Key Takeaways:
-
AI claims prediction combines EDI 837 data, remittance outcomes, payer rules, and machine learning models.
-
XGBoost, random forests, and deep learning models power denial risk scoring before claim submission.
-
HIPAA controls, explainability, MLOps, drift monitoring, and human review are non-negotiable production requirements.
-
Production builds take five to nine months and cost $60,000–$180,000, depending on scope.
-
How Intellivon builds claims prediction as a revenue infrastructure that flags risk, explains root causes, and recommends fixes.
Revenue cycle teams have always worked with incomplete information at submission time. Once a claim goes out, somewhere between two days and three weeks later, the payer responds. What an AI claims prediction platform adds is a risk score attached to every claim before that window opens. That score is drawn from past denial patterns, payer behavior, and claim-level signals that human reviewers would never have time to check manually.
Building one requires a specific set of components. First, clean training data pulled from remittance files and denial codes. Then, payer-calibrated models that reflect how each carrier actually adjudicates. After that, a routing layer that connects to the existing claims workflow, and security controls that protect patient data through every step of the process.
This blog walks through all of it, including model architecture, data requirements, EHR integration, compliance controls, and development cost by phase. At Intellivon, we build these systems for health systems and RCM platforms that need prediction accuracy and compliance working together in production.

What Is an AI Claims Prediction Platform?
An AI claims prediction platform is software that looks at every claim before it goes to the payer and tells the billing team what is likely to happen to it. Specifically, it learns from past claims, payment history, and payer behavior to generate a risk score. As a result, claims that score high risk get flagged for review, while claims that look clean move through automatically.
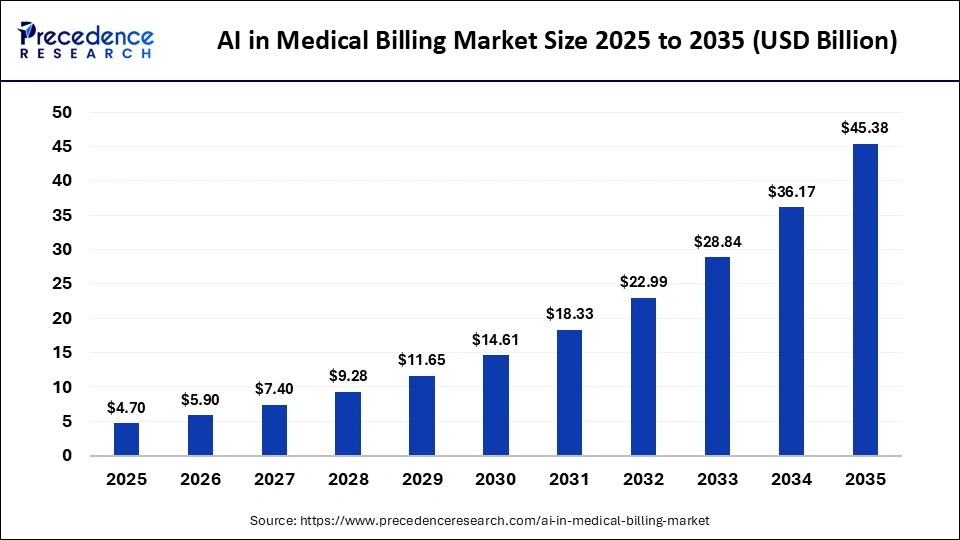
The global AI in medical billing market was valued at USD 4.70 billion in 2025 and is projected to grow from USD 5.90 billion in 2026 to approximately USD 45.38 billion by 2035, expanding at a CAGR of 25.44%.
A major technical gap in older software is analyzing data only at the claim-header level, which misses specific line-item rejections. An advanced AI-powered claims forecasting platform predicts outcomes at the claim-line level, identifying the precise procedure or modifier combination driving a denial probability scoring spike. To understand how this works within your existing workflow, it helps to contrast this technology with traditional tools.
The following table breaks down the core functional differences:
How This Workflow Goes
| Capability | Core Technology | Primary Focus | Technical Goal |
| Claim Scrubbing | Static, hard-coded rulesets | Simple syntax, formatting, and standard ICD-10/CPT edits | Catching administrative errors before clearinghouse transmission |
| Denial Prediction | Machine learning models | Historical patterns, payer behavior modeling, and clinical context | Calculating the exact probability of a claim being rejected |
| Claims Adjudication Prediction | Adjudication simulation | Payer contract logic and past payment timelines | Forecasting if a claim will be approved, paid, or delayed |
| Underpayment Prediction | Contractual compliance algorithms | Expected allowed amounts versus historical payment trends | Identifying variance between contractual rates and actual payer remittance |
| Appeal Prioritization | Value-based scoring models | Probability of overturn, combined with the total claim dollar value | Ranking denied claims to maximize recovery ROI for collection teams |
The value comes from giving billing, coding, and RCM teams enough context to fix the claim before the payer response. That means the next section should define the use cases the platform must support first.
[For a deeper breakdown of claims automation, see our guide on AI Healthcare Claims Processing Software Development.]
Why Your Current RCM Stack Cannot Predict Claim Outcomes
Traditional revenue cycle management software lacks the structural framework to foresee how an insurance company will react to a submission. Current systems use hard-coded rules to validate formatting, which catches simple clerical mistakes but fails to simulate actual adjudication.
An AI layer introduces historical context, allowing your stack to transition from basic formatting checks to deep behavioral forecasting.
1. Rules Engines Check Layouts but Ignore Payer Habits
A standard rules engine evaluates if data fields are complete based on rigid, static logic. However, it cannot execute payer behavior modeling because insurance companies constantly change their internal payment criteria without public notice.
The system only confirms that the document is formatted correctly, not that the payer will approve the medical service.
- Validates data against fixed formatting templates
- Misses unwritten changes in insurance adjudication rules
- Fails to calculate the actual likelihood of approval
2. Clearinghouse Scrubbers Lack Historical Memory
Clearinghouse tools look at a claim as an isolated event rather than part of an ongoing trend. Because these tools have no memory of past payment patterns, they cannot perform true denial pattern recognition or track historical outcomes.
This lack of memory means the system approves claims that match formatting rules but possess high rejection risks based on recent insurance behaviors.
- Evaluates submissions individually without referencing past outcomes
- Ignores local trends in claim rejections
- Overlooks shifting seasonal patterns in payer behavior
3. Software Cannot Scan Unstructured Medical Notes
Most billing systems are designed to process structured data fields like standard diagnostic codes. They cannot structurally analyze unstructured clinical text, which contains the critical clinical context required for accurate coding accuracy prediction.
Without this medical narrative, the software cannot verify if the documentation supports the specific procedure.
- Skips rich clinical notes inside the health record
- Cannot independently verify medical necessity requirements
- Fails to detect mismatch risks between records and codes
4. Static Systems Cannot Grade and Route Risk
Traditional billing tools use a binary pass-or-fail approach during the editing phase. They cannot calculate a dynamic denial probability score or rank claims by financial risk for the billing department.
As a result, high-value claims with subtle errors receive the same priority as low-value, straightforward submissions.
- Lacks the math to assign a dynamic risk score
- Cannot sort work queues by potential revenue loss
- Forces staff to review low-risk and high-risk bills identically
5. Formats Block Clearinghouse Rejection Forecasts
Standard RCM software operates too late in the workflow, checking files right before transmission. This structural placement makes accurate clearinghouse rejection prediction nearly impossible because the data has already been locked into rigid formats.
The system cannot simulate how different insurance systems will interpret complex, multi-line diagnostic entries.
- Operates at the tail end of the workflow
- Cannot simulate claims adjudication prediction scenarios
- Blocks early adjustments during the clinical documentation stage
Data models show that replacing rigid rules with automated machine learning allows networks to simulate complex insurance variables before submission
The prediction layer does not replace your clearinghouse scrubber. Instead, it adds an intelligent forecasting step that models insurance behavior using historical data. This extra layer gives your team the exact context needed to fix complex clinical and behavioral risks before submission.
Where an AI Claims Prediction Platform Creates Revenue Impact
An AI claims prediction platform creates the most value in workflows where small data, coding, authorization, or documentation problems repeatedly delay reimbursement. The strongest use cases include denial prediction, eligibility prediction, prior authorization risk, coding mismatch detection, timely filing risk scoring, duplicate claim detection, coordination of benefits prediction, and underpayment prediction.
Intercepting these issues early protects your revenue integrity and maximizes your net collection rate.
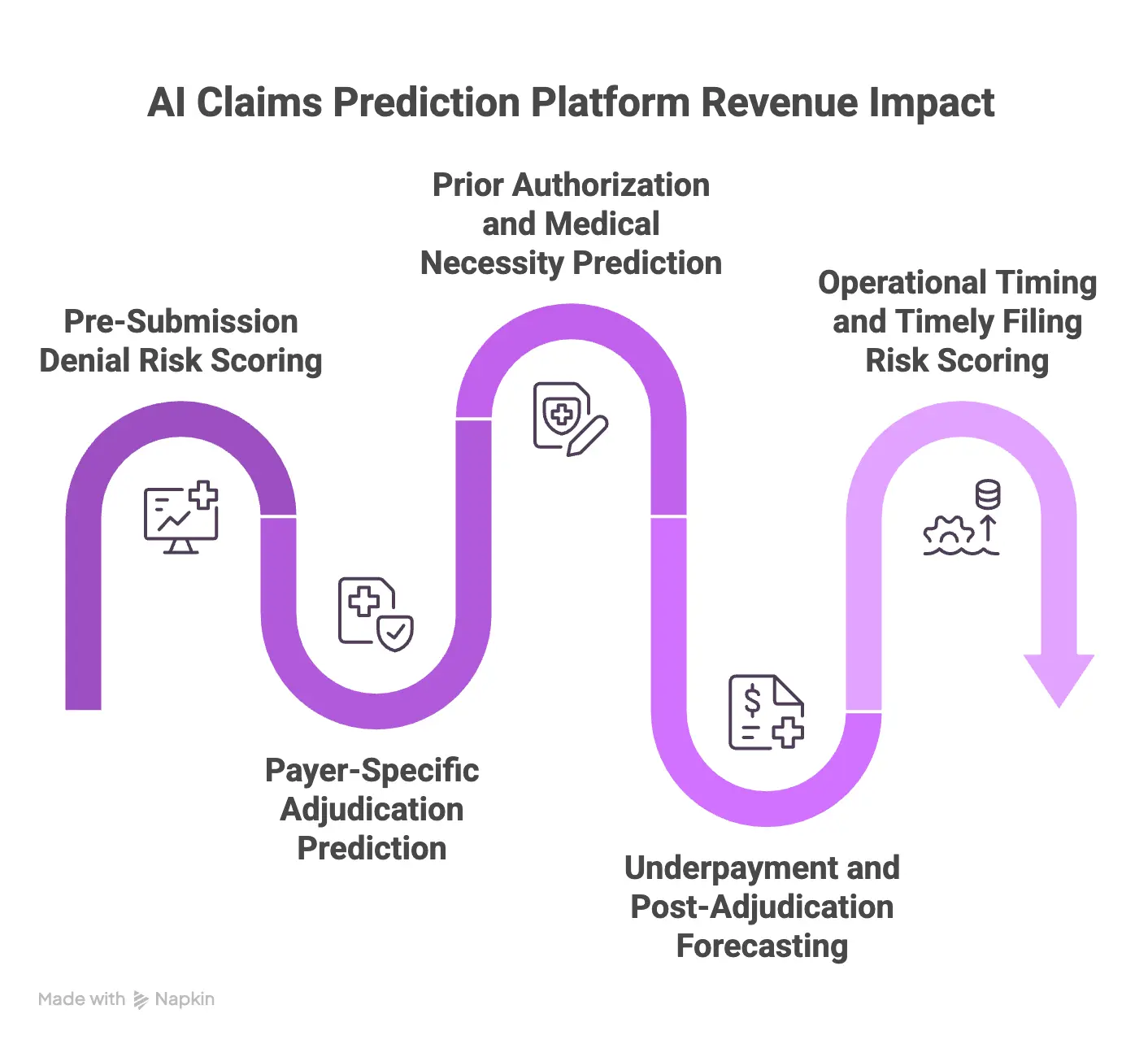
1. Pre-Submission Denial Risk Scoring
This feature acts as a digital safety net, evaluating every bill before it leaves your network. The software checks for high-risk combinations of medical codes, provider details, and location data to catch mistakes early.
Instead of stopping every document, it uses real-time denial risk scoring to flag only the specific entries that have a high probability of rejection.
- Performs automated CPT code validation and NCCI edit prediction instantly
- Scans for hidden ICD-10-CM mismatch detection issues across all line items
- Routes complex errors to billing teams automatically to ensure coding accuracy prediction
2. Payer-Specific Adjudication Prediction
Different insurance companies handle identical claims in entirely different ways. This module uses multi-payer prediction models to track individual insurance behaviors, from commercial giants to local Medicaid plans.
By studying past responses, the system builds custom payer-specific prediction models that adjust automatically when an insurance company changes its internal payment rules.
- Analyzes historical data to perfect your local payer mix analysis
- Uses deep payer contract logic modeling to forecast final approval timelines
- Identifies unique regional nuances through specialty-specific denial prediction
3. Prior Authorization and Medical Necessity Prediction
Missing authorization forms and vague medical notes are leading causes of lost revenue. This tool reads clinical documentation ahead of time to confirm that the planned treatment matches insurance coverage rules.
By cross-referencing clinical notes with official policy guidelines, it calculates a clear prior authorization prediction score before submission.
- Conducts automated LCD / NCD compliance checking for Medicare accounts
- Verifies medical necessity prediction metrics using your historical data
- Flags missing authorization numbers days before the patient receives care
4. Underpayment and Post-Adjudication Forecasting
Insurance companies occasionally pay less than their agreed contract rates. This module compares your actual insurance payouts against your original contract agreements to find hidden shortfalls.
By running an automated EOB pattern analysis, the system isolates chronic underpayment trends and highlights the specific accounts that are worth appealing.
- Delivers accurate underpayment prediction metrics to your collections dashboard
- Spots systematic coding downgrades by analyzing payment explanations
- Ranks underpaid accounts by their financial recovery potential
5. Operational Timing and Timely Filing Risk Scoring
Missing a strict insurance submission deadline can result in an immediate, unappealable loss. This module tracks the exact time elapsed since the original date of service and ranks accounts by their processing urgency.
It monitors slow-moving documentation workflows to ensure high-value accounts do not expire in your backlog.
- Calculates a dynamic, timely filing risk scoring tier for all open bills
- Highlights delayed clinical charts that require immediate provider signatures
- Alerts managers when operational bottlenecks threaten billing deadlines
The best first build is the workflow where high-volume claims, clear historical labels, and measurable revenue impact overlap. Once that scope is clear, the next decision is the architecture.
ML Model Architecture Behind an AI Claims Prediction Platform
Building a predictive system requires a layered machine learning architecture that transforms historical billing records into real-time operational risk scores. Instead of relying on rigid rules, this system maps the hidden connections between patient histories, doctor documentation styles, and changing insurance behaviors.
A production-ready architecture uses specialized tabular models alongside language processing engines to deliver clear risk scores before transmission.
1. Feature Engineering (What Data the Model Actually Reads)
The predictive accuracy of your system depends entirely on how your data pipelines organize billing records into model-readable signals. Feature engineering for claims turns raw, messy healthcare transactions into structured math variables that a machine learning model can easily understand.
If this step is skipped or performed on generic data fields, the system suffers from high false-alarm rates and misses complex billing errors.
- Structured Claim Records: The pipeline groups core fields, including CPT codes, ICD-10-CM codes, provider NPI numbers, payer IDs, place of service variables, modifiers, and prior authorization status flags.
- Historical Remittance Mapping: The system analyzes previous Claim Adjustment Reason Codes and Remittance Advice Remark Codes from historical remittance data to build a clear dataset of past insurance rejections (Source: [X12, 2026]).
- Patient-Level Risks: The model incorporates basic patient demographics, insurance plan tiers, and coordination of benefits status variables to flag coverage conflicts early.
- Payer Behavior Tracks: The data pipeline calculates specific insurance processing speeds and records recent changes in localized policy rules.
Our data engineering teams at Intellivon build automated feature pipelines that extract clean historical trends straight from your billing records without slowing down active operations.
We focus on transforming deep CARC/RARC analysis and EOB pattern analysis files into live training assets to keep your data highly accurate. This organized data foundation sets up the next stage of model selection.
2. Model Selection (Gradient Boosted Trees vs. Deep Learning vs. Hybrid)
Tabular healthcare spreadsheets and unstructured clinical text require completely different mathematical models to achieve high accuracy. For standard rows and columns of medical billing data, gradient boosted trees healthcare frameworks consistently outperform deep neural networks.
However, standard tree models cannot read raw human sentences, which is why a hybrid setup is needed for comprehensive revenue cycle protection.
| Model Architecture Type | Core Technical Frameworks | Strengths | Ideal Revenue Cycle Use Case |
| Gradient Boosted Trees | XGBoost, LightGBM, Random Forest | High speed with low computing overhead. Analyzes structured data grids effectively. Works reliably with smaller datasets. | Pre-submission risk scoring, CPT/ICD-10 code validations, and historical CARC/RARC analysis. |
| Deep Learning | Transformer models, neural networks, BiLSTM | Understands raw human text. Finds hidden patterns in unstructured data. Scales well with millions of records. | Reading unstructured clinical notes, medical necessity prediction, and multi-modal documentation reviews. |
| Hybrid System | Combined tree + NLP layer, multi-input neural architectures | Analyzes text and codes simultaneously. Minimizes system false-alarm rates. Supports SHAP-based interpretability. | Advanced AI claims prediction platforms, line-item denial probability scoring, and real-time denial risk scoring. |
This gives your billing staff transparent, clear explanations for every risk alert, which builds deep user trust and ensures high coding accuracy. Once the basic model structure is set, the system routes claims based on individual insurance rules.
3. Payer-Specific Model Variants
Insurance networks use completely different criteria to evaluate identical clinical claims, meaning a single general model will suffer from heavy operational errors.
To prevent systematic inaccuracy, your architecture must run separate payer-specific prediction models or fine-tuned base systems for each major insurance company.
Managing these separate models requires an intelligent routing layer that tracks individual company profiles in real time.
- Behavior Divergence Protection: Separate models prevent accuracy loss caused by differences in how insurance companies interpret identical medical necessity rules.
- Data Volume baselines: Each custom payer model requires a baseline threshold of roughly 10,000 historical claims to train effectively and predict outcomes reliably.
- Smart Routing Infrastructure: Multi-payer prediction models use an intelligent routing architecture to send each bill to its matching insurance behavioral profile instantly.
- Specialized Insight Tracking: Isolating your data channels allows the system to execute sharp, specialty-specific denial prediction checks for complex clinical workflows.
This architecture shields your system from data inaccuracy and ensures your risk metrics stay sharp even when a specific company changes its payment rules overnight. For a deeper breakdown of system architecture options, see our guide on How to Build an AI Claims Denial Management Platform
AI Claims Prediction Platform Architecture: The 7-Layer Build
An AI claims prediction platform architecture must separate data ingestion, normalization, feature engineering, model inference, explainability, workflow routing, and monitoring. This separation keeps the prediction layer traceable, secure, and easier to update when payer rules, coding requirements, claim formats, or denial patterns change across the revenue cycle. Decoupling these layers prevents system-wide downtime during updates.
The following table details the technical mechanics and specific technologies required to construct each of the seven structural layers:
The 7-Layer Architecture
| Architectural Layer | Core Operational Functions | Primary Technologies Used |
| Layer 1: Claims Data Ingestion | Extracts raw billing data, patient encounter details, and clearinghouse responses before locking them into the processing stream. | • FHIR R4 API
• EHR data integration pipelines • EDI 837 validation engines |
| Layer 2: Remittance & Denial Outcome | Gathers historical denial data training files, categorizes incoming EOB patterns, and matches claims with final payment statuses. | • CARC / RARC analysis tools
• EOB pattern analysis scripts • Claims training dataset warehouses |
| Layer 3: Feature Engineering | Transforms raw codes into payer-specific prediction models, scoring historical trends, provider habits, and timing risks. | • Feature engineering for claims pipelines
• Claims denial pattern recognition engines |
| Layer 4: AI Model Layer | Executes parallel mathematical calculations to predict rejection risks across individual claim line items simultaneously. | • XGBoost claims prediction
• Gradient boosted trees healthcare models • Random forest denial modeling |
| Layer 5: Explainability Layer | Translates complex model math into clear text, showing users the exact data points behind each claim’s confidence scoring drop. | • SHAP values in claims AI
• Model interpretability healthcare modules • Explainability layer microservices |
| Layer 6: Workflow & Human Review | Intercepts high-risk bills automatically and places them into custom work queues for human-in-the-loop review based on dollar value. | • Role-based access control managers
• Automated work-queue routing engines • Smart task-prioritization interfaces |
| Layer 7: MLOps & Monitoring | Tracks real-time model drift monitoring metrics to spot sudden changes in insurance behaviors and trigger systematic updates. | • Payer rule decay detection alerts
• Retraining trigger architecture • Prediction model versioning registries |
Architecture matters because claims prediction is not a one-time model. Payer behavior changes, coding rules change, and denial categories drift. This makes training data design the next critical build decision.
What To Do When Your Denial Dataset Is Too Small to Train On
Most software companies assume a hospital has millions of perfectly labeled billing records ready for machine learning. In reality, a typical mid-market hospital with 200 to 600 beds usually only has 30,000 to 80,000 labeled claims in its historical files.
Therefore, this limited volume is often too small to train large, stable prediction models from scratch. Fortunately, specific data strategies allow organizations to build an accurate platform even with a highly limited data history.
1. The Real Data Floor for Claims Modeling
Before writing code, teams must understand the absolute minimum amount of information required for machine learning to work effectively.
For example, a stable system generally needs at least 10,000 labeled claims per major insurance company to spot subtle rejection patterns.
Consequently, if a medical network focuses on highly specialized treatments, it will need a higher concentration of records to account for complex billing rules.
- A baseline of 10,000 historical documents is required per core insurance plan.
- More data is necessary if a facility handles rare, high-cost specialty surgeries.
- The exact floor varies based on how clean past electronic billing records are.
2. Using Public Medicare Files as a Base
Instead of starting a machine learning journey with a completely blank slate, engineers can use large, public government databases. Specifically, the Medicare Limited Data Sets help teach a model the foundational rules of medical billing.
After the software understands basic national trends, developers can introduce a small local dataset to teach it specific regional patterns.
- Large public government files are used to build a strong foundational model.
- The software learns standard national billing and coding relationships early.
- This approach saves months of development time by avoiding training from scratch.
3. Creating Synthetic Data for Rare Mistakes
When certain types of insurance denials happen rarely, a machine learning model will struggle to recognize them. To solve this, developers use a mathematical technique called SMOTE to create realistic, synthetic examples of these rare rejections based on real historical patterns.
Thus, this balancing process ensures the software learns how to catch uncommon errors instead of simply ignoring them.
- Advanced math creates realistic dummy examples of rare billing errors.
- Training files are balanced so the model does not ignore uncommon mistakes.
- This technique improves the overall accuracy of the platform for high-value specialty bills.
4. Learning from Successful Paid Claims
Hospitals often forget that clean, successfully paid claims contain valuable clues for machine learning models.
For this reason, semi-supervised learning techniques allow engineers to use millions of unlabeled, successful payments to show the model what a perfect claim looks like.
Ultimately, this process helps the software identify subtle deviations in high-risk files by contrasting them against a massive library of successful bills.
- Successful historical payments are analyzed to establish a clear baseline of a perfect bill.
- This process reduces the total amount of bad denial data needed to train the system.
- The boundary lines the model uses to judge incoming high-risk bills become much sharper.
5. Narrowing the Launch Scope for Faster ROI
Trying to build a system that handles every single insurance company on day one is a common path to project delays.
Alternatively, a practical approach is to start with a highly narrow scope, focusing exclusively on a single dominant insurance provider or one common type of medical service.
Then, the organization can safely expand the system to cover more areas as the billing department accumulates more live data.
- The system is launched initially for just one dominant insurance provider.
- The platform is perfected on high-volume, predictable bills first.
- Coverage is expanded systematically to smaller insurance plans over time.
A first-generation model should focus on high-volume consistency rather than absolute perfection across an entire network. As the software processes fresh claims, its accuracy will follow a steady upward trajectory, expanding revenue protection automatically.
Consequently, once this data foundation is secure, the next step is connecting the platform directly to live health records.
What Data Do You Need to Build Claims Prediction Software?
Claims prediction software development depends on clean historical claims, remittance outcomes, denial labels, payer information, patient coverage data, coding details, provider data, authorization history, and clinical documentation signals.
The minimum viable dataset should connect submitted claim lines to final payer outcomes, denial codes, payment amounts, and correction history. This specific mapping creates the math foundation for machine learning algorithms.
The following list breaks down the exact data assets required to train and scale the platform:
1. Minimum Data Required for an MVP
Building a working pilot requires a tight focus on foundational billing documents from the past 12 to 24 months. For this reason, teams must prioritize gathering raw EDI 837 files, which contain the exact clinical claims submitted to insurance networks.
Additionally, the system must ingest matching EDI 835 payment documents to link each claim line with its final financial outcome.
- Core Claim Files: Standard electronic submissions containing raw billing codes and provider names.
- Payment Details: Remittance documents highlighting final paid amounts and contractual write-off lines.
- Rejection Markers: Official CARC/RARC codes used to identify the exact cause of a billing dispute
- Processing Dates: Exact tracking files showing initial submission timelines, payer response speeds, and resubmission histories.
2. Data That Improves Model Accuracy
Once the basic infrastructure is stable, introducing supplementary data channels helps drop false-alarm rates significantly.
For example, adding live prior authorization records allows the platform to check if a medical service has a valid tracking number before submission. Similarly, scanning clinical notes helps verify if the patient’s chart matches the selected billing codes.
- Coverage Status Verification: Live eligibility check histories that prove the patient has active benefits.
- Provider Validation Logs: Credentialing status records that flag if a doctor is allowed to bill a specific plan.
- Payer Contract Logic: Local fee schedules and rule updates are used to model contract compliance.
- Clinical Summaries: Unstructured electronic medical charts that provide deep therapeutic context.
3. Data Quality Checks Before Training
Raw health records are famously messy, meaning developers must run rigorous data quality checks before exposing them to learning models.
First, data pipelines must remove duplicate entries to prevent the system from learning the same mistake twice. Second, engineers must standardize varied insurance names into clear, uniform payer IDs.
- Name Normalization: Grouping multiple spelling variations of a single insurance branch under one identifier.
- Error Segregation: Separating simple upfront clearinghouse rejections from complex post-adjudication denials.
- Code Validation: Scanning historical records to fix dead codes, missing modifiers, or formatting errors.
- Status Reconciliation: Tracking a claim’s historical progress to ensure every line item has a clear final outcome label.
4. Label Design for Denial Prediction Model Training
The final step in preparing data is designing the target labels that the software will try to predict. Instead of using a simple pass-or-fail marker, a production system uses descriptive, multi-layer labels to categorize risks.
Consequently, this design allows the software to predict the exact type of mistake, its financial severity, and the best path to fix it.
- Outcome Category Tiers: Labeling lines as fully paid, rejected, underpaid, or stuck in a pending queue
- Root Cause Classification: Flagging errors specifically as authorization mismatches, coding blunders, or timely filing risks.
- Financial Impact Scores: Categorizing billing risks into low, medium, or high cash-loss categories.
- Action Routing Targets: Marking files with specific instructions like “update modifier” or “route to human review.”
The dataset decides what the model can learn. A weak label strategy produces vague scores. A strong label strategy lets the platform predict the reason, likely outcome, financial impact, and best next action. Consequently, once these labels are designed, developers can map out the actual integration points with the hospital system.
Which AI Models Work Best for Claims Prediction in Healthcare?
The best AI tools for machine learning claims prediction in healthcare setups are smart sorting models. Specifically, these include gradient boosted trees, XGBoost, and random forests.
While deep learning helps large systems look at a long history, simple text models help read doctor notes. Choosing the right tool keeps costs low and stops billing mistakes before they happen.
1. Use Gradient Boosted Trees for the First Production Model
Gradient boosted trees are the finest option for looking at standard billing sheets with rows and columns. For example, tools like XGBoost process text names and dollar amounts together without crashing. Furthermore, these tools work fast, making them perfect for real-time denial risk scoring.
- They read standard billing files in seconds using very little computer power.
- They show clear math steps so teams can see why a bill is risky.
- They work well even when insurance rejections are rare.
2. Use Random Forests for Stable Benchmarking
A random forest model is a great starting tool to see if complex math is worth your money. Because this tool combines many small choices to make a final guess, it stays highly stable. Consequently, it gives teams an easy way to see which errors cause the most rejections.
- Teams can set up a working model in a few days.
- The software highlights the exact codes causing the biggest payment drops.
- The simple design stops small data bugs from ruining the main score.
3. Use Deep Learning Only for Big History
Deep learning neural networks are usually too heavy for normal billing grids, but they excel at tracking a long history of patient visits. For instance, when a massive hospital system handles millions of rows over many years, deep learning maps how past visits affect current claims. However, this path requires a lot of daily upkeep and expensive computers.
- It connects years of past medical visits to spot hidden payment trends.
- The math gets smarter as you feed it more data
- It requires highly specialized engineering teams to monitor daily.
4. Use LLMs for Document Extraction, Not Risk Scoring
Smart text engines should never guess financial risk scores because they can make up fake facts. Instead, these text models are perfect for reading long doctor notes to find missing insurance approval numbers. Therefore, they should work only as a helpful assistant to write appeal letters or summarize new rules.
- The software scans long patient charts to find missing paperwork fast.
- It turns confusing insurance denial reason codes into plain, easy words.
- Standard machine learning models must always double-check the text outputs.
5. Use SHAP and Calibration Before Production
Before launching a model in a live billing office, engineers must prove the software scores match real life. For example, using SHAP values in claims AI provides great model interpretability and healthcare benefits by showing staff why a bill was flagged. Additionally, this tuning ensures high-dollar claims go to senior experts automatically.
- The system shows clear text explaining exactly why a bill is risky.
- A 70% risk score means the bill will fail 7 out of 10 times in real life.
- High-value bills automatically trigger a human-in-the-loop review
The safest model is not always the most complex one. For claims prediction, the winning tool is the one that billing teams trust, engineers can monitor, and compliance teams can audit.
For a deeper breakdown of system choices, see our guide on AI Denial Prediction Software Development for Hospitals
That trust depends entirely on what the system does after making a guess. Consequently, once the model is ready, developers must connect these scores directly into the live hospital workflow.
HIPAA Compliance Architecture for a Claims Prediction Platform
A custom claims prediction system built handles data differently than a simple formatting tool. Specifically, standard billing software transfers claims in fixed files without extra evaluation.
Alternatively, a prediction platform feeds active patient information directly into live machine learning models to calculate risk.
This live data movement requires a specialized security setup to shield Protected Health Information (PHI) from leaks during the prediction process.
1. PHI Tokenization at Inference
The data pipeline strips out direct patient details, like names, social security numbers, and full addresses, before sending a bill to the model. Then, a secure internal vault swaps these data fields with randomized strings. This technique keeps identities completely private while the software calculates risk.
- The system hides the patient’s name and location.
- Random numbers replace the real Social Security data.
- The machine learning model sees only raw codes and numbers.
2. HIPAA Security Rule Endpoint Safeguards
Every live machine learning model endpoint must live inside an isolated, encrypted network perimeter. Consequently, this design stops unauthorized software from sending rogue requests to the predictive system. It ensures that only trusted hospital applications can ask the model for a risk score.
- All data connections use strong modern encryption.
- Firewalls block outside internet traffic from touching the model.
- The system checks security keys for every incoming request.
3. BAA Compliance for Cloud Infrastructure
If a hospital system uses a third-party cloud to host its machine learning code, that provider must sign a formal contract.
Specifically, a Business Associate Agreement forces the hosting vendor to maintain strict federal privacy safeguards. Without this paperwork, the platform cannot legally process health records.
- The cloud vendor signs a legal pledge to protect data.
- Independent teams audit the server rooms regularly.
- The setup meets all federal healthcare privacy standards.
4. Role-Based Access Control
Dashboard access must follow strict permission rules. For example, billing clerks see only basic code suggestions, while system managers use separate security keys to view full patient logs or authorize model changes.
This setup prevents low-level accounts from seeing sensitive records they do not need.
- Workers see only the information needed to do their specific job.
- Managers hold separate passwords to approve major changes.
- System keys change automatically every few months to stay safe.
5. Audit Trail Immutability
The platform records every single calculated risk score, missing document alert, and manual staff override in a tamper-proof log sheet.
Every entry receives an automatic timestamp and a unique user ID. Crucially, these logs can never be edited or erased by anyone in the company.
- The software saves a history of every single risk check.
- The logs show exactly who changed a record and when.
- The tracking sheet is locked, so no one can erase mistakes.
6. Zero-Trust Architecture Design
The pipeline operates under a strict policy that trusts no one by default. As a result, every internal service must verify its electronic identity using encrypted tokens for every single claim call. This prevents a hacker from moving through the system if one part gets compromised.
- The software verifies every connection request inside the network.
- Data blocks remain sealed until the system proves identity.
- The security tools monitor internal traffic for strange movements.
Choosing between a private local server and a secure cloud endpoint alters your core network design. For example, local server hosting keeps raw medical files entirely inside your physical building, removing external internet risks completely.
On the flip side, secure cloud setups offer fast automatic scaling but require advanced encryption keys to shield data while it moves across networks.
How to Build an AI Claims Prediction Platform Step by Step
To build an AI claims prediction platform, start with a claims workflow scope, then design the data pipeline, normalize historical claims and remittance data, train payer-specific models, add explainability, integrate with EHR and clearinghouse systems, define human review rules, test against revenue cycle KPIs, and deploy with MLOps monitoring.
This organized path ensures the software integrates smoothly into your daily business operations without disrupting existing workflows.
The following steps outline the complete build process from initial planning to live deployment:
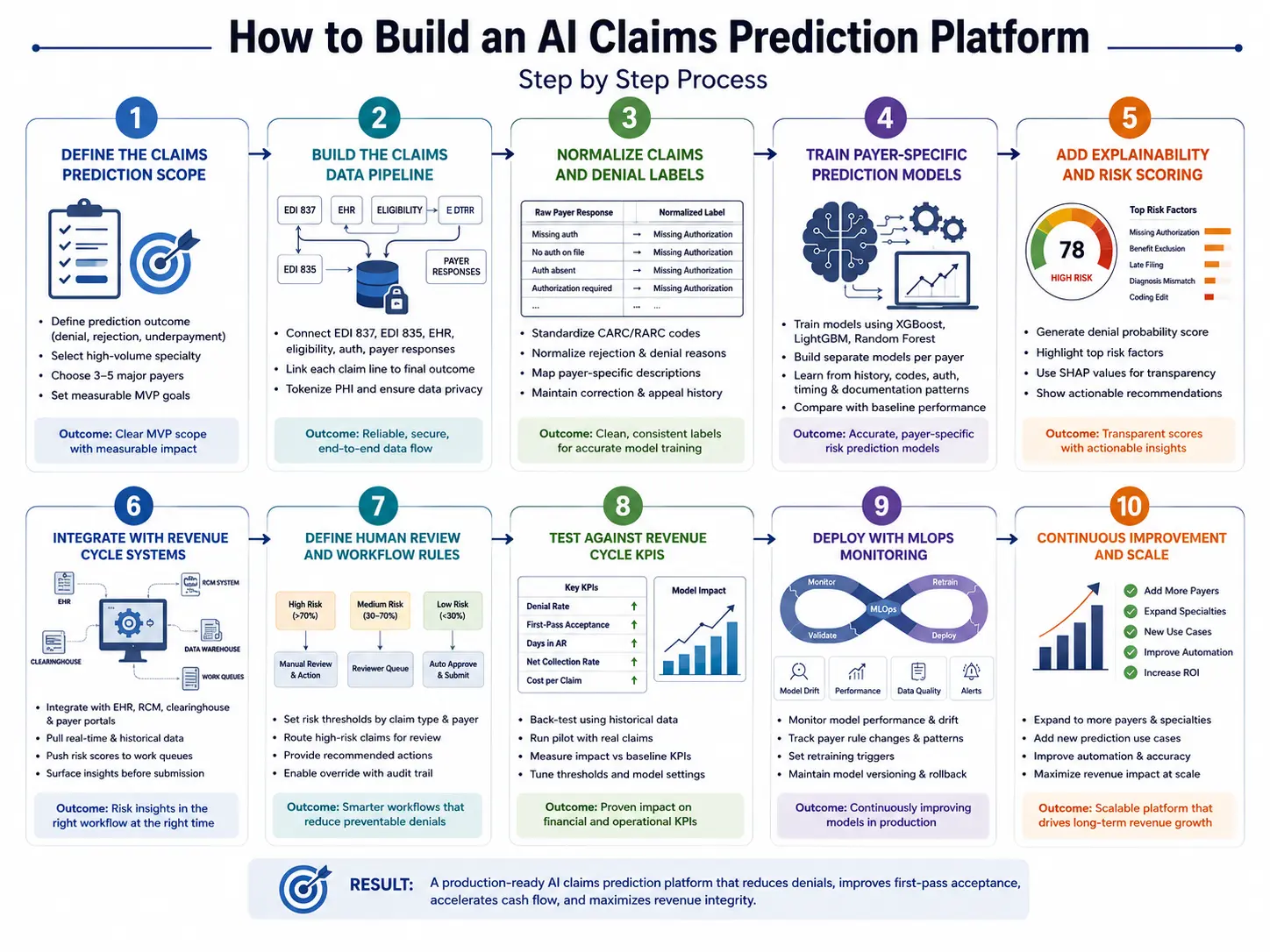
Step 1 — Define the Claims Prediction Scope
Start by defining which claim outcomes the platform should predict first, because denial prediction, rejection prediction, underpayment prediction, and adjudication delay forecasting need different data labels.
A focused MVP should usually begin with one high-volume specialty, three to five major payers, and one measurable outcome such as pre-submission denial reduction.
1. Technical Implementation Details
The engineering team maps out the entire life cycle of a bill to see exactly where payment delays happen. Next, the developers group historical rejections into clear buckets, like missing approvals or wrong codes. Finally, the team selects the top three insurance plans to test first, ensuring the project has a clear financial baseline to measure success.
- The team maps out every step a bill takes from creation to final payment.
- Developers sort past rejections into clear, non-technical error buckets.
- Managers pick three major insurance plans to focus on for the initial launch.
The Intellivon Engineering Approach
Intellivon maps denial volume, payer mix, claim value, and operational review capacity before choosing the first build scope. This prevents the MVP from becoming a broad analytics dashboard with no measurable reimbursement impact. We ensure the team focuses only on areas where software can prevent real cash loss immediately.
Once the scope is narrow enough to measure, the next step is building the data foundation.
Step 2 — Build the Claims Data Pipeline
The claims data pipeline should connect EDI 837 submissions, EDI 835 remittance files, EHR data, eligibility records, authorization data, payer responses, and user correction history.
The goal is to create a reliable link between each submitted claim line, its final outcome, and the action that changed or failed to change that outcome.
Technical Implementation Details
Engineers build software lines to pull records automatically from your electronic health tools using secure FHIR R4 API links. After that, a central data lake house organizes these files, matching every single billed line item to its final insurance payout sheet. Crucially, the system tokenizes all personal patient details to ensure strict data privacy before processing.
- Secure data links pull records from health systems using standard FHIR R4 API tools.
- A central data store matches every submitted line item with its final payment sheet.
- The system strips out names and social security numbers to protect patient privacy.
The Intellivon Engineering Approach
Intellivon designs claims data pipelines around traceability. Every prediction must connect back to the claim version, payer response, training label, model version, and reviewer action used to produce it. This deep tracking setup allows your technical teams to audit any alert or score instantly.
A connected pipeline still needs clean labels before it can train a useful model.
Step 3 — Normalize Claims and Denial Labels
Denial prediction models need normalized labels because raw payer responses are inconsistent across payers, claim types, and remittance formats.
The platform should standardize CARC/RARC codes, clearinghouse rejections, payer-specific denial descriptions, appeal outcomes, and correction history into clean categories that the model can learn from safely.
Technical Implementation Details
Developers build translation tables that turn different insurance description codes into unified, clean categories. For example, if three insurance companies use three different words for a missing approval form, the software groups them under one master label.
Furthermore, the pipeline automatically separates quick format rejections from deep medical necessity denials.
- Translation rules group different insurance error codes into one single master label.
- The system automatically separates quick format errors from complex clinical denials.
- Clean data histories show exactly how past teams fixed specific billing mistakes.
The Intellivon Engineering Approach
Intellivon builds the label taxonomy with RCM users, not only data engineers. This keeps the categories useful for operational teams who must act on predictions after the model scores each claim. By involving billing clerks early, we ensure the software’s final alerts make perfect sense to your staff.
After label quality improves, the model layer can be trained with more reliable outcomes.
Step 4 — Train Payer-Specific Prediction Models
Train payer-specific prediction models because the same claim can behave differently across commercial plans, Medicare Advantage, Medicaid, and specialty payer contracts.
The model should learn payer behavior, historical denial patterns, procedure-code risk, documentation gaps, prior authorization signals, and claim timing patterns instead of applying one generic risk formula to every claim.
Technical Implementation Details
Engineers deploy fast gradient boosted trees healthcare frameworks, such as XGBoost, to process the clean billing rows. The software trains a distinct mathematical model for each major insurance company to account for different processing habits. Finally, developers test these custom setups against simple statistical baselines to guarantee the new tools provide superior accuracy.
- Teams use fast XGBoost tools to read through structured rows of billing data.
- The software trains a separate mathematical model for each major insurance carrier.
- Developers test the new tools against basic rules to ensure superior accuracy.
The Intellivon Engineering Approach
Intellivon typically starts with explainable tabular ML models before considering deep learning. This gives revenue teams clearer risk drivers and gives technical teams a stronger baseline for production monitoring. We avoid over-complicated neural networks when fast, transparent tree models can do the job better.
Once the model predicts risk, the platform must explain why the prediction is trustworthy.
Step 5 — Add Explainability and Confidence Scoring
Explainability and confidence scoring turn a prediction into a usable RCM decision. The platform should show the top denial drivers, supporting evidence, model confidence, financial exposure, and recommended action so billers, coders, and authorization teams can decide whether to fix, submit, hold, or escalate the claim.
Technical Implementation Details
The platform uses SHAP values in claims AI to highlight the exact data points that made a bill look risky. For instance, if a modifier code does not match a doctor’s specialty, the system explicitly calls out that conflict. The interface then creates a live confidence score that automatically sorts high-risk bills into priority work lists.
- The software uses SHAP tools to highlight the exact reasons behind an alert.
- Live confidence scores show staff how likely a claim is to get rejected.
- High-risk, expensive bills move to the top of work lists automatically.
The Intellivon Engineering Approach
Intellivon designs explanations for non-technical users. The goal is to show the evidence behind the risk score in language that revenue teams can act on. At the same time, we translate abstract data weights into simple instructions like “attach authorization form.”
Then the prediction layer must connect to the systems where claims teams already work.
Step 6 — Integrate With EHR, RCM, and Payer Systems
Integration determines whether claims prediction becomes a daily workflow or another disconnected dashboard.
The platform should connect to EHR systems, practice management tools, claim scrubbers, clearinghouses, payer portals, data warehouses, and billing work queues so predictions appear before submission decisions, not after teams have already sent claims out.
Technical Implementation Details
Engineers use secure HL7 and FHIR data exchanges to push risk warnings directly into your existing medical records screen. Consequently, billing teams can see a claim’s danger score without opening a separate software program. The platform also hooks into clearinghouse APIs to check submission statuses automatically.
- Software links push danger scores directly into your daily medical record screens.
- Billing teams review live risk warnings without switching between application tabs.
- Fast API connections check clearinghouse statuses automatically throughout the day.
The Intellivon Engineering Approach
Intellivon plans integrations around claim timing. Predictions must appear before the claim reaches the point where holding, correcting, or escalating it still improves revenue outcomes. We make sure our software fits smoothly into the natural workflow of your existing billing department.
Once integrated, the platform needs compliance controls that match healthcare production risk.
Step 7 — Build HIPAA Compliance, Security, and Audit Controls
HIPAA-compliant claims prediction software needs administrative, physical, and technical safeguards around PHI, access, auditability, encryption, data retention, and vendor governance.
Because claims data contains patient, payer, provider, diagnosis, procedure, and financial information, security design must start before model training and continue through deployment.
Technical Implementation Details
The system locks down all data pipelines using a strict zero-trust architecture where every connection must verify its identity. Next, engineers add role-based access control, ensuring entry-level staff cannot view complete patient histories. Finally, an unchangeable audit trail logs every single model score and human adjustment with an automatic timestamp.
- A zero-trust network forces every internal server to prove its identity constantly.
- Strict login rules ensure staff see only the records needed for their work.
- Tamper-proof logs record every single risk grade and manual change permanently.
The Intellivon Engineering Approach
Intellivon treats compliance as part of architecture, not a launch checklist. Security controls, access rules, audit logs, and model traceability are designed before production data moves into the system. This protective approach keeps patient records safe from the very first day of development.
Compliance creates the guardrails. MLOps keeps the system reliable after payer behavior changes.
Step 8 — Deploy With MLOps and Retraining Triggers
Claims prediction models need MLOps because payer rules, coding patterns, denial reasons, and provider workflows change over time. The platform should monitor drift, prediction accuracy, reviewer overrides, payer-specific performance, and revenue cycle KPIs, then trigger retraining when performance drops or new payer behavior appears.
Technical Implementation Details
Engineers build live model drift monitoring dashboards to track how well the software guesses outcomes over time. If an insurance firm suddenly alters its coverage criteria, the platform spots the drop in prediction accuracy immediately. This performance drop triggers an automated retraining pipeline that updates the machine learning code using fresh billing examples.
- Live tracking dashboards monitor the real-world accuracy of the software daily.
- Automatic alerts flag when an insurance firm alters its payment patterns.
- Automated systems retrain the machine learning code using recent billing examples.
The Intellivon Engineering Approach
Intellivon builds model monitoring into the production roadmap. Each model version should show when it was trained, what data it used, how it performed, and when it needs review. This rigorous tracking stops your software from losing its accuracy as insurance rules change over time.
A successful build requires balancing clean data pipelines with highly secure infrastructure code. Taking the time to set up automated monitoring tools keeps your models accurate even when insurance firms modify their payment rules without warning. After the build path is clear, leadership will ask what the platform should include on day one.
AI Claims Prediction Platform Development Cost
AI claims prediction platform development usually costs $60,000–$180,000 for an MVP or early production build. A focused version with one specialty, limited payer scope, batch denial prediction, and basic dashboards sits near the lower range.
Costs rise when the platform includes real-time EHR integration, payer-specific models, HIPAA controls, explainability, and MLOps.
| Development Phase | Estimated Cost | What It Covers |
| Discovery and RCM Workflow Mapping | $5,000–$12,000 | Claim lifecycle mapping, payer mix, denial categories, MVP scope, ROI assumptions |
| Data Audit and Pipeline Design | $8,000–$20,000 | EDI 837/835 mapping, claims data access, PHI controls, warehouse planning |
| Data Normalization and Label Taxonomy | $8,000–$22,000 | CARC/RARC mapping, denial reason classification, duplicate cleanup, payer normalization |
| Platform UX and Workflow Design | $7,000–$18,000 | Risk dashboards, reviewer queues, claim detail screens, and action recommendations |
| ML Model Development | $15,000–$45,000 | XGBoost, random forest models, payer-specific scoring, calibration, SHAP explanations |
| EHR and Clearinghouse Integrations | $12,000–$38,000 | FHIR APIs, EDI flows, clearinghouse connectivity, payer response ingestion |
| Security, Testing, and MLOps | $10,000–$25,000 | HIPAA controls, audit logs, drift monitoring, retraining triggers, and validation |
Ongoing maintenance usually costs 18%–30% of the initial build per year. This covers payer rule updates, model retraining, integration monitoring, dashboard improvements, and support for new denial patterns.
Cost stays controlled when the MVP targets one high-value claim workflow first. Intellivon helps teams define that roadmap around payer scope, claims data readiness, integration depth, and measurable revenue cycle KPIs before full development begins.
Build vs Buy: When To Create a Custom AI Claims Prediction Platform?
Organizations should build a custom AI claims prediction platform when their payer mix, claim volume, specialty workflows, data ownership needs, or product roadmap require prediction logic that off-the-shelf tools cannot control. Conversely, buying makes sense when a team needs fast deployment, standard claims workflows, limited customization, and lower upfront engineering investment.
The following table contrasts the primary differences between purchasing a package and commissioning a custom build:
| Decision Factor | Buy a Vendor Tool | Build Custom Platform |
| Speed | Faster deployment | Longer build cycle |
| Cost | Lower upfront | Higher upfront |
| Data ownership | Limited by the vendor | Full control |
| Payer-specific logic | May be restricted | Fully customizable |
| Workflow fit | Standard workflows | Complex workflows |
| Model transparency | Varies by vendor | Designed into the platform |
| SaaS product potential | Limited | Strong fit |
| Compliance control | Shared | Fully designed into architecture |
The Core Decision Framework
To finalize a strategic direction, teams can apply these straightforward decision rules:
- Build if: The organization processes high claim volume, needs proprietary payer intelligence, or wants to create a healthcare SaaS product. Custom development is also best when teams need explainable claim-level predictions, custom EHR integrations, or highly localized behavioral modeling.
- Buy if: The network needs basic denial analytics quickly, lacks deep historical claims data, or operates on standard workflows. Purchasing fits well if the organization does not need model ownership and possesses a limited engineering budget.
For a deeper breakdown of broader RCM platform planning, see our guide on AI Revenue Cycle Management Software Development Guide.
The build decision should come from control requirements, not AI ambition. If prediction logic can become a proprietary revenue advantage, custom development becomes easier to justify. Consequently, once leadership approves a custom strategy, the next step is planning the development budget.
HIPAA Compliance for Claims Prediction Software
HIPAA-compliant claims prediction software must protect electronic PHI through administrative, physical, and technical safeguards, including role-based access, encryption, audit controls, data integrity, user authentication, vendor governance, and secure transmission.
Claims prediction also needs model governance because AI outputs influence reimbursement workflows and patient financial responsibility. This dual focus ensures your technology stays lawful and highly reliable.
1. Technical Safeguards for Patient Records
Protecting patient records during live data processing requires a strict digital perimeter. For example, systems must use PHI tokenization to swap sensitive data fields with random strings before files reach the machine learning model.
This keeps patient names and identities completely hidden while the software calculates risk scores.
- Systems remove direct personal identifiers from data flows automatically.
- Networks apply strong encryption both during storage and transit.
- Pipelines run on a zero-trust architecture that checks every access request.
2. Operational Controls and Access Rules
Limiting system access to certified workers keeps data safe from internal breaches. Implementing role-based access control ensures that entry-level billing clerks see only the basic suggestions needed for their work.
Meanwhile, system managers hold separate electronic keys to view complete histories or approve model adjustments.
- Staff accounts hold only the minimum permissions required for their jobs.
- Users must clear multi-factor authentication steps during every login.
- The system changes database access credentials automatically every few months.
3. Immutable Tracking and Audit Trails
A secure platform must maintain permanent records of its automated choices and human interactions. For this reason, an unchangeable audit trail logs every single prediction score, confidence drop, and manual clerk override.
This tracking sheet receives automated timestamps and can never be altered by anyone in the organization.
- Every prediction call saves a permanent history of its variables
- The platform logs the exact user ID for every manual override.
- System logs remain sealed against deletion to satisfy federal auditors.
4. Model Governance and Transparency
AI governance requires tracking how models change over time as insurance rules evolve. Teams must maintain clear model cards and training dataset lineage records to document how the software learns. This documentation proves to compliance teams that the machine learning code evaluates claims fairly without hidden biases.
- Version control registries log when a model gets retrained.
- Feature documentation sheets track which variables influence risk calculations.
- Regular performance checks monitor accuracy across different insurance plans
5. Secure Environments for Development
Engineers must use safe, separate network zones when building and testing software updates. Using synthetic or de-identified data for development allows programmers to train models without exposing real patient records to risk. Furthermore, high-risk outputs always trigger a human-in-the-loop review before taking effect.
- Developers use realistic dummy records to test new math formulas safely.
- Test servers live in isolated environments away from live hospital databases.
- Senior billing experts review complex or high-value flags manually.
Security protects the data, and governance protects the decision process. A claims prediction platform needs both because it sits between clinical documentation, payer rules, and reimbursement outcomes.
Consequently, once your compliance roadmap is secure, the next phase involves breaking down the financial investment required for the build.
Build an AI Claims Prediction Platform With Intellivon
Intellivon helps hospitals, RCM companies, healthcare SaaS platforms, and enterprise care networks build AI claims prediction platforms around real revenue workflows.
The work starts with claim scope, data readiness, payer-specific model design, EHR integration, HIPAA controls, explainability, human review, MLOps, and revenue KPI planning before development moves into production.
A. Define the Right Claims Prediction Scope
Intellivon maps the first build around the claims workflows most likely to reduce denials and improve reimbursement. This prevents teams from building a broad prediction dashboard before they know which payer, specialty, or denial category creates the clearest revenue impact.
- Analyze claim volume by payer, specialty, facility, and denial type.
- Identify preventable denial categories with measurable financial impact.
- Prioritize MVP workflows around high-risk, high-volume claims.
- Define revenue KPIs before model development starts.
- Map reviewer roles for billing, coding, and authorization teams.
B. Design the Platform Architecture Around RCM Operations
Intellivon designs claims prediction architecture around the way revenue teams actually process claims. The platform connects claims data, remittance data, payer responses, model outputs, reviewer queues, and audit logs so every prediction stays traceable from data source to final user action.
- Ingest EDI 837 claims and EDI 835 remittance data.
- Connect EHR, RCM, clearinghouse, and payer response workflows.
- Structure data pipelines for claim-line level prediction.
- Build audit trails for predictions, edits, and reviewer decisions.
- Prepare architecture for real-time and batch scoring workflows.
C. Build Payer-Specific ML Models
Intellivon builds payer-specific ML models because denial behavior changes across commercial payers, Medicare Advantage plans, Medicaid programs, and specialty workflows. The model should not only predict risk. It should explain the likely reason behind that risk.
- Train models on historical claims, payer outcomes, and denial labels.
- Use CARC/RARC codes for denial root cause classification.
- Apply XGBoost, random forest, and calibrated ensemble models.
- Add confidence scoring for safer claim review decisions.
- Use SHAP explanations to show why each claim is risky.
D. Integrate With Healthcare Revenue Systems
Intellivon connects claims prediction workflows with the systems revenue teams already use every day. The goal is to surface denial risk before claim submission, so teams can fix coding, authorization, eligibility, or documentation issues before the payer response arrives.
- Integrate with EHR and practice management systems.
- Connect the clearinghouse, payer portal, and RCM platform workflows.
- Pull eligibility, authorization, coding, and claim status data.
- Push risk scores into billing and reviewer work queues.
- Support dashboards for finance, coding, and revenue leaders.
E. Make the Platform Secure, Monitorable, and Audit-Ready
Intellivon builds the platform with HIPAA-ready security, model monitoring, and audit controls from the start. This matters because claims prediction uses PHI, payer data, financial data, and model outputs that can influence reimbursement decisions.
- Add role-based access controls for different user groups.
- Protect PHI with encryption and secure data handling.
- Maintain immutable audit logs for model and user actions.
- Monitor model drift as payer rules and denial patterns change.
- Set retraining triggers for declining prediction performance.
If you are planning to build an AI claims prediction platform for hospitals, RCM teams, or healthcare SaaS users, Intellivon can help you define the roadmap before development begins.
Conclusion
An AI claims prediction platform works best when it connects data, models, workflows, and governance into one revenue decision layer. The goal is not to predict denials for the sake of analytics. Rather, the goal is to help teams find risky claims early, understand the reason, correct preventable issues, and protect reimbursement with evidence.
For hospitals, RCM companies, and healthcare SaaS platforms, the strongest build starts with a narrow scope, clean claim outcome labels, payer-specific model design, a HIPAA-ready architecture, and measurable revenue KPIs. This focused approach transforms complex data into a production system that billing, coding, finance, and compliance teams can trust completely.
Things To Know About AI Claims Prediction Platforms
Q1. Can AI really predict claim denials before submission?
A1. Yes, AI can predict claim denials before submission when the platform has enough historical claims, remittance outcomes, payer rules, denial codes, and claim correction data. The model should flag high-risk claims, explain the likely denial reason, and route the claim for review before submission. The goal is prevention, not only faster denial recovery.
Q2. What data does an AI claims prediction platform need to work well?
A2. An AI claims prediction platform needs EDI 837 claim data, EDI 835 remittance data, CARC/RARC denial codes, payer information, CPT and ICD-10-CM codes, authorization status, eligibility data, and historical claim outcomes. Strong models also need claim-line history, correction patterns, appeal outcomes, and payer-specific denial behavior.
Q3. Will AI claims prediction replace billers and coders?
A3. No, AI claims prediction should not replace billers and coders in complex revenue workflows. Coders worry about AI missing context, choosing wrong codes, adding incorrect modifiers, or creating extra denial cleanup. A safer platform should support human review, show evidence, and let billing teams override risky recommendations.
Q4. What do billing teams actually want from AI denial tools?
A4. Billing teams want AI tools that reduce manual denial work, not tools that create more investigation. Discussions around denials show that teams struggle with vague denial codes, payer follow-up, coding issues, appeals, and claim write-offs. A useful platform should explain why a claim is risky and suggest the next practical correction.
Q5. Does an AI claims prediction platform need HIPAA and BAA controls?
A5. Yes, an AI claims prediction platform needs HIPAA-ready security and BAA controls if it handles PHI. Healthcare IT discussions show that vendors handling PHI are expected to complete a security review and BAA approval before data sharing begins. The platform should include access controls, audit logs, encryption, PHI protection, and model traceability.