Key Takeaways:
- Rule-based fraud systems generate 85 to 99 % false positive rates and fall behind modern attackers.
- Effective ML fraud systems score risk before authorization using behavioral signals and continuous feedback loops from confirmed fraud outcomes.
- False positive reduction is a revenue strategy with calibrated thresholds and behavioral personalization.
- Build costs range from $10,000 for a single-use case MVP to $80,000 for a real-time multi-channel enterprise system, with ongoing optimization adding 15 to 25% annually.
- How Intellivon builds production-grade ML fraud prevention systems your enterprise fully owns, with event-driven pipelines, adaptive model architectures, and compliance-ready explainability from day one.
Fintech leaders are sitting on a problem that quietly bleeds revenue every quarter. Chargebacks pile up, synthetic identities slip through onboarding, and account takeovers go undetected until a customer calls in. This is the fundamental flaw in reactive fraud management. Evidence-based approaches wait for evidence before acting.
However, in high-velocity payment environments, evidence only surfaces after a transaction settles, which in most cases means losses are already locked in. Investigating fraud after the fact is expensive. Prevention demands a system that scores risk before authorization, not after it.
This is precisely where machine learning changes the calculus. Unlike static rule engines that flag only known patterns, ML models learn the behavioral baseline of every user, device, and transaction flow. As a result, the system intercepts threats at the point of entry rather than discovering them in a reconciliation report the following morning. In addition, because these models continuously learn from new data, they adapt to emerging attack vectors without waiting for a human to rewrite detection logic.
At Intellivon, we build production-grade ML fraud prevention systems for enterprises operating across fintech, payments, insurance, and digital commerce. This blog draws directly from the architecture decisions, trade-offs, and real-world lessons that come with shipping these systems at scale.

Why Are Rule-Based Fraud Systems Failing Today?
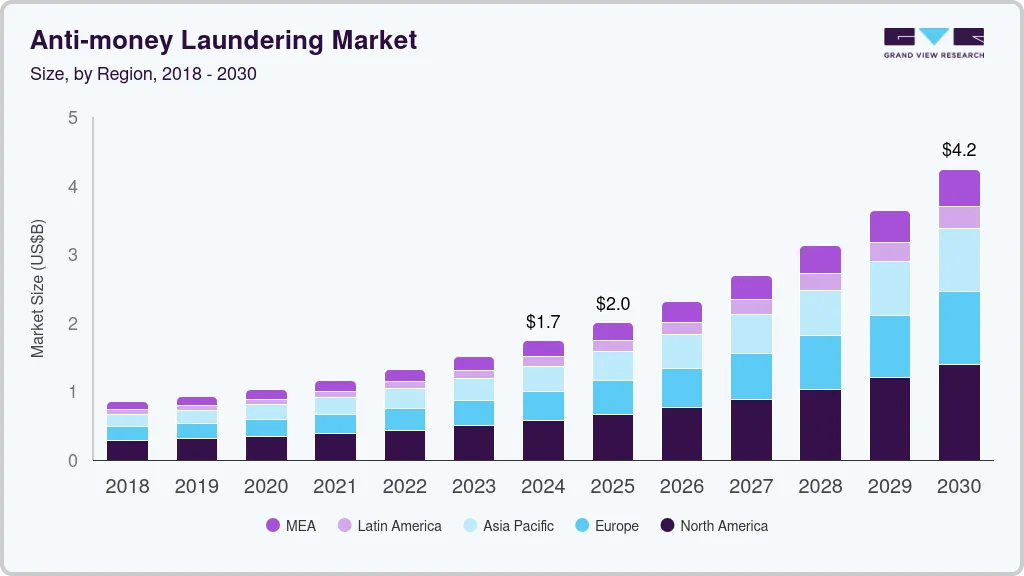
The global fraud prevention and AML market is growing at a CAGR of 15 to 20% over the next five years. Digital payments are scaling fast, regulations are tightening, and fraud is becoming significantly more sophisticated.
Yet a large share of financial institutions still run on legacy rule-based systems. And those systems are losing the battle.
1. Stagnant Logic vs. Evolving Fraud
Rule-based systems operate on fixed “if-then” thresholds. They assume fraud patterns stay stable over time. In reality, however, modern attackers study those thresholds and deliberately stay just under them.
They automate attacks at scale and adjust behavior the moment a rule is deployed. Consequently, the system is always one step behind.
2. Exploding False Positives
Industry data shows that 85 to 99% of alerts generated by rule-based engines are false positives. Around 15% of transactions get flagged for review, and over 70% of those turn out to be legitimate.
As a result, compliance teams drown in noise, investigations slow down, and operational costs climb 30 to 40% year-over-year. This is alert fatigue at enterprise scale.
3. Rule Saturation and Mounting Complexity
Organizations respond by adding more rules to chase new fraud patterns. However, this creates a tangled, overlapping ruleset that is difficult to maintain.
Performance degrades, agility drops, and every product or regulatory change becomes a larger engineering effort than it should be.
4. The Competitive Cost of Getting It Wrong
Static rules frequently block legitimate high-value or cross-border transactions. Therefore, conversion suffers, and customer trust erodes.
In contrast, behavior-driven ML engines improve approval rates for genuine transactions while simultaneously containing risk. Fraud control, in that case, becomes a competitive advantage rather than an operational tax.
The market has already moved toward hybrid AI-augmented platforms. For enterprises still running rule-only systems, the question is no longer whether to evolve but how fast.
What Does an ML Fraud-Prevention System Do?
An ML fraud-prevention system is an intelligent digital shield that learns from your data. It automatically identifies and stops dishonest transactions by recognizing patterns humans often miss. Instead of following rigid rules, it evolves constantly to protect revenue and customer trust.
This technology transforms security into a scalable, proactive defense that adapts to new threats in real time, ensuring growth without the friction of manual oversight.
An ML fraud-prevention system evaluates every transaction in real time using behavioral signals, device intelligence, and adaptive models. It scores risk before authorization, links identities dynamically, and continuously learns from confirmed fraud to improve future detection accuracy.
1. Real-Time Scoring Before Transaction Authorization
The system assigns a risk score to every transaction the moment it is initiated. It analyzes signals like transaction amount, location, device, and user history simultaneously. As a result, high-risk transactions are flagged or blocked before funds ever move.
2. Linking Users, Devices, and Transactions Dynamically
Fraud rarely happens in isolation. The system maps relationships between user accounts, devices, IP addresses, and payment methods in real time. Consequently, if one compromised account shares a device with five others, the system surfaces that connection instantly.
3. Detecting Anomalies Across Behavioral Patterns
Every user has a normal behavioral fingerprint, such as how they type, where they log in, and what they typically spend. When something deviates from that baseline, however subtle, the system flags it immediately. Furthermore, this applies across sessions, not just individual transactions.
4. Continuously Learning from Fraud Feedback Loops
When fraud is confirmed, that outcome feeds directly back into the model. The system, therefore, gets sharper over time, adjusting to new tactics without manual rule updates. In addition, it reduces false positives as it learns what legitimate behavior actually looks like.
5. Automating Decisions Across Risk-Based Workflows
Not every flagged transaction needs a human reviewer. The system routes decisions automatically based on risk score thresholds. Low-risk cases are approved instantly, mid-range cases trigger step-up authentication, and high-risk cases are blocked or escalated. As a result, investigation teams focus only on cases that genuinely need attention.
6. Adapting Risk Profiles Across Lifecycle Stages
A new customer carries different risk signals than a long-standing account holder. The system consequently adjusts its scoring logic based on where a user sits in their lifecycle. Therefore, friction is applied where it is necessary and removed where trust has already been established.
An ML fraud-prevention system systematically eliminates the conditions that allow fraud to survive. For enterprises serious about protecting revenue, it is the difference between chasing losses and preventing them.
Which Fraud Problems Should You Solve First?
Not every fraud problem carries equal weight. Some drain revenue quietly over months. Others trigger regulatory scrutiny or destroy customer trust overnight. Therefore, prioritization is a strategic decision. The right starting point depends on where your platform bleeds the most.
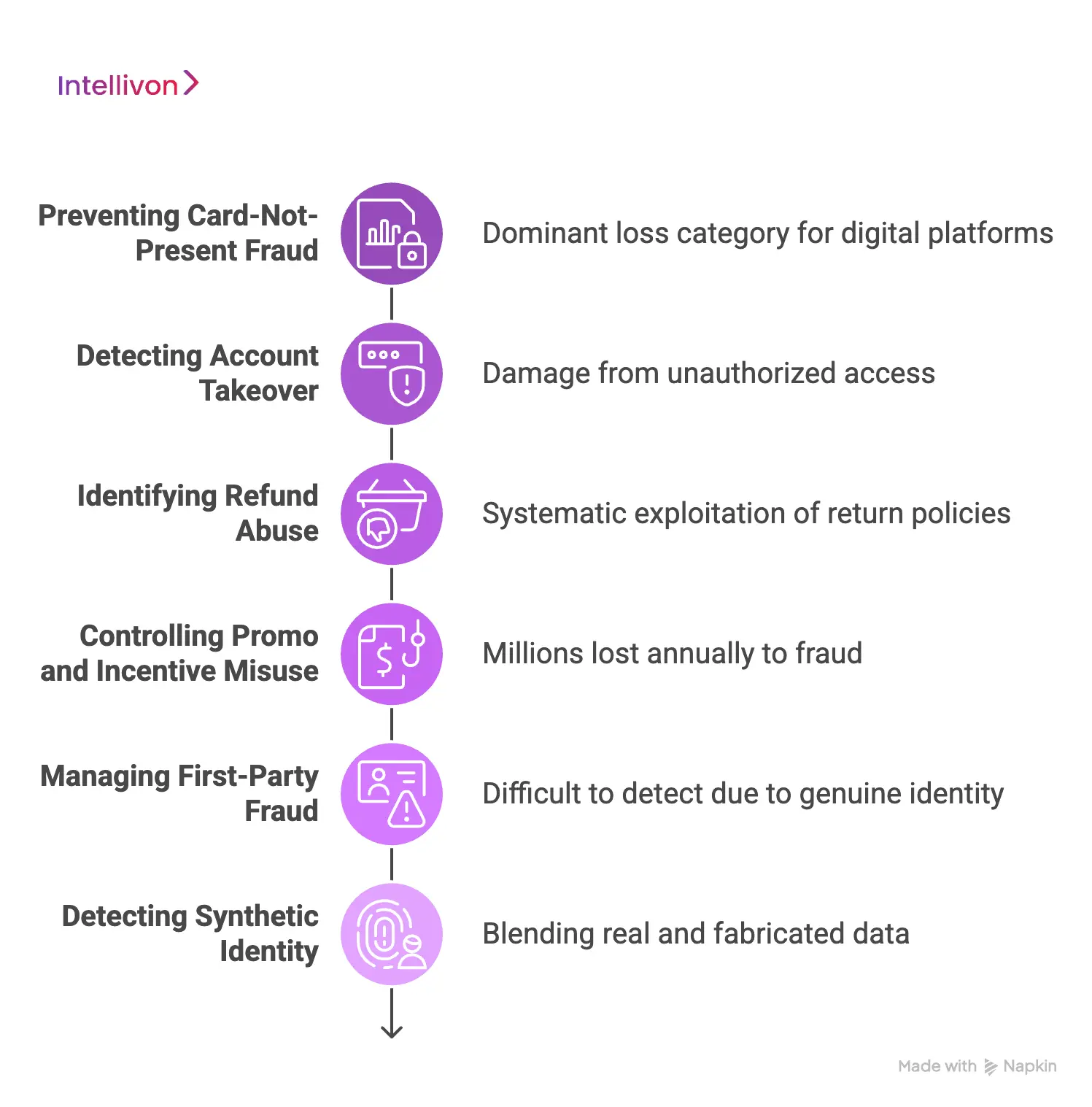
1. Preventing Card-Not-Present Fraud
Card-not-present fraud is the dominant loss category for digital payment platforms. Since physical card verification is absent, attackers exploit stolen credentials at scale.
ML systems counter this by scoring device trust, behavioral patterns, and transaction context simultaneously at the moment of authorization.
2. Detecting Account Takeover
Account takeover happens when a fraudster gains control of a legitimate user’s account. It is particularly damaging because the activity initially appears genuine.
However, ML models detect subtle shifts in login behavior, device fingerprints, and session patterns that signal unauthorized access before damage occurs.
3. Identifying Refund Abuse
Refund abuse is frequently underestimated as a fraud category. In reality, organized groups exploit return policies systematically, generating significant losses.
ML systems identify refund velocity patterns and cross-reference them against purchase history and device clusters to flag serial abusers.
4. Controlling Promo and Incentive Misuse
Promotional fraud costs platforms millions annually. Fraudsters create multiple accounts to claim referral bonuses, discount codes, or free trials repeatedly.
Consequently, ML models link accounts through shared devices, IP addresses, and behavioral similarities to detect coordinated misuse at scale.
5. Managing First-Party Fraud
First-party fraud occurs when real customers dispute legitimate transactions to recover funds. It is difficult to detect because the identity is genuine.
However, ML systems analyze dispute history, transaction patterns, and behavioral signals to distinguish honest chargebacks from deliberate abuse.
6. Detecting Synthetic Identity
Synthetic identity fraud blends real and fabricated personal data to create believable profiles. These identities build credit histories slowly before executing large-scale losses.
ML graph models, however, surface hidden connections between accounts that share fragments of real data, exposing these networks before they mature.
Identifying where your platform is most exposed is the foundation of an effective ML fraud strategy. Solve the highest-impact problems first, and every subsequent layer of defense becomes significantly easier to build.
What Data Powers an Enterprise Fraud ML System?
An enterprise ML fraud system runs on layered data inputs, including transaction events, device signals, behavioral patterns, identity verification, and network indicators. The quality, freshness, and integration of these data sources directly determine how accurately the system detects fraud without generating excessive false positives.
The model is only as strong as the data feeding it. Many fraud systems underperform not because of poor algorithms, but because of incomplete or poorly structured data pipelines. Therefore, before selecting models, enterprises must first design a data architecture that captures the right signals at the right time.
1. Designing Event Data Streams
Every transaction generates a stream of metadata beyond just the amount and merchant. Timestamps, payment method, channel, currency, and processing route all carry risk signals.
Consequently, streaming pipelines must capture and structure this data in real time so the model always scores against fresh, complete inputs.
2. Capturing Device Fingerprints
Device intelligence is one of the strongest fraud indicators available. The system collects hardware attributes, browser configurations, operating system details, and installed fonts to build a unique device fingerprint.
In addition, session-level signals like interaction speed and navigation patterns add another layer of behavioral context.
3. Using Geo-Based Anomaly Indicators
IP reputation, VPN usage, proxy detection, and geolocation consistency all reveal important risk signals. However, these indicators must be interpreted in context.
A legitimate user traveling internationally will trigger geo-anomalies, and the system must weigh network signals against historical travel patterns before escalating.
4. Integrating KYC Verification Data
Identity data anchors the risk profile of every user. Furthermore, integrating KYC verification outcomes, document authenticity scores, and watchlist screening results allows the model to assess trust levels at onboarding and revisit them dynamically as behavior evolves over time.
5. Handling Delayed Labels
Fraud labels rarely arrive instantly. Chargebacks and dispute resolutions can take weeks, creating a labeling lag that distorts model training.
As a result, enterprises must build pipelines that retroactively attach confirmed fraud labels to historical transaction records and trigger model retraining cycles accordingly.
6. Tracking Behavioral Data
How a user navigates a platform reveals as much as what they transact. Scroll depth, tap pressure, typing cadence, and session duration collectively form a behavioral fingerprint.
Consequently, deviations from established patterns surface suspicious activity even when transaction-level signals appear normal.
Strong data architecture is the commercial foundation of fraud prevention. Without clean, real-time, and layered data inputs, even the most sophisticated ML model will consistently underperform.
How Should the Fraud Data Pipeline Be Designed?
A fraud data pipeline for ML systems requires event-driven ingestion, normalized data structures, reliable labeling mechanisms, and a centralized feature store. These components work together to ensure the model receives consistent, high-quality inputs during both training and live inference, which directly determines detection accuracy and system reliability.
Many enterprises invest heavily in model selection but underestimate pipeline design, and consequently suffer from stale features, inconsistent labels, and poor production performance. Therefore, getting the data infrastructure right is the prerequisite to everything else.
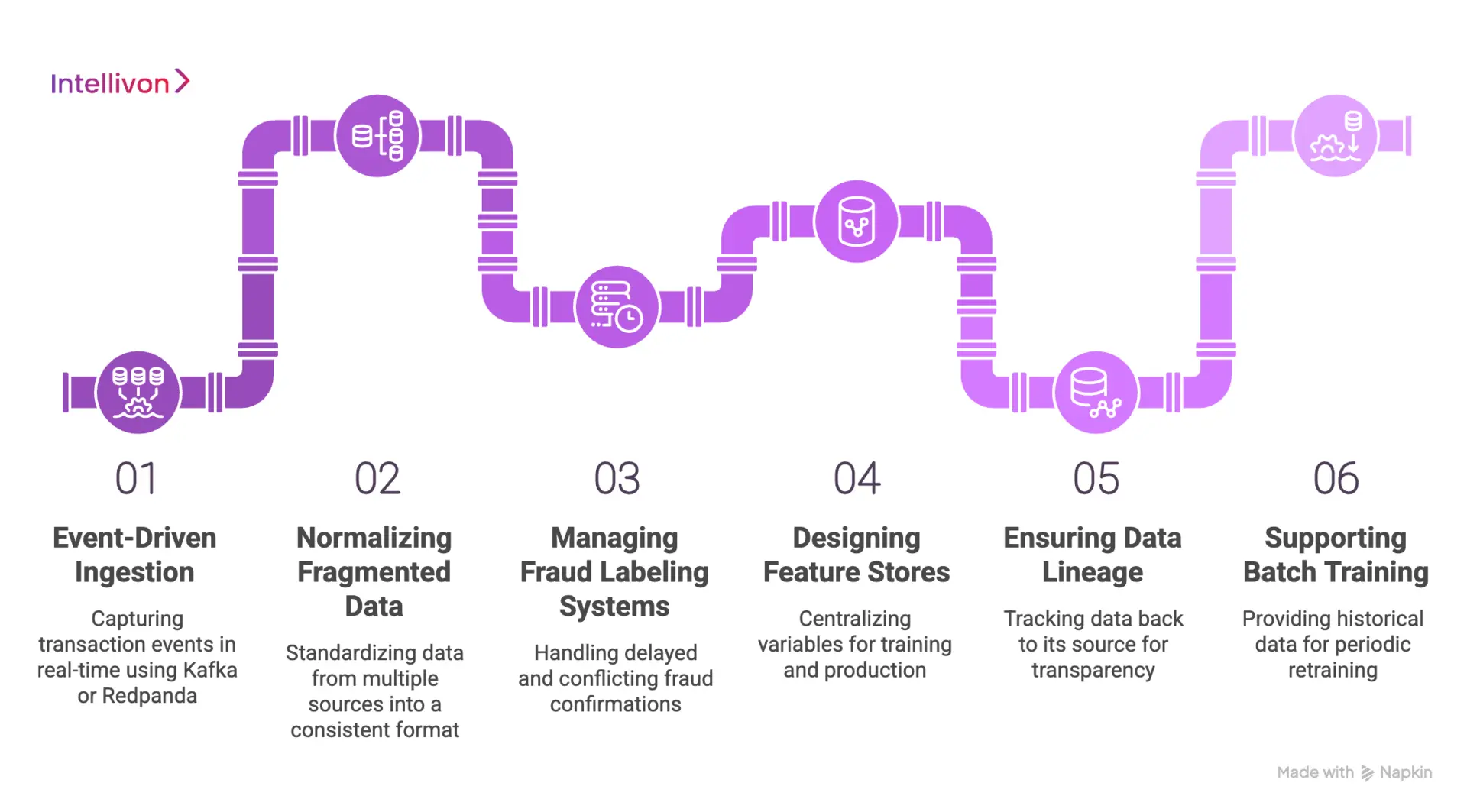
1. Building Event-Driven Pipelines
Traditional batch ingestion cannot support real-time fraud scoring. Instead, event-driven pipelines using tools like Apache Kafka or Redpanda capture and route transaction events the moment they occur.
As a result, the scoring engine always operates on live data rather than snapshots that are minutes or hours old.
2. Normalizing Fragmented Data
Enterprises typically pull data from multiple sources, including payment processors, CRM systems, and third-party identity providers. However, these sources rarely share consistent formats or field definitions.
Therefore, a normalization layer must standardize incoming data before it reaches the model, ensuring the system interprets signals consistently regardless of their origin.
3. Managing Fraud Labeling Systems
Labels are the ground truth that supervised models train on. Furthermore, because fraud confirmations arrive late through disputes and chargebacks, the labeling system must handle delayed, partial, and sometimes conflicting signals.
Building a robust label management pipeline ensures that confirmed fraud events retroactively update training datasets without corrupting existing records.
4. Designing Feature Stores
A feature store centralizes the variables the model uses to score transactions. In addition, it eliminates the gap between training logic and production logic by ensuring both environments draw from identical feature definitions. Consequently, models behave in production exactly as they did during development.
5. Ensuring Data Lineage
Regulators and internal audit teams increasingly demand full visibility into how a fraud decision was reached. Therefore, every data point that influences a score must carry a traceable lineage back to its source.
This ensures explainability and simplifies compliance reporting significantly.
6. Supporting Batch Training
Despite operating in real time, fraud models still require periodic retraining on historical data to remain accurate. Consequently, the pipeline must support scheduled batch exports that feed clean, labeled datasets into the training environment without disrupting live scoring operations.
A well-designed data pipeline is what separates a fraud system that performs in demos from one that holds up in production. Build the infrastructure correctly from the start, and every model improvement compounds on a stable foundation.
How Do You Engineer High-Impact Fraud Features?
Engineering high-impact features is the process of converting raw data into meaningful signals that reveal criminal intent.
This phase determines the overall predictive power of your machine learning model by identifying hidden relationships within massive datasets.
1. Designing velocity features
Velocity features measure the frequency of specific actions over defined intervals. They are essential for spotting automated bot attacks or rapid-fire credit card testing.
By tracking how many times an account attempts a login or a purchase, you can identify high-velocity events that deviate from typical human behavior.
2. Computing time-window aggregations
Time-window aggregations provide the historical context necessary to judge a current action. You should calculate metrics like the average spend over the last hour versus the last thirty days.
- Short-term windows: Capture immediate surges in activity.
- Long-term windows: Establish a baseline for “normal” user behavior.
- Decay functions: Give more weight to recent events to reflect current habits.
3. Building graph features
Graph features map the connections between different entities like email addresses, IP addresses, and device IDs. Criminals often reuse infrastructure across multiple accounts.
Graph analysis helps you uncover these “fraud rings” by highlighting shared attributes that shouldn’t logically exist between unrelated users.
4. Updating real-time graph relationships
For a system to be effective, graph data must update as transactions occur. If five new accounts suddenly link to the same hardware ID, the system needs that information instantly.
Real-time updates ensure that once one node in a fraud network is identified, the entire cluster can be neutralized before it can withdraw funds.
5. Capturing behavioral biometrics
Behavioral biometrics analyzes how a user interacts with their device. This includes mouse movements, keystroke dynamics, and touch pressure.
These features are incredibly difficult for bots or remote attackers to mimic, providing a silent layer of authentication that does not interrupt the user experience.
6. Encoding transaction context
Contextual encoding involves translating categorical data into a format the model understands. This includes geographical distance between the billing and shipping address or the risk level associated with a specific merchant category.
Proper encoding ensures the model weighs these environmental factors heavily during its risk assessment.
7. Maintaining feature consistency
You must ensure that the features used during model training match those used in production. Any discrepancy between how data is calculated in the lab versus the live environment will lead to inaccurate risk scores.
A unified feature store is often the best strategic solution to guarantee this alignment.
By focusing on these sophisticated data points, your enterprise moves beyond surface-level checks. This deep-feature approach builds a resilient system that can anticipate and block evolving fraud tactics before they impact your bottom line.
Which ML Models Work Best in Fraud Systems?
Selecting the right model architecture is a balancing act between predictive accuracy and operational speed.
For an enterprise, the “best” model is one that maintains high precision while processing thousands of transactions per second. Different mathematical approaches serve distinct purposes in a layered defense strategy.
1. Selecting supervised models
Supervised learning is the backbone of most fraud detection because it learns from historical examples of confirmed fraud. Models like Random Forests and Gradient Boosted Trees are industry standards due to their ability to handle non-linear relationships.
- XGBoost and LightGBM: These offer high performance and handle missing data efficiently.
- Deep Neural Networks: Useful for identifying complex, deep-layered patterns in massive datasets.
- Logistic Regression: Often kept as a baseline for its extreme speed and interpretability.
2. Using anomaly detection
Fraud is often a “needle in a haystack” problem where previous examples of a new attack do not exist. Anomaly detection uses unsupervised learning to flag anything that looks different from the norm.
This is vital for catching “zero-day” fraud or sophisticated account takeovers where the attacker uses a clean history to bypass supervised filters.
3. Combining models through ensemble architectures
No single model is perfect, so leaders should look toward ensemble methods that combine several algorithms. By stacking different models, you can cancel out the weaknesses of one with the strengths of another.
For instance, a system might use one model to check for credit card theft and another to monitor for bot activity, then average their scores for a final decision.
4. Applying online learning for adaptive fraud detection
Traditional models are static and require periodic retraining, but online learning allows the system to update its parameters in real time. As new fraud trends emerge, the model adjusts its weights without a full redeploy.
This adaptability is a competitive advantage, as it shrinks the window of vulnerability between a new threat appearing and the system learning to stop it.
5. Handling class imbalance in fraud datasets
In a typical enterprise, 99% of transactions are legitimate. This imbalance can confuse a model into thinking it should always guess “not fraud” to achieve high accuracy.
- SMOTE: Synthetically creating more fraud examples to balance the training set.
- Under-sampling: Reducing the number of legitimate examples to make the fraud signals louder.
- Cost-sensitive learning: Penalizing the model more heavily for missing a fraud case than for a false alarm.
6. Choosing models based on latency and scale constraints
A model that takes five seconds to run is useless in a checkout flow. Decision makers must prioritize models that fit within their technical “latency budget,” which is often under 200 milliseconds.
- Feature complexity: More features increase accuracy, but slow down the calculation.
- Model size: Larger models require more memory and compute power.
- Hardware acceleration: Using specialized chips like TPUs can speed up deep learning inferences.
Choosing the right model is a business decision that affects customer experience. The goal is to build a system that is invisible to the honest user while remaining an impenetrable wall for the fraudster. This technical maturity ensures your platform remains both secure and highly profitable.
How Do You Reduce False Positives at Scale?
Reducing false positives in ML fraud prevention requires calibrated thresholds, personalized risk scoring, and continuous model feedback. Enterprises that segment risk by user behavior and business value consistently achieve higher approval rates without increasing fraud exposure, turning false positive reduction into a direct revenue optimization lever.
False positives are not just an operational inconvenience. Every legitimate transaction incorrectly blocked is lost revenue, a frustrated customer, and in competitive markets, a reason to switch platforms. Therefore, reducing false positives at scale is as commercially important as catching actual fraud.
1. Calibrating Decision Thresholds by Risk Segments
A single global threshold treats a first-time user identically to a long-standing account holder. That approach generates unnecessary friction.
Instead, thresholds should be calibrated separately for distinct risk segments based on transaction type, channel, and user tenure. Consequently, the system applies appropriate scrutiny without over-blocking legitimate activity.
2. Personalizing Risk Scoring Using User Behavior
Behavioral personalization allows the model to score each transaction against that specific user’s established patterns rather than a population average.
Therefore, an unusually large purchase from a high-frequency buyer carries far less risk than the same transaction from a dormant account. Personalization significantly reduces false alerts on genuine edge cases.
3. Embedding Explainability into Decision Pipelines
When analysts cannot understand why a transaction was flagged, they default to manual overrides that undermine the system. In addition, explainability tools like SHAP values surface the specific signals driving each score.
As a result, review teams make faster, more confident decisions, and the model benefits from higher-quality human feedback.
4. Separating High-Value Users from Risky Signals
High-value customers generate a disproportionate share of revenue. However, their transaction behavior often triggers risk signals, such as large amounts or international activity, that standard models misread.
Therefore, the system must apply a separate scoring logic for premium segments that weighs lifetime value alongside transactional risk before making a decision.
5. Continuously Tuning Models
Every confirmed legitimate transaction that was previously flagged is a training signal. Consequently, feeding reviewer outcomes directly back into the model allows it to self-correct over time.
Furthermore, automated retraining cycles ensure threshold adjustments reflect current fraud patterns rather than conditions from months prior.
6. Balancing Fraud Prevention
Fraud prevention and revenue growth are not opposing forces. In fact, approval rate optimization is a discipline in itself, involving model ensembles, challenger testing, and segment-level performance tracking.
Enterprises that treat approval rate as a primary metric alongside fraud rate consistently outperform those optimizing for detection alone.
False positive reduction is ultimately a revenue strategy dressed as a risk problem. Enterprises that master this balance protect income from two directions simultaneously, blocking fraud while keeping legitimate customers transacting.
What Integrations Does the System Require?
A fraud system cannot operate in a vacuum. To be effective, it must act as a central nervous system that communicates with your entire technical stack.
These integrations ensure that data flows seamlessly into the model and that the resulting decisions reach the right departments in milliseconds.
1. Integrating with payment gateways
The connection to your payment gateway is the most critical touchpoint for financial security. This integration allows the fraud system to intercept a transaction before it is sent to the bank for authorization.
If the risk score is too high, the system can trigger a “hard block” or request a secondary authentication step. This immediate feedback loop prevents the loss of funds and avoids the expensive chargeback fees that plague unprotected merchants.
2. Connecting identity verification and KYC systems
Integrating with Know Your Customer (KYC) platforms adds a layer of trust during user onboarding. By syncing these systems, your fraud model can cross-reference a user’s digital behavior with their verified legal identity.
This is particularly useful in fintech, where you must prove that the person behind the screen matches the government-issued documents provided. It creates a robust barrier against synthetic identity fraud and automated bot registrations.
3. Linking CRM and fraud operations platforms
Fraud affects the customer relationship. By linking the fraud system to your CRM, support teams can see if a customer’s account was locked due to a security flag.
This transparency allows your staff to handle high-value customers with more care during a manual review process. It ensures that security measures do not accidentally damage the long-term lifetime value of your legitimate users.
4. Using third-party fraud intelligence
No single enterprise has enough data to see every emerging threat. Integrating with external intelligence feeds allows your system to benefit from global security trends.
These services provide lists of known compromised IP addresses, leaked passwords, and malicious device fingerprints. By ingesting this external data, your system can block known attackers even if they have never visited your platform before.
5. Integrating with data warehouses
The long-term health of an ML model depends on access to historical data. A direct link to your data warehouse, such as BigQuery or Snowflake, enables the system to pull months of transaction history for retraining.
This integration ensures that the model stays relevant as user behavior changes over seasons or years. It also simplifies the process of auditing the system for compliance and performance tracking.
6. Alerting and escalation notification systems
When the system detects a high-priority threat that requires human intervention, it must notify the right people immediately. Integrations with tools like Slack, PagerDuty, or internal dashboards ensure that your fraud operations team can act fast.
Effective alerting logic prevents “alert fatigue” by only escalating cases that truly deviate from the norm. This streamlined communication keeps your response times low and your operational costs predictable.
Successful integration turns a standalone tool into a strategic asset. By connecting these diverse data sources, you create a comprehensive defense that protects your infrastructure from every possible angle. This interconnectedness is what separates a basic filter from a true enterprise-grade fraud prevention ecosystem.
How We Build A Machine Learning Fraud Prevention System
Building an enterprise-grade defense requires a move away from off-the-shelf software toward a custom-engineered ecosystem. Our approach focuses on creating a system that is deeply integrated into your unique business logic, ensuring that security scales alongside your transaction volume.
We treat fraud prevention as a continuous engineering discipline rather than a one-time installation.
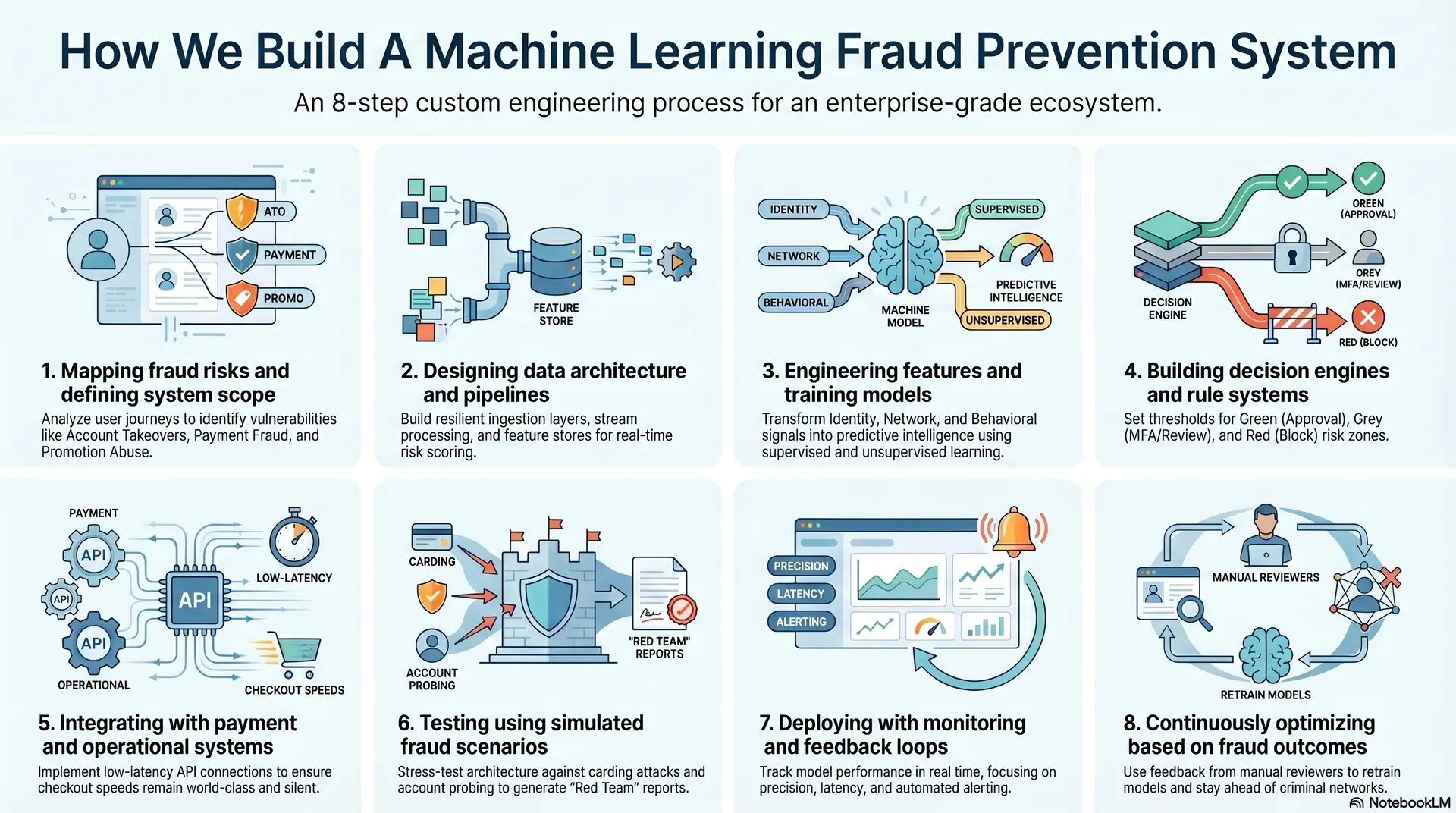
1. Mapping fraud risks and defining system scope
We start by identifying the specific vulnerabilities within your platform. Not every business faces the same threats, so a one-size-fits-all approach often fails. We analyze your user journey to find where a bad actor might strike.
This stage involves deep consultations with your internal stakeholders to align security goals with business KPIs.
- Account Takeovers (ATO): Protecting user credentials and session integrity from unauthorized access.
- Payment Fraud: Identifying stolen credit cards, silver-bullet attacks, or unauthorized bank transfers.
- Promotion Abuse: Preventing the exploitation of sign-up bonuses, referral links, or discount codes.
- Regulatory Scope: Ensuring the system meets regional AML (Anti-Money Laundering) and KYC (Know Your Customer) requirements.
2. Designing data architecture and pipelines
Data is the fuel for machine learning. We build resilient pipelines that can ingest high-velocity data from multiple sources without lag.
This architecture must handle both real-time streams for immediate decisions and batch processing for long-term model training. We prioritize data integrity to ensure the models never learn from corrupted or incomplete information.
| Component | Function | Strategic Value |
| Ingestion Layer | Collects raw event data | Captures every digital footprint from apps and the web |
| Stream Processing | Processes data in motion | Enables sub-second risk scoring for live checkouts |
| Feature Store | Stores calculated signals | Ensures consistency between training and production |
| Cold Storage | Archives historical logs | Provides the baseline for audit trails and retraining |
3. Engineering features and training models
This is where we transform raw data into predictive intelligence. We create hundreds of features that describe user behavior, device health, and network reputation. Next, our experts train an ensemble of models to recognize the subtle markers of fraud.
By using a mix of supervised and unsupervised learning, we ensure the system can catch both known attacks and brand-new threats.
We focus on specific signal categories:
- Identity Signals: Email age, domain risk, and phone number carrier reputation.
- Network Signals: Proxy detection, VPN usage, and IP geofencing.
- Behavioral Signals: Typing rhythm, navigation speed, and session duration.
4. Building decision engines and rule systems
A model provides a score, but the decision engine provides the action. We build a flexible layer that allows you to set specific thresholds for different business scenarios.
This system combines the predictive power of ML with the transparency of business rules. You maintain full control over the final outcome, allowing for manual overrides when necessary.
- Green Zone: Automatic approval for scores below 10 (Low Risk).
- Grey Zone: Trigger MFA or manual review for scores between 11 and 70 (Medium Risk).
- Red Zone: Immediate block and account freeze for scores above 71 (High Risk).
5. Integrating with payment and operational systems
We ensure the fraud system communicates perfectly with your existing tech stack. This involves low-latency API connections to your payment gateways and seamless hooks into your customer support dashboards.
Our goal is to make the system a silent partner that protects the transaction without the customer ever knowing it is there. We minimize API overhead to ensure your checkout speed remains world-class.
6. Testing using simulated fraud scenarios
Before going live, we stress-test the architecture using synthetic fraud data. We simulate various attack vectors, such as massive bot-driven carding attacks or slow-and-steady account probing.
This validation phase ensures the models are accurate and that the infrastructure can handle peak traffic loads without failing. We provide detailed “Red Team” reports showing exactly how the system deflected these simulated threats.
7. Deploying with monitoring and feedback loops
Deployment is just the beginning. We implement comprehensive monitoring to track model performance in real time. At the same time, our experts look for model drift, which happens when fraud patterns change and the system’s accuracy begins to dip.
- Precision Tracking: Monitoring the ratio of true fraud caught versus false alarms.
- Latency Monitoring: Ensuring the system stays within the 200ms decision window.
- Alerting: Automated notifications to your security team if a sudden spike in high-risk scores occurs.
8. Continuously optimizing based on fraud outcomes
The most important part of our process is the feedback loop. When a manual reviewer confirms a case of fraud, that information is fed back into the system. This labeled data allows the model to learn from its mistakes and get smarter every day.
We maintain a cycle of constant retraining to ensure your platform stays one step ahead of organized criminal networks.
This rigorous methodology ensures that your investment results in a high-performance asset. By treating every step with technical precision, we build systems that do more than just block transactions. They provide the confidence your enterprise needs to expand into new markets and offer new services without fear.
What Does It Cost to Build a Fraud ML System?
Building a machine-learning fraud prevention system is not a fixed-cost project. It depends on how complex your fraud patterns are, how many systems you integrate, and how real-time your decisions need to be.
At Intellivon, we approach cost as a function of architecture depth, data maturity, and decision latency requirements, and not just features.
Total Cost Range Based on System Scope
| Build Scope | Timeline | Estimated Cost |
| MVP (Single fraud use case) | 2–3 months | $10,000 – $25,000 |
| Mid-Scale System (Multi-signal detection) | 3–5 months | $25,000 – $50,000 |
| Enterprise System (Real-time + multi-channel) | 5–8 months | $50,000 – $80,000 |
Note: These ranges assume a production-ready system with real-time scoring, not just model prototypes.
Cost Breakdown Across System Components
| Component | % of Total Cost | What Drives Cost |
| Data pipelines & infrastructure | 20–25% | Real-time ingestion, data cleaning, storage |
| Feature engineering & ML models | 20–25% | Model complexity, training pipelines |
| Decision engine & orchestration | 15–20% | Rule engine, scoring logic, workflows |
| Integrations & APIs | 15–20% | Payment gateways, KYC, third-party tools |
| Monitoring & compliance layers | 10–15% | Logging, audit, explainability |
Key Factors That Increase Development Cost
Fraud systems become expensive when complexity increases in specific areas:
- Real-time decision requirements (sub-second latency)
- Multiple integrations (payments, KYC, CRMs, fraud tools)
- Cross-channel fraud detection (web, mobile, payments)
- High transaction volumes require a scalable architecture
- Regulatory and compliance requirements (auditability, data laws)
The more your system moves from rule-based checks → intelligent orchestration, the more investment is required.
Ongoing Costs for Model Optimization and Monitoring
Fraud systems are not “build once, deploy forever.” You need continuous investment in:
- Model retraining with new fraud patterns
- Feature updates as attacker behavior evolves
- Monitoring for model drift and performance drops
- Updating rules and decision thresholds
Typically, 15–25% of the initial build cost annually goes into maintaining system performance.
ROI: Why Fraud ML Systems Pay for Themselves
The real question is loss prevention and revenue recovery. A well-designed fraud system delivers ROI through:
- Reduced fraud losses and chargebacks
- Higher approval rates (fewer false declines)
- Lower manual review costs
- Faster transaction processing
For most fintech and payment platforms, even a 1–2% improvement in approval rate or fraud reduction offsets the entire system cost within months.
The difference between a basic fraud tool and an enterprise ML system is control, adaptability, and long-term cost efficiency.
That’s where how you build the system matters.
Conclusion
Building an ML fraud-prevention system is a long-term commercial decision. Every layer, from data pipelines to model feedback loops, compounds into a system that gets sharper, faster, and more accurate over time.
Fraud will keep evolving. Therefore, the only sustainable response is a system that evolves with it. Enterprises that build that capability today are not just protecting revenue. Instead, they are building a structural advantage that compounds quietly and consistently.
Why Build Your Fraud System With Intellivon?
Building a machine-learning fraud prevention system is not just about deploying models—it requires designing a system where every transaction is evaluated in real time, across risk, behavior, identity, and compliance.
At Intellivon, we build fraud prevention infrastructure where machine learning is embedded directly into the decisioning layer, enabling faster approvals, lower fraud exposure, and scalable protection across payment and user workflows.
Our approach ensures your platform can operate in real-world conditions, handling high transaction volumes, evolving fraud strategies, and regulatory complexity without compromising performance or user experience.
A. Designing Real-Time Fraud Decision Architectures
Fraud prevention is a real-time problem. We design systems where every transaction is scored and acted upon instantly within the transaction lifecycle.
- Low-latency scoring pipelines: Built for sub-second fraud detection without impacting transaction flow
- Event-driven architecture: Streaming systems process high-volume fraud signals in real time
- Unified decision engines: Fraud, identity, and behavioral signals converge into one logic layer
- Inline decisioning: Approve, block, or step-up actions happen before transaction completion
This ensures fraud detection happens during the transaction, and not after financial loss occurs.
B. Building Multi-Layered ML Fraud Detection Systems
Effective fraud prevention requires more than a single model. We design layered systems that combine multiple detection strategies.
- Hybrid model architectures: Supervised, unsupervised, and graph-based models work together
- Feature-rich pipelines: Behavioral, device, and transaction signals drive model accuracy
- Adaptive learning systems: Models continuously evolve based on new fraud patterns
- Decision orchestration layers: Rules and ML models operate together for precision control
This allows your system to detect both known fraud patterns and emerging attack strategies.
C. Embedding Explainability and Compliance Into the Core
Fraud systems must be transparent, auditable, and regulator-ready from day one. We build compliance into the architecture, not as an afterthought.
- Transaction-level explainability: Every decision is backed by interpretable model outputs
- Continuous audit trails: All actions are logged for regulatory review and dispute handling
- Standards alignment: Systems are designed for PCI DSS, GDPR, and regional compliance
- Access governance: Role-based controls ensure secure handling of sensitive data
This ensures your fraud system remains compliant without slowing down real-time operations.
D. Integrating Fraud Intelligence Across Your Ecosystem
Fraud prevention only works when it connects across your entire platform. We design integration layers that unify your fraud stack.
- API-first architecture: Enables seamless integration with payments, KYC, and CRM systems
- Gateway-level connectivity: Direct integration with processors and financial systems
- Unified risk intelligence: Centralized view of fraud signals across all channels
- Phased system evolution: Upgrade your fraud stack without disrupting operations
This allows your fraud prevention system to operate as a unified intelligence layer, not a disconnected tool.
At Intellivon, we help you translate your fraud risks, transaction flows, and system complexity into a clear machine-learning architecture and execution roadmap.
Talk to our team to design a fraud prevention system tailored to your platform and get a detailed project estimate.
FAQs
Q1. What Is a Machine-Learning Fraud System?
A1. A machine-learning fraud system is an automated platform that evaluates transactions in real time using behavioral signals, device intelligence, and adaptive models. Unlike static rule engines, it learns continuously from new data. Therefore, it improves detection accuracy over time while simultaneously reducing the false positives that drain operational resources and frustrate legitimate customers.
Q2. How Is ML Fraud Detection Better Than Rules?
A2. Rule-based systems flag only known fraud patterns and require manual updates every time tactics shift. ML models, however, identify subtle anomalies across hundreds of variables simultaneously. As a result, they detect novel attack vectors faster, adapt without human intervention, and consistently outperform rule engines on both detection rate and false positive reduction at scale.
Q3. How Much Data Is Needed to Train Models?
A3. There is no universal threshold. However, most production-grade fraud models require a minimum of several hundred thousand labeled transactions to perform reliably. Furthermore, data quality matters as much as volume. Clean, well-labeled historical records with confirmed fraud outcomes produce significantly stronger models than large datasets with inconsistent or delayed labeling.
Q4. How Long Does It Take to Build a System?
A4. A foundational ML fraud system typically takes three to six months to build and deploy, depending on data readiness, infrastructure complexity, and integration requirements. Consequently, enterprises with clean data pipelines and modern architecture move faster. A phased approach, starting with high-impact fraud types, delivers measurable results well before the full system is complete.
Q5. What Does It Cost to Build One?
A5. Build costs vary significantly based on scope and complexity. A focused MVP covering core fraud types typically ranges from $40,000 to $80,000. A full enterprise-grade system with multi-model orchestration, real-time pipelines, and compliance architecture can exceed $150,000. In addition, ongoing costs for model monitoring, retraining, and infrastructure scaling should be factored into the total investment.