibility is why transformation engines must be designed as enterprise infrastructure, not narrow integration tools.
![]()
Core Features of an Enterprise-Grade HL7 to FHIR Transformation Engine
At enterprise scale, HL7 to FHIR transformation cannot rely on basic conversion logic. The engine must operate as shared infrastructure that supports multiple teams, use cases, and regulatory demands at once. Its features determine whether interoperability accelerates growth or becomes a source of fragility.
Enterprise-grade transformation engines are defined less by what they convert and more by how they behave under pressure. The following features distinguish platforms that scale safely from those that require constant intervention.
1. High-Throughput HL7 Ingestion
Enterprise environments generate HL7 messages continuously. Volumes fluctuate throughout the day and spike during peak clinical activity. Transformation engines must ingest this data without delay or loss.
An enterprise-grade engine supports high-throughput ingestion with built-in fault tolerance. It manages retries, message ordering, and backpressure automatically. As a result, upstream clinical systems remain stable even when downstream demand increases.
2. Configurable and Versioned Mapping Logic
Enterprise engines externalize mapping rules into configurable, versioned definitions. Teams can update mappings without redeploying core services. Version control ensures changes are traceable and reversible when needed.
3. FHIR Validation and Profile Enforcement
FHIR consumers depend on predictable structure and semantics. Without enforcement, malformed resources reach apps, analytics platforms, and partners.
Enterprise-grade engines validate every resource before publication. They enforce required fields, value sets, and profiles consistently. Invalid data is isolated early, which prevents downstream disruption and reduces investigation time.
4. Centralized Governance and Policy Controls
As FHIR adoption expands, governance becomes unavoidable. Here, different teams access the same data for different purposes. At the same time, policies must apply consistently across use cases.
Transformation engines provide centralized control for access rules, data handling policies, and publishing behavior. This allows enterprises to manage change centrally rather than negotiating rules application by application.
5. End-to-End Traceability and Audit Support
Transformation decisions must be explainable. When issues arise, teams need to trace outputs back to their source quickly.
Enterprise-grade engines capture lineage across ingestion, mapping, validation, and publication. HL7 messages link directly to resulting FHIR resources. This visibility supports audits, incident response, and regulatory reviews without manual reconstruction.
6. Scalable FHIR Data Publishing
Enterprises rarely serve a single downstream system. This is because apps, analytics platforms, AI pipelines, and partners often consume the same data simultaneously.
Transformation engines publish FHIR data through governed interfaces that support reuse. Because transformation logic is centralized, all consumers receive consistent outputs. This reduces duplication and simplifies ecosystem growth.
7. Operational Monitoring and Observability
At scale, silent failures are costly. Teams need insight into throughput, errors, and transformation behavior in real time.
Enterprise engines include monitoring and alerting across each stage of the pipeline. This observability allows teams to detect issues early, adjust capacity, and maintain service reliability as demand grows.
These features determine whether interoperability remains manageable as complexity increases. When designed correctly, the engine becomes a stable foundation that supports innovation without introducing operational risk.
How We Build HL7 to FHIR Data Transformation Engines
Building an HL7 to FHIR data transformation engine is not a one-time integration exercise. It is an enterprise platform built that must hold up under live clinical operations, shifting requirements, and long-term reuse. Therefore, the delivery approach matters as much as the technical design.
At Intellivon, we build these engines with a clear goal, which is that the platform must remain safe, auditable, and scalable long after launch. Below is our seven-step process for delivering transformation engines that enterprises can trust and expand.
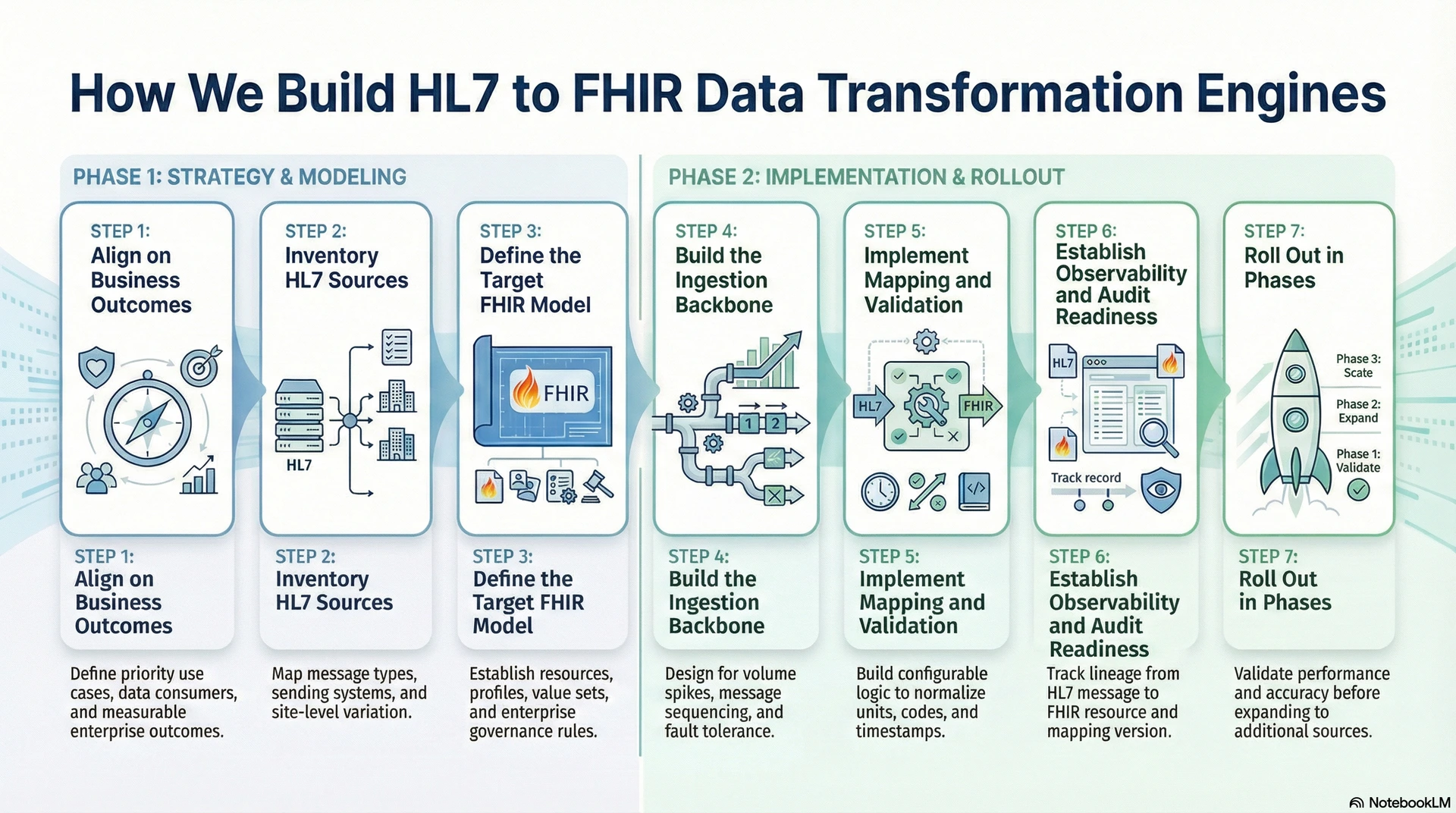
Step 1: Align on Business Outcomes
We begin by defining what the engine must enable. This includes priority use cases such as app access, analytics, partner exchange, and automation. In addition, we document who consumes the data and how it will be used.
This step prevents misalignment later. It also keeps architecture decisions tied to measurable enterprise outcomes.
Step 2: Inventory HL7 Sources
Next, we map the real HL7 landscape. We identify message types, sending systems, frequency, and site-level variation. We also capture custom segments, optional fields, and known inconsistencies.
This work is essential because HL7 is rarely uniform. As a result, transformation engines must be designed for variability from day one.
Step 3: Define the Target FHIR Model
We then define the target FHIR resources, profiles, and value sets based on the agreed use cases. We align resource modeling to enterprise governance rules, including provenance, consent, and audit needs. In addition, we establish transformation standards that teams can follow consistently.
This step turns FHIR into an enterprise contract. It also reduces drift across teams and projects.
Step 4: Build the Ingestion Backbone
We implement the ingestion layer to handle volume spikes, retries, and message sequencing. At the same time, we also design for fault tolerance so upstream systems remain stable during downstream disruption.
Therefore, the backbone supports continuous operations rather than best-effort delivery. This foundation allows the engine to scale safely as adoption grows.
Step 5: Implement Mapping and Validation
We build configurable mapping logic that translates HL7 content into clinically meaningful FHIR resources. We normalize units, codes, and timestamps to support consistent downstream use. In addition, we enforce validation against required fields and profiles before data is published.
This step protects data quality at the source. It also prevents issues from surfacing later in apps and analytics.
Step 6: Establish Observability and Audit Readiness
We instrument the platform for visibility across ingestion, transformation, and publication. We track lineage from HL7 message to FHIR resource, including mapping version and timestamps. As a result, teams can diagnose issues quickly and support audits without manual reconstruction.
This step reduces operational burden while increasing governance confidence.
Step 7: Roll Out in Phases
Finally, we roll out the engine in controlled phases. We start with high-value message types and validate performance, accuracy, and downstream behavior. At the same time, we then expand to additional sources and use cases, while keeping governance rules consistent.
This approach reduces disruption and builds trust. It also allows the platform to mature into a shared enterprise infrastructure.
HL7 to FHIR data transformation engines succeed when enterprises treat them as platforms, not projects. Our seven-step approach ensures that each engine is built for scale, safety, and long-term reuse. At Intellivon, we focus on making transformation reliable in production, governable over time, and expandable across new initiatives without repeated rework. This is how the engine becomes a stable foundation for interoperability, analytics, and enterprise growth.
Cost to Build an HL7 to FHIR Data Transformation Engine for Enterprises
At Intellivon, HL7 to FHIR data transformation engines are built as a regulated healthcare data infrastructure, not as conversion logic embedded inside interfaces. The focus remains on creating a durable transformation layer that operates safely across EHRs, apps, analytics platforms, and external partners.
When budget constraints exist, scope is refined deliberately. However, validation rules, provenance tracking, auditability, and clinical context preservation are never compromised. As a result, enterprises avoid remediation costs that typically surface after FHIR adoption scales.
In addition, predictable architecture limits rework as HL7 variants, FHIR profiles, and regulatory requirements evolve. Over time, this approach keeps total cost under control while protecting long-term ROI.
Estimated Phase-Wise Cost Breakdown
| Phase | Description | Estimated Cost Range (USD) |
| Discovery & Transformation Alignment | HL7 inventory, use cases, downstream consumers, success metrics | $5,000 – $10,000 |
| Governance & Safety Baseline | Validation rules, provenance model, and audit requirements | $6,000 – $12,000 |
| Reference Architecture & FHIR Modeling | Engine architecture, target FHIR resources, mapping strategy | $7,000 – $14,000 |
| HL7 Connectivity & Ingestion Setup | HL7 listeners, routing, and fault tolerance | $8,000 – $18,000 |
| Transformation & Normalization Pipelines | Parsing, mapping, normalization, error handling | $7,000 – $15,000 |
| FHIR Publishing & Access Controls | Governed APIs, throttling, and downstream access | $6,000 – $12,000 |
| Observability & Audit Instrumentation | Logging, lineage, dashboards | $4,000 – $9,000 |
| Testing & Validation Readiness | Functional, performance, and compliance testing | $3,000 – $7,000 |
| Deployment & Scale Readiness | Cloud or hybrid deployment, tuning | $4,000 – $8,000 |
Total initial investment: $50,000 – $150,000
Ongoing maintenance and optimization: ~15–20% of initial build per year
Hidden Costs Enterprises Should Plan For
Even well-scoped HL7 to FHIR programs experience pressure when indirect costs are overlooked. Therefore, planning for these early protects both budgets and delivery timelines. In addition, these costs rise faster when transformation logic is fragmented across systems.
Common hidden cost areas include:
- Mapping rework as new HL7 variants appear
- Compliance effort tied to audits and data accuracy reviews
- Governance overhead for transformation changes and exceptions
- Infrastructure growth from rising message volumes
- Operational effort for monitoring and incident response
- Change management across IT, clinical, and data teams
Best Practices to Avoid Budget Overruns
Cost control depends on architectural discipline from the start. Therefore, design decisions must reduce future rework. In addition, the engine must be built for change, not one-time delivery. As a result, expansion remains predictable.
Proven practices include:
- Start with a clear HL7-to-FHIR use case map
- Embed validation and auditability into the core pipeline
- Use configurable, versioned mapping logic
- Normalize data early to avoid repeated downstream cleanup
- Maintain observability across throughput and errors
- Design for evolving FHIR profiles and regulations
The cost of an HL7 to FHIR data transformation engine depends on governance depth, data variability, and scale expectations. However, the right structure prevents repeated remediation and reintegration costs.
Conclusion
HL7 to FHIR data transformation engines now sit at the center of enterprise healthcare modernization. As interoperability expands, consistency and safety determine whether data creates value or risk.
When built as governed infrastructure, these engines protect clinical meaning, support analytics, and scale digital initiatives without repeated rework. Enterprises that invest early avoid fragmentation later and create a foundation that grows with regulation, technology, and care models.
Build an HL7 to FHIR Transformation Engine With Intellivon
At Intellivon, HL7 to FHIR transformation engines are built as a regulated healthcare data infrastructure, not as conversion logic layered onto interfaces. The focus stays on safety, governance, and durability from day one.
This approach allows enterprises to modernize legacy HL7 data without disrupting live clinical operations. As FHIR adoption expands, transformation remains stable, auditable, and reusable.
As data flows extend across apps, analytics platforms, and external partners, centralized control becomes essential. Intellivon’s engines ensure transformation scales without fragmentation, reintegration, or compliance drift.
Why Partner With Intellivon?
- Enterprise-grade HL7 to FHIR architecture designed for high-volume, regulated healthcare environments, supporting consistent transformation across hospitals, regions, and care networks
- Proven delivery of transformation platforms that remain reliable under real production load, including complex HL7 variants, evolving FHIR profiles, and expanding downstream consumers
- Compliance-by-design implementation with built-in validation, provenance tracking, and audit readiness, reducing regulatory exposure as FHIR app access and data reuse increase
- Secure, modular infrastructure supporting cloud, hybrid, and on-prem deployments, allowing enterprises to align transformation strategy with existing IT and security models
- AI-ready data foundations with observability, monitoring, and controlled automation, ensuring transformed data can safely support analytics, automation, and advanced decision systems
Book a strategy call to explore how Intellivon can help you build and scale an HL7 to FHIR transformation engine with control, resilience, and long-term enterprise value.
![]()
FAQs
Q1. What is an HL7 to FHIR data transformation engine?
A1. An HL7 to FHIR data transformation engine converts legacy HL7 messages into structured FHIR resources. It also validates, normalizes, and governs data before it is shared. This ensures clinical data remains accurate and reusable across apps, analytics, and enterprise workflows.
Q2. Why do enterprises need HL7 to FHIR transformation engines?
A2. Enterprises need these engines because HL7 still runs core operations while FHIR powers modern platforms. Without a centralized transformation layer, data becomes inconsistent and risky to reuse. Transformation engines provide control, scale, and auditability as interoperability expands.
Q3. Is the HL7 to FHIR transformation just a one-time integration?
A3. No. HL7 to FHIR transformation is an ongoing enterprise capability. Data structures, regulations, and use cases change over time. A transformation engine allows enterprises to adapt without rebuilding integrations repeatedly or disrupting live systems.
Q4. How do HL7 to FHIR transformation engines support compliance and audits?
A4. These engines enforce validation rules, preserve provenance, and maintain transformation logs. As a result, enterprises can trace how data was converted and shared. This visibility simplifies audits and reduces compliance risk as FHIR adoption grows.
Q5. How long does it take to build an HL7 to FHIR data transformation engine?
A5. Timelines vary based on scope and data complexity. Most enterprise implementations are delivered in phases over several weeks. Starting with high-value message types allows organizations to see impact early while expanding safely over time.