Key Takeaways:
-
Self-learning fraud engines continuously model normal payment behavior and retrain on every confirmed outcome, replacing static rules that miss evolving attack patterns.
-
Effective engines layer supervised models, anomaly detection, graph AI, sequence models, and ensemble scoring to cover both known fraud and zero-day threats simultaneously.
-
Real-time scoring requires streaming infrastructure, feature stores, model-serving APIs, and a rules engine working together inside the transaction flow, not after it completes.
-
Build costs range from $25,000 for an MVP scoring engine to $300,000 and above for regulated multi-region fraud infrastructure with governance, compliance layers, and cross-border risk scoring.
-
How Intellivon builds self-learning fraud detection engines your enterprise fully owns, with real-time decisioning, continuous feedback loops, and audit-ready explainability from day one.
Payment enterprises today deal with fraud patterns that change faster than engineering teams can realistically respond to. Synthetic identity attacks, account takeover attempts, and card testing operations rarely look suspicious on entry, and by the time a rule catches them, the pattern has already shifted. Static rule engines and fixed thresholds, however well-configured, create two compounding problems at scale: they miss fraud that falls outside historical patterns, and they flag legitimate customers whose behavior simply does not fit a rigid parameter.
A self-learning fraud detection engine approaches this differently. Rather than matching transactions against fixed logic, it builds a continuous model of normal payment behavior across users, channels, and geographies, flags deviations in real time, and re-trains on new data with every decision it makes. Over time, therefore, the system gets sharper, not because rules were updated, but because the model learned.
At Intellivon, we build enterprise-grade AI fraud detection systems for payment platforms operating across high transaction volumes, multiple geographies, and strict regulatory environments. What we consistently find is that most detection infrastructure is engineered to catch known threats. Building one that learns from new ones is a different problem entirely, and that is exactly what this blog covers.

Why Enterprises Are Adopting Self-Learning Fraud Detection Engines
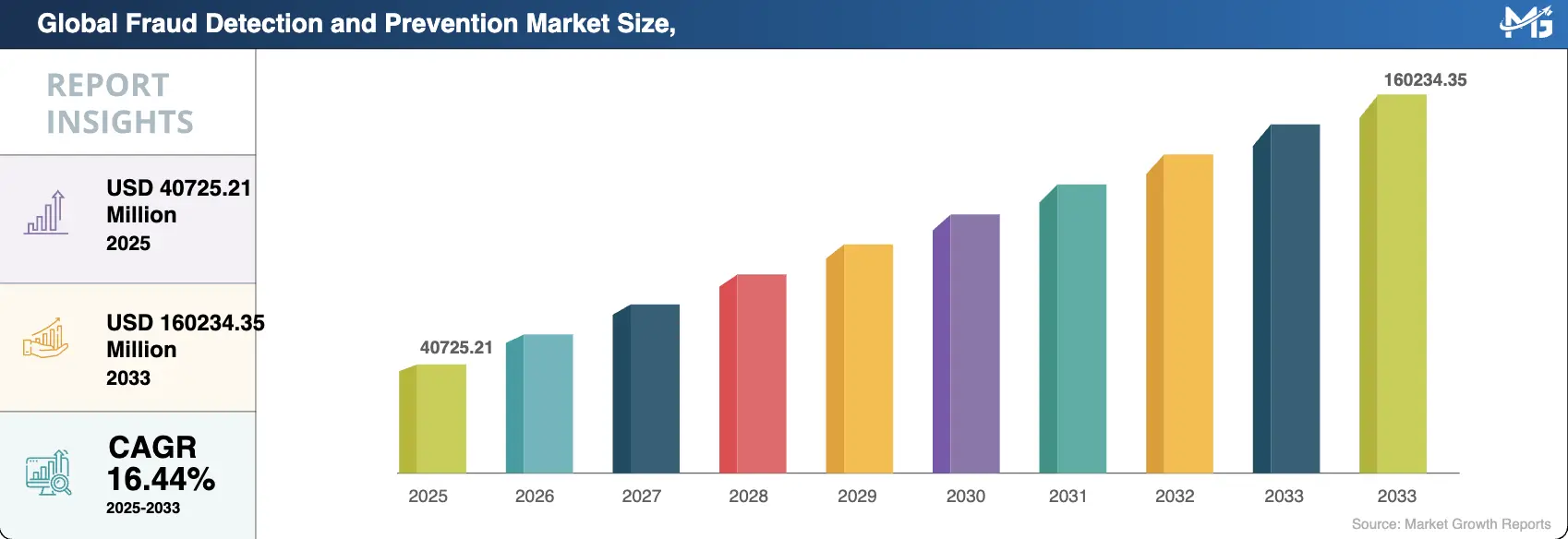
The global fraud detection market is on track to grow from USD 40.7 billion in 2025 to USD 160.2 billion by 2034, expanding at a CAGR of 16.44%, and that growth reflects how quickly fraud has outpaced the systems that were built to stop it, and how many enterprises are now investing in detection infrastructure that can actually keep up.
1. Evolving Threat Landscape
Fraud tactics have grown considerably more sophisticated over the past few years. Deepfakes, adaptive bots, and coordinated identity attacks now move faster than traditional rule-based systems can track, which is why 64% of enterprises are actively investing in self-learning detection models.
These engines apply unsupervised machine learning to identify novel patterns without needing labeled examples, resulting in 25% fewer false positives and response times that are 60% faster than conventional approaches.
2. Regulatory and Efficiency Pressures
Stricter compliance frameworks like PSD3, combined with the sheer volume of digital transactions, are pushing enterprises toward more scalable infrastructure. Currently, 65% of firms use machine learning in their fraud operations, up from 48% in 2022.
Cloud-based detection engines process large transaction datasets in milliseconds, which significantly reduces manual review workloads and improves overall authorization rates.
3. Sector-Specific Gains
BFSI leads adoption at 34%, with payment loss reductions of 28% reported across institutions. Retail and healthcare follow closely, using behavioral analytics to prevent roughly 19% of billing fraud.
More broadly, over 90% of banks now deploy AI and ML in some capacity, with efficiency gains ranging between 40% and 60%.
Self-learning engines help enterprises stay ahead of emerging risks rather than react to them, consistently delivering around 95% detection accuracy. As biometric integration is projected to reach 70% by 2030, fraud prevention is increasingly becoming a core strategic function rather than a compliance checkbox.
What Is a Self-Learning Payment Fraud Engine?
A self-learning payment fraud detection engine is a machine learning system that continuously analyzes transaction data to identify fraudulent behavior. Unlike rule-based systems, it does not rely on fixed logic.
Instead, it builds a model of normal payment behavior, detects deviations in real time, and re-trains itself as new fraud patterns emerge. Over time, the system becomes more accurate without requiring manual rule updates.
1. How It Learns From Live Payment Outcomes
Every successful or blocked payment provides a new data point for the system. The engine analyzes these outcomes to understand the difference between legitimate customer behavior and criminal intent.
Consequently, it adjusts its internal logic without needing a developer to write new code manually. This creates a feedback loop where the system grows smarter after every single interaction.
- Feedback Integration: The system ingests labels from bank chargebacks or manual flags to refine its accuracy.
- Pattern Recognition: It identifies subtle shifts in user behavior that might indicate a compromised account.
- Real Time Calibration: Risk scores change instantly based on the latest global fraud trends seen across the network.
This continuous evolution ensures your security stack remains effective against emerging threats.
2. How It Differs From Static Rule Engines
Traditional systems rely on rigid statements. While these rules are clear, they are often too brittle to catch sophisticated modern attacks. Static engines require constant manual updates.
This can leave gaps in your defense for weeks. In contrast, a self-learning engine identifies complex relationships between data points that a human might never notice.
- Flexibility: Self-learning systems handle gray area transactions that do not fit into neat categories.
- Maintenance: Static rules create a massive backlog of manual work for your engineering team.
- Speed: Machine learning models react to new fraud patterns in milliseconds rather than days.
Therefore, moving away from static logic reduces the number of false positives that frustrate your good customers.
3. Why Self-Learning Does Not Mean Fully Autonomous
Technology handles the heavy lifting, but it still requires strategic oversight from your leadership team. Self-learning implies the ability to improve through data rather than making high-level business decisions alone.
You must still set the risk appetite that aligns with your specific market and customer base. The engine provides the intelligence while your team provides the essential context and guardrails.
- Risk Thresholds: Executives must decide when a transaction is too risky to process, regardless of the AI score.
- Model Governance: Regular audits ensure the machine is not developing biases that could block legitimate revenue.
- Strategic Alignment: The system follows the goals you define for growth versus security.
Strategic control remains in human hands even as the underlying technology becomes more sophisticated.
4. Where AI, Rules, and Human Review Work Together
The most effective platforms use a layered approach to stop financial crime. AI handles the massive scale of data while traditional rules enforce absolute legal or regional requirements.
However, complex cases still benefit from the nuanced judgment of a human fraud analyst. This hybrid model provides a safety net that maximizes both security and operational efficiency.
- Hard Rules: These enforce non-negotiable limits such as sanctioned country lists or maximum daily spends.
- Machine Learning: This layer predicts the probability of fraud based on thousands of hidden variables.
- Analyst Review: Human experts investigate high-value anomalies to provide the final word on difficult cases.
This collaboration creates a robust environment where technology and human expertise complement each other perfectly.
Who Needs a Self-Learning Fraud Engine?
Fintech platforms, PSPs, digital banks, marketplaces, and high-volume enterprises need self-learning fraud engines when static rules create losses, delays, or false declines. This technology is no longer a luxury but a necessity for maintaining a competitive edge.
1. Fintech Platforms Handling High Payment Volumes
High-growth fintech companies process thousands of transactions per second across diverse geographic regions. Managing this scale manually is impossible and leads to significant operational bottlenecks.
Therefore, a self-learning engine is vital to automate the heavy lifting of risk assessment. It allows your team to focus on strategy rather than reviewing every suspicious flag.
- Scalability: The system handles massive spikes in traffic without a drop in detection quality.
- Cost Efficiency: Automating fraud checks reduces the need for a massive team of human reviewers.
- Global Reach: It identifies localized fraud patterns across different markets and currencies automatically.
Efficiency at scale ensures your platform remains profitable while keeping users safe from sophisticated attacks.
2. Digital Banks With Real-Time Transaction Risk
Digital banks operate in a world where customers expect instant results and zero friction. Any delay in processing can lead to a poor user experience and lost trust. However, real-time banking also attracts bad actors looking for quick exploits.
A self-learning engine provides the speed required to verify transactions in milliseconds without compromising on security.
- Instant Verification: The engine scores risk in real-time to allow for seamless money movement.
- Behavioral Analysis: It notices if a customer is suddenly acting out of character for their profile.
- Regulatory Compliance: Automated systems help maintain strict standards for anti-money laundering and safety.
Protecting the digital banking ecosystem requires a balance of extreme speed and deep analytical precision.
3. PSPs Managing Merchant and Card Fraud
Payment Service Providers (PSPs) sit at the center of the financial ecosystem and face risks from many sides. They must protect their own infrastructure while also shielding their diverse merchant base from chargebacks. Furthermore, they need to detect stolen card usage before it drains merchant accounts.
A self-learning engine creates a unified defense layer that protects every participant in the chain.
- Merchant Protection: The system flags suspicious buyers to prevent costly chargeback fees for sellers.
- Card Testing Detection: It identifies bot-driven attempts to validate stolen credit card numbers.
- Network Effects: Data from one merchant can help the engine stop fraud for others.
Stronger protection for merchants leads to higher retention and a better reputation for your processing services.
4. Marketplaces With Multi-Party Payment Flows
Marketplaces face unique challenges because money moves between buyers, sellers, and the platform itself. These multi-party flows create more opportunities for collusion or account takeovers.
Traditional rule engines struggle to map these complex relationships effectively. However, machine learning excels at identifying hidden links between seemingly unrelated accounts.
- Collusion Detection: The engine spots patterns where buyers and sellers work together to game the system.
- Payout Security: It ensures that funds are only released to verified and legitimate sellers.
- Account Takeovers: The system monitors login habits to stop criminals from hijacking established profiles.
Securing the entire marketplace journey builds the trust necessary for your community to thrive and grow.
5. Enterprises Losing Revenue to False Declines
Many large companies lose more money to false declines than they do to actual fraud. When a rigid system blocks a legitimate customer, you lose the immediate sale and future lifetime value.
A self-learning engine provides a more nuanced risk score that separates true threats from honest buyers. This shift directly increases your top-line revenue by approving more good orders.
- Revenue Recovery: Better accuracy means fewer legitimate transactions are wrongly rejected at checkout.
- Customer Loyalty: Buyers stay happy when their payments go through without unnecessary friction.
- Precision Scoring: The system uses more data points to give a fair assessment of every user.
Reducing false positives is the fastest way to turn your security stack into a growth engine.
How Does a Self-Learning Fraud Engine Work?
Understanding the mechanical flow of data is essential for leaders evaluating these technical investments. The system operates as a high-speed pipeline that converts raw data into actionable security decisions.
A self-learning fraud engine scores every payment in real time, applies business rules, routes decisions, and uses confirmed outcomes to improve future detection.
This architecture ensures that your enterprise stays ahead of sophisticated financial criminals.
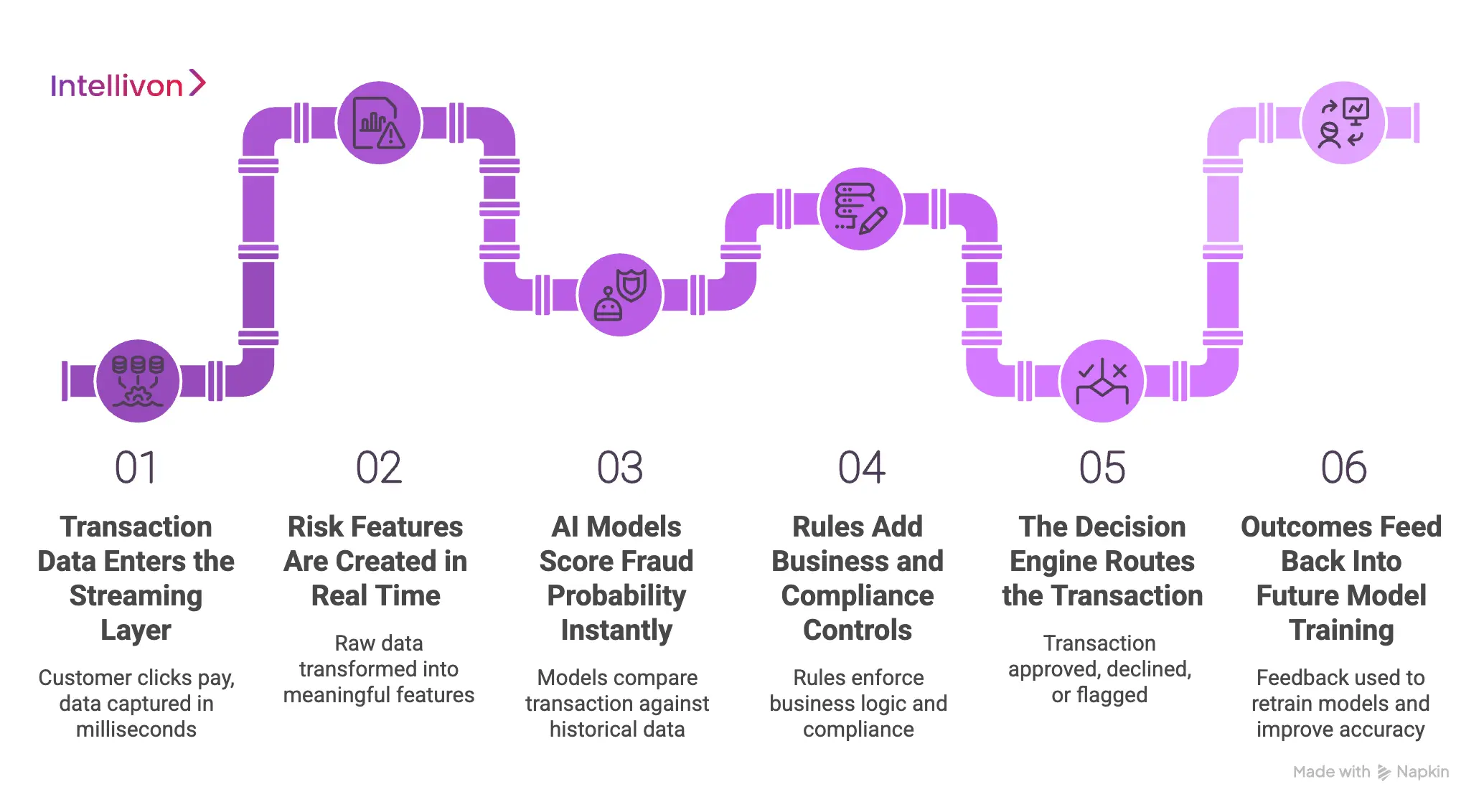
1. Transaction Data Enters the Streaming Layer
The process begins the moment a customer clicks the pay button on your platform. A streaming data layer captures hundreds of distinct data points from the user and the device.
This information moves through the system in milliseconds to ensure there is no lag in the checkout experience. Therefore, the engine can analyze the context of the payment while it is still in progress.
- Data Ingestion: The system pulls in IP addresses, device fingerprints, and purchase history.
- Stream Processing: High-speed infrastructure handles massive bursts of traffic during peak shopping hours.
- Contextual Metadata: It gathers environmental signals such as the time of day and the location.
Reliable data ingestion is the foundation of any successful automated risk management strategy.
2. Risk Features Are Created in Real Time
Raw data must be transformed into meaningful features that the AI can actually understand. For example, the system might calculate how many times a specific card was used in the last hour.
These features provide a much deeper level of insight than a single data point ever could. Consequently, the engine builds a multi-dimensional view of the transaction risk profile instantly.
- Velocity Checks: The engine tracks the speed and frequency of transactions from a single source.
- Behavioral Biometrics: It analyzes how a user interacts with the screen or types their information.
- Identity Mapping: The system connects the current payment to known historical patterns for that user.
Feature engineering allows the machine to spot subtle red flags that traditional filters would miss entirely.
3. AI Models Score Fraud Probability Instantly
Once the features are ready, the core machine learning models take over the heavy lifting. The engine compares the current transaction against millions of previous examples of both good and bad payments.
It then generates a numerical risk score that represents the mathematical probability of fraud. This happens in the blink of an eye to keep the user journey fluid and fast.
- Predictive Analysis: The model identifies hidden correlations that suggest a high risk of a chargeback.
- Anomaly Detection: It flags payments that deviate significantly from established normal behavior.
- Probability Weighting: The system assigns a specific confidence level to every individual risk assessment.
Using AI for scoring provides a level of precision that manual rules simply cannot match.
4. Rules Add Business and Compliance Controls
AI handles the complex patterns, but your specific business logic still plays a vital role. You might have legal requirements or internal policies that the machine must strictly follow.
Therefore, a rules layer sits alongside the AI to enforce these non-negotiable boundaries. This combination ensures that your security stays flexible while remaining compliant with global financial regulations.
- Regulatory Guardrails: These rules block payments from restricted regions or sanctioned individuals.
- Custom Limits: You can set maximum transaction values based on your specific risk appetite.
- Conditional Logic: The system can trigger extra verification steps for high-value orders only.
Integrating rules with AI gives you the perfect balance of automation and strategic control.
5. The Decision Engine Routes the Transaction
The final decision is made based on the combined output of the AI and the rules. Depending on the risk score, the engine will either approve, decline, or flag the payment for review.
Furthermore, it can route the transaction through different verification paths like 3D Secure or SMS codes. This dynamic routing ensures that only the most suspicious payments face extra friction.
- Automated Approval: Low-risk transactions pass through instantly to maximize your conversion rates.
- Stepped-Up Authentication: Medium-risk users are asked for a secondary form of identification.
- Hard Declines: The system blocks high-risk attempts before they can damage your bottom line.
Smart routing protects your revenue while providing a smooth experience for your loyal customers.
6. Outcomes Feed Back Into Future Model Training
The most important step for a self-learning system happens after the transaction is complete. The engine receives updates on whether a payment resulted in a chargeback or a legitimate sale.
It uses this feedback to retrain its models and improve its future accuracy. In addition, this creates a virtuous cycle where the system becomes more effective with every passing day.
- Labeling Feedback: Confirmed fraud cases are marked to teach the model what to avoid.
- Continuous Learning: The system updates its logic without requiring manual software deployments.
- Performance Monitoring: Your team can track how detection accuracy improves as the dataset grows.
This closing of the loop is what makes the engine truly self-learning and resilient.
What Data Powers Payment Fraud Decisions?
A self-learning engine is only as effective as the data it consumes. Therefore, high-quality inputs from across your digital ecosystem are essential for accurate risk scoring.
Payment fraud engines use transaction, device, user, merchant, location, network, chargeback, and analyst-review data to detect suspicious behavior in context. The more diverse your data sources are, the harder it becomes for criminals to find a blind spot.
1. Transaction Amount, Frequency, and Velocity
The core of any fraud check begins with the basic details of the payment itself. However, the engine looks beyond the single dollar amount to see the broader context.
It analyzes the speed at which transactions are occurring from a single source. Rapid-fire payments often signal a bot-driven attack or card testing behavior.
- Transaction Size: The system flags amounts that are unusually high for a specific user or product.
- Velocity Limits: It tracks how many payments occur within a minute or an hour.
- Currency Shifts: The engine notices if a user suddenly switches to a high-risk foreign currency.
These baseline metrics act as the first line of defense in your security architecture.
2. Device Fingerprint and Session Intelligence
Criminals often use emulators or specialized software to hide their true identities. A modern engine collects a unique digital fingerprint from the hardware used to make the purchase.
It looks at browser settings, screen resolution, and operating system versions. Consequently, it can identify if a single device is being used to access hundreds of different accounts.
- Hardware ID: The system recognizes the specific phone or laptop used for the transaction.
- Emulator Detection: It spots signs that a user is running virtual software to spoof their device.
- Session Duration: The engine monitors how long a user spends on a page before buying.
Identifying the physical source of a transaction makes it much harder for fraudsters to scale their operations.
3. User Behavior and Historical Payment Patterns
Legitimate customers usually follow predictable habits over time. A self-learning engine builds a profile of what normal looks like for every individual user. It analyzes past purchase categories, typical login times, and preferred payment methods.
Therefore, any sudden deviation from this history triggers an immediate investigation.
- Buying Habits: The system flags a sudden purchase in a high-risk category like gift cards.
- Login Consistency: It notices if a user logs in from a new city at an odd hour.
- Method Preferences: The engine identifies when a user tries five different cards in a row.
Focusing on behavior allows you to protect accounts even if the attacker has the correct credentials.
4. Merchant Category and Entity-Level Risk
Not all merchants or products carry the same level of inherent risk. For example, selling digital software keys is more susceptible to fraud than shipping physical furniture.
The engine incorporates these merchant-level insights into its final decision. It adjusts the sensitivity of the model based on the specific industry and historical chargeback rates for that category.
- Industry Benchmarks: The system compares transaction risk against similar businesses in the same sector.
- Product Risk: High-resale items like electronics receive more scrutiny than low-value goods.
- Entity Mapping: It tracks the reputation of the specific merchant or sub-merchant involved.
Customizing risk levels for different business types ensures that your security remains fair and effective.
5. Location, IP, Proxy, and Network Signals
The network path that a transaction takes reveals a lot about its legitimacy. Fraudsters frequently use VPNs or proxy servers to appear as if they are in a different country.
A sophisticated engine analyzes the IP address to see if it belongs to a known data center or a residential home. In addition, it checks for geographic inconsistencies between the IP and the shipping address.
- IP Reputation: The engine blocks addresses that have a history of malicious activity.
- Proxy Piercing: It attempts to find the true location behind a masked connection.
- Distance Logic: The system flags orders where the IP location is thousands of miles from the card origin.
Network intelligence provides a vital layer of geographic context to every risk assessment.
6. Chargebacks, Disputes, and Analyst Decisions
This is the data that powers the self-learning aspect of the system. Every time a bank confirms a chargeback, that information is fed back into the engine. Similarly, the decisions made by your human review team serve as a training guide.
Over time, the AI learns to mirror the logic of your best analysts but at a much higher speed.
- Ground Truth: Confirmed fraud cases provide the definitive labels needed for model training.
- Analyst Feedback: The system learns from why a human expert approved or declined a case.
- Dispute Outcomes: It identifies which types of transactions are most likely to be contested later.
Closing this data loop is what allows the engine to improve and stay relevant in a changing threat landscape.
What AI Models Should the Fraud Engine Use?
Selecting the right mathematical framework is a critical decision for any enterprise building a resilient defense. Therefore, using a combination of specialized models provides the most comprehensive protection against diverse threat vectors.
Enterprise fraud engines usually combine supervised learning, anomaly detection, graph models, sequence models, and explainable AI to improve detection accuracy.
A multi-model approach ensures that your system remains robust even as criminal tactics shift.
1. Supervised Models for Known Fraud Patterns
Supervised learning acts as the workhorse for identifying established types of financial crime. These models are trained on massive datasets of historical transactions that are already labeled as good or bad.
Consequently, the system becomes highly efficient at spotting the specific signatures of traditional theft and card abuse. This provides a reliable baseline for your security operations.
- Historical Training: The model learns from millions of past outcomes to predict future risk accurately.
- High Precision: It excels at catching common fraud types with a very low margin of error.
- Fast Inference: These models provide scores in milliseconds to keep checkout speeds high.
Relying on supervised learning is the most effective way to automate the detection of known threats at scale.
2. Unsupervised Models for Anomaly Detection
Criminals often invent new methods that have no historical precedent in your database. This is where unsupervised models become essential because they do not require labeled data to function.
Instead, they look for transactions that simply do not belong or look suspicious compared to the norm. In addition, they help you identify zero-day attacks before they become a widespread problem.
- Zero-Day Protection: The system flags brand-new fraud tactics that have never been seen before.
- Clustering Logic: It groups similar transactions and identifies outliers that deviate from the pack.
- Trend Identification: The engine notices sudden shifts in global payment behavior that signal an emerging threat.
Anomaly detection ensures that your platform is never caught off guard by innovative criminal strategies.
3. Graph Models for Fraud Ring Detection
Modern fraud is rarely the work of a single person acting alone. Instead, organized crime rings use networks of hundreds of accounts to move stolen funds.
Graph models analyze the connections between different entities like IP addresses, device IDs, and email accounts. Therefore, they can visualize and block entire criminal networks rather than just stopping one transaction.
- Link Analysis: The engine finds hidden relationships between seemingly unrelated user accounts.
- Network Visualization: It maps out how money moves through your platform to identify bottlenecks.
- Sybil Attack Defense: These models stop fraudsters from creating thousands of fake profiles to overwhelm your system.
Using graph technology allows you to dismantle the infrastructure of professional fraud organizations.
4. Sequence Models for Behavioral Risk Changes
Fraud is often a process rather than a single event. A sequence model looks at the entire history of a user’s actions leading up to a payment. For instance, it might notice if a user changed their password and then immediately attempted a high-value purchase.
This temporal context is vital for separating legitimate account updates from malicious takeovers.
- Time-Series Analysis: The system monitors the order and timing of user actions across the platform.
- Contextual Risk: It evaluates how a single action fits into the broader timeline of the account.
- Pre-Transaction Signals: The engine flags suspicious behavior before the payment even begins.
Analyzing the sequence of events provides a much deeper understanding of the user’s true intent.
5. Ensemble Models for More Reliable Scoring
No single AI model is perfect on its own. An ensemble approach combines the outputs of several different models to reach a final consensus.
For example, it might weigh the supervised score against the anomaly detection score to determine the final risk level. This reduces the risk of false positives and ensures a more balanced and reliable decision.
- Weighted Voting: Different models contribute to the final score based on their historical accuracy.
- Reduced Bias: Combining multiple perspectives prevents the system from developing narrow blind spots.
- Enhanced Stability: The system remains accurate even if one specific model experiences a temporary dip in performance.
Ensemble modeling creates a sophisticated check-and-balance system within your AI architecture.
6. Explainable AI for Fraud and Risk Teams
Decision makers must understand why a specific transaction was blocked to maintain trust and compliance. Explainable AI (XAI) provides a clear breakdown of the factors that led to a high risk score. This transparency is crucial for your human analysts when they need to investigate a difficult case.
Furthermore, it helps your legal team prove that your security measures are fair and non-discriminatory.
- Feature Importance: The system lists the top reasons why a transaction was flagged as suspicious.
- Audit Readiness: Clear explanations make it easier to comply with financial regulations and audits.
- Analyst Empowerment: Human experts can make better decisions when they see the logic behind the AI score.
Transparency in AI is a functional requirement for any enterprise operating in a regulated environment.
What Architecture Supports Real-Time Fraud Scoring?
Building a fraud engine requires a high-performance technical stack capable of processing data in milliseconds. Consequently, your architecture must balance extreme speed with the complexity of deep analytical processing.
Real-time fraud scoring needs streaming infrastructure, feature stores, model-serving APIs, decision engines, analyst workflows, and monitoring systems working together.
This structural foundation ensures your security scales alongside your transaction volume.
1. Streaming Infrastructure for Payment Events
The architecture begins with a robust messaging backbone that handles incoming transaction data. This layer ensures that every click and payment attempt is captured without data loss.
Therefore, your system can react to threats the moment they appear on the network. Modern enterprises rely on distributed streaming to maintain high availability during peak traffic periods.
- Event Capture: The system ingests raw signals from mobile apps and web checkouts instantly.
- Buffering: High-speed queues manage data spikes to prevent downstream system crashes.
- Persistence: Every event is logged for future audit trails and model retraining.
Reliable streaming is the vital first step in converting raw traffic into actionable intelligence.
2. Feature Store for Live and Historical Signals
A feature store acts as a centralized library for the data points your AI needs to make decisions. It serves both real-time data, like current session length, and historical data, like six-month spending averages.
In addition, it ensures that your models have access to consistent information across both training and production environments. This consistency is critical for maintaining high detection accuracy.
- Latency Optimization: The store retrieves complex user profiles in a few milliseconds.
- Point-in-Time Correctness: It ensures models see data exactly as it existed during the transaction.
- Unified Access: Both data scientists and production APIs use the same verified data source.
Efficient feature management allows your engine to analyze a user’s entire history in the blink of an eye.
3. Model Serving Layer for Low-Latency Scoring
The model serving layer is the engine room where the mathematical heavy lifting happens. It hosts your trained AI models and exposes them via high-speed APIs.
When a transaction arrives, this layer calculates the risk score and returns it to the decision engine. However, it must be optimized for low latency to avoid causing delays at checkout.
- Horizontal Scaling: You can add more compute power as your transaction volume grows.
- Model Versioning: The system allows you to test new AI models without taking the platform offline.
- Performance Isolation: Heavily loaded models do not slow down other parts of the payment flow.
Speed at this layer is the difference between a smooth customer experience and a frustrated cart abandonment.
4. Rules Engine for Risk and Compliance Logic
While AI predicts probability, the rules engine enforces your absolute business requirements. This layer allows non-technical risk managers to update policies without writing new code.
Therefore, you can respond to new regulatory changes or local fraud spikes in minutes rather than days. It provides a necessary layer of human-defined logic over the machine’s predictions.
- Policy Enforcement: The engine blocks transactions that violate regional laws or internal limits.
- Dynamic Adjustment: Risk teams can tighten or loosen rules based on current threat levels.
- Boolean Logic: It handles clear-cut decisions like blocking specific high-risk IP ranges.
The rules engine provides the strategic agility needed to manage a global payment footprint.
5. Decision Engine for Approve, Block, or Review
The decision engine is the final arbiter that combines all signals into a single action. It looks at the AI score, the rules output, and the merchant context to choose the best path.
Furthermore, it can initiate secondary authentication steps if a transaction falls into a gray area. This centralized logic ensures that every payment is handled consistently across your entire organization.
- Action Routing: The system sends instructions to either process, stop, or hold the payment.
- Friction Management: It triggers tools like 3D Secure only when the risk justifies the interruption.
- Unified Logic: One engine manages decisions for all platforms, including mobile and web.
Centralizing the decision logic simplifies your architecture and makes your security easier to manage.
6. Case Management Layer for Fraud Analysts
Not every decision can be fully automated by a machine. The case management layer provides a workspace for your human experts to investigate suspicious flags. It displays all the relevant data, including the AI’s reasoning and the user’s history, in a single view.
Consequently, your team can make fast, informed judgments on high-value or complex cases.
- Evidence Visualization: Analysts can see linked accounts and behavioral anomalies clearly.
- Workflow Automation: The system assigns cases to the right team members based on priority.
- Feedback Capture: Every human decision is recorded to help retrain the AI models.
Effective case management turns human expertise into a scalable part of your fraud defense.
7. Monitoring Layer for Drift, Bias, and Accuracy
Even the best AI systems can lose accuracy over time as fraud patterns change. The monitoring layer tracks the performance of your models in real-time to detect any drop in detection rates.
In addition, it watches for algorithmic bias to ensure your system treats all legitimate customers fairly. This ongoing oversight is essential for maintaining a high-quality security posture.
- Drift Detection: The system alerts you if the incoming data changes significantly from the training set.
- Accuracy Metrics: You can track the ratio of false positives to true fraud captures daily.
- Health Dashboards: Executives get a high-level view of system performance and saved revenue.
Constant monitoring ensures that your investment in AI continues to deliver a high return.
| Layer | Purpose | Example Components |
| Data ingestion | Captures live payment events | Kafka, Kinesis |
| Processing | Cleans and enriches signals | Flink, Spark |
| Feature store | Serves real-time risk features | Feast, Redis |
| Model layer | Scores fraud probability | Python, ML models |
| Rules layer | Applies business logic | Rules engine |
| Decision API | Routes approve/block/review | Node.js, .NET, Python |
| Monitoring | Tracks drift and accuracy | BI, observability tools |
This structured approach ensures every component of your fraud engine works in perfect harmony.
How To Build a Fraud Engine Step by Step?
Building an enterprise-grade engine is a complex engineering feat that requires a structured and professional approach. At Intellivon, we follow a rigorous lifecycle to transform raw transaction data into a sophisticated, self-learning defense system.
Building a fraud engine requires auditing fraud gaps, mapping data, creating pipelines, training AI models, deploying APIs, and adding feedback loops.
Following these steps ensures your infrastructure is both resilient and future-proof against evolving financial threats.
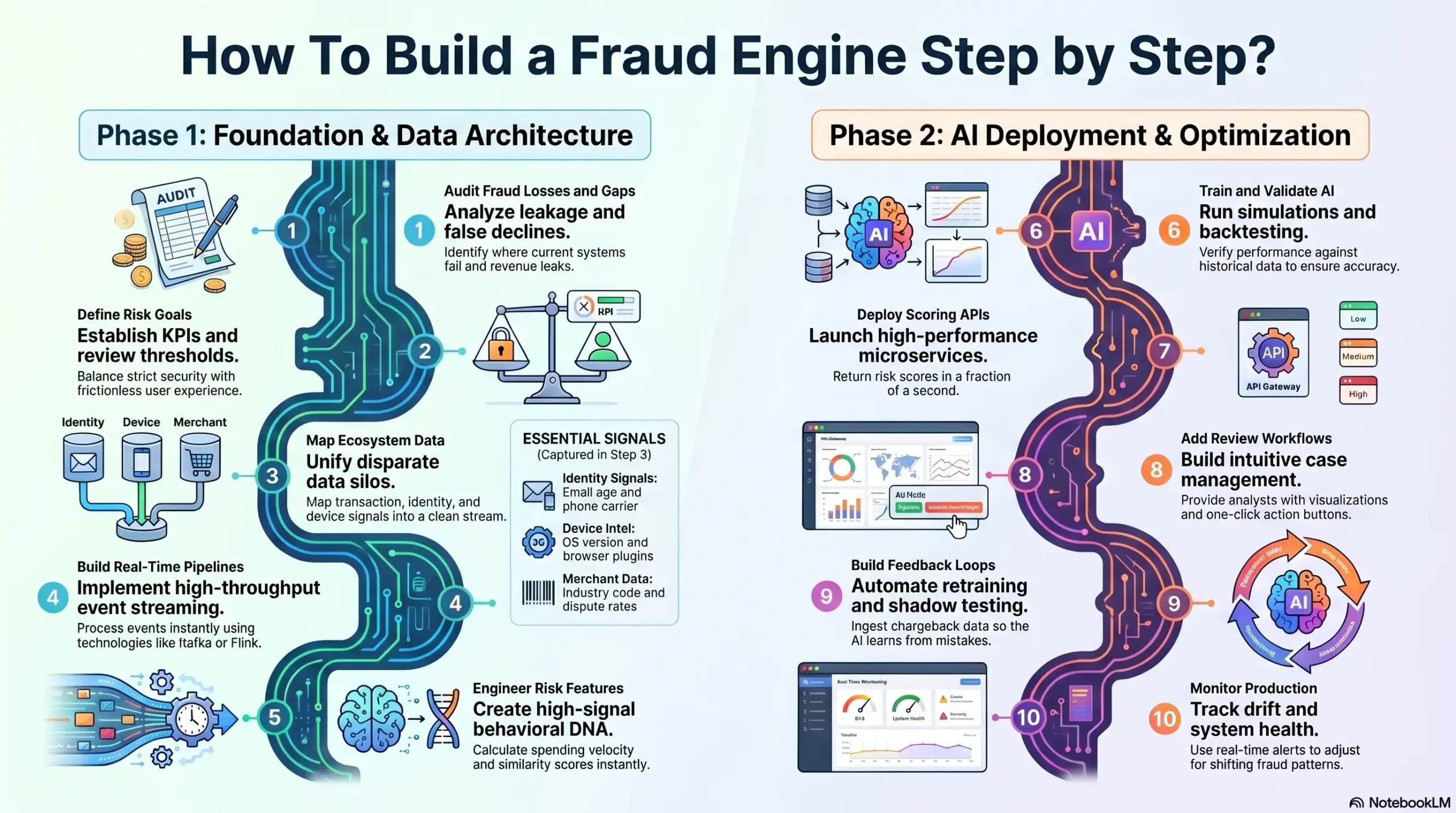
Step 1: Audit Current Fraud Losses and Gaps
We begin by identifying exactly where your current system is failing and where revenue is leaking. Our team analyzes your historical chargeback data to uncover hidden patterns that manual rules have missed.
Therefore, we can pinpoint specific weaknesses in your checkout flow or merchant onboarding process. This diagnostic phase sets the baseline for all future performance improvements and ROI tracking.
- Leakage Analysis: We identify the specific fraud types, such as friendly fraud or account takeover, hitting your bottom line.
- False Decline Review: Our experts calculate how much revenue you are losing to over-zealous security filters.
- Tech Stack Audit: We evaluate your existing data infrastructure to ensure it can support real-time AI processing.
Step 2: Define Risk Goals and Review Thresholds
Strategic alignment is vital because every business has a different appetite for risk. We work with your leadership to define the perfect balance between strict security and a frictionless user experience.
Consequently, we establish clear Key Performance Indicators (KPIs) that guide how the AI should prioritize different transaction types. This ensures the technology serves your specific business objectives rather than operating in a vacuum.
- KPI Setting: We define targets for maximum chargeback rates and minimum approval percentages.
- SLA Definition: Our team sets the latency requirements to ensure fraud checks never slow down your customers.
- Escalation Paths: We map out which transactions require instant blocking and which need human intervention.
Step 3: Map Payment, User, and Merchant Data
A powerful engine requires a holistic view of the entire payment ecosystem. We map out every available data source, from raw transaction logs to third-party identity verification signals.
In addition, we ensure that data from disparate silos is unified into a single, clean stream for the AI. This comprehensive mapping creates a rich context that makes it nearly impossible for fraudsters to hide.
| Data Category | Key Signals Captured |
| Core Transaction | Amount, currency, payment method, and timestamp |
| Identity Signals | Email age, phone carrier, and social profile links |
| Device Intel | OS version, screen resolution, and browser plugins |
| Merchant Data | Industry code, tenure, and historical dispute rates |
Step 4: Build Real-Time Data Pipelines
Speed is the most critical factor in modern fraud prevention. We build high-throughput pipelines using technologies like Kafka and Flink to process events as they happen.
Therefore, your engine can analyze a transaction and return a score before the payment gateway even responds. Our architecture is designed to handle massive scale without ever dropping a single data point.
- Event Streaming: We implement low-latency ingestion to capture user behavior in real-time.
- Data Enrichment: Our pipelines automatically add external context, such as IP reputation, to every event.
- Fault Tolerance: We build redundant systems to ensure your fraud engine stays online even during cloud outages.
Step 5: Engineer Fraud Risk Features
Raw data must be converted into high-signal features that represent the “DNA” of a transaction. We build a centralized feature store that calculates complex variables like a user’s 30-day spending velocity instantly.
This step allows the AI to see the “big picture” rather than looking at an isolated payment. Consequently, the model can spot subtle anomalies that suggest a coordinated bot attack.
- Velocity Features: We track how often a card is used across different merchants in your network.
- Similarity Scores: Our system compares the current user’s behavior to known fraudulent profiles.
- Temporal Logic: We analyze the time elapsed between account creation and the first high-value purchase.
Step 6: Train and Validate AI Models
We use your historical data to train a variety of machine learning models tailored to your specific industry. Our data scientists run thousands of simulations to ensure the models are accurate and free from bias.
Furthermore, we use advanced validation techniques to prove that the AI can catch new fraud patterns it hasn’t seen before. This ensures that the system you deploy is battle-tested and ready for production.
- Model Selection: We choose the best mix of supervised and unsupervised algorithms for your use case.
- Backtesting: We run the new models against a year of historical data to verify their performance.
- Bias Auditing: Our team ensures the AI does not unfairly flag legitimate users based on geographic data.
Step 7: Deploy Real-Time Scoring APIs
Once the models are ready, we deploy them as high-performance APIs within your payment flow. These APIs receive the transaction data and return a risk score in a fraction of a second.
We utilize containerized environments to ensure that the scoring layer is both fast and easily scalable. Therefore, your platform can handle holiday shopping peaks with the same precision as a quiet Tuesday.
- Microservices Setup: We host models in isolated environments to prevent system-wide bottlenecks.
- API Security: Every request is encrypted and authenticated to protect your sensitive financial data.
- Auto-Scaling: The infrastructure automatically expands to handle sudden bursts in transaction volume.
Step 8: Add Fraud Review Workflows
The engine provides the intelligence, but your team needs the tools to take action. We build a custom case management interface that gives your analysts everything they need to review flagged payments.
This layer includes clear visualizations of risk factors and easy “one-click” buttons to approve or decline. Consequently, your human experts become far more efficient and focused on the highest-value threats.
- Intuitive Dashboards: We present complex AI scores in a simple, human-readable format.
- Collaboration Tools: Your team can leave notes and share evidence on suspicious accounts easily.
- Action Routing: The system automatically sends the most urgent cases to your senior investigators.
Step 9: Build Feedback and Retraining Loops
The true power of a self-learning engine lies in its ability to improve over time. We implement automated feedback loops that ingest every chargeback and manual review outcome.
This data is used to retrain the AI models on a regular schedule, ensuring they stay ahead of new tactics. In addition, this creates a system that naturally gets smarter as your business grows and your dataset expands.
- Outcome Collection: We pull data from your banking partners to identify confirmed fraud cases.
- Model Retraining: The AI automatically updates its logic based on the latest successful attacks.
- Shadow Testing: We run new model versions in the background to ensure they outperform the old ones.
Step 10: Monitor Performance in Production
Finally, we set up real-time monitoring to track the health and accuracy of the entire engine. We use observability tools to watch for “model drift,” which happens when fraud patterns shift suddenly.
Therefore, our team can proactively adjust the system before a single cent is lost to a new wave of attacks. This ongoing oversight ensures that your security remains a reliable asset for the long term.
- Drift Alerts: The system notifies us if the incoming data patterns change significantly.
- Accuracy Tracking: We provide weekly reports on saved revenue and false positive rates.
- System Health: Our 24/7 monitoring ensures the fraud API remains responsive and reliable.
Continuous monitoring ensures that your investment in AI remains accurate and delivers a consistent return on your security spend. By building the engine with these steps, your enterprise transitions from reactive defense to proactive, data-driven financial protection.
How Much Does It Cost To Build?
Building a self-learning payment fraud detection engine typically costs between $25,000 and $300,000+, depending on the system’s intelligence layer, transaction volume, model complexity, payment integrations, compliance needs, and fraud operations workflows.
For fintech companies, PSPs, digital banks, and marketplaces, the investment rests in reducing chargebacks, lowering false positives, protecting revenue, and making payment risk decisions in real time.
Cost Breakdown by Fraud Engine Scope
| Fraud Engine Scope | Estimated Timeline | Estimated Cost |
| MVP fraud scoring engine | 10–14 weeks | $25,000–$45,000 |
| AI fraud engine with review workflows | 4–6 months | $45,000–$90,000 |
| Enterprise self-learning fraud platform | 6–10 months | $90,000–$180,000+ |
| Regulated multi-region fraud infrastructure | 9–14 months | $180,000–$300,000+ |
1. MVP Fraud Scoring Engine: $25,000–$45,000
An MVP fraud engine is ideal for fintech startups or payment platforms that need to move beyond static fraud rules but are not ready for a full AI risk infrastructure.
Key components may include:
- Transaction data ingestion from payment systems
- Basic fraud risk scoring logic
- Rule-based approval, decline, or review flows
- Simple fraud dashboard for operations teams
- Initial reporting for failed, blocked, and reviewed payments
This build works well when the goal is to validate the fraud detection workflow before investing in advanced self-learning capabilities.
2. AI Fraud Engine With Review Workflows: $45,000–$90,000
A mid-scale fraud detection engine adds machine learning models, analyst review workflows, and stronger payment risk intelligence.
At this stage, the system not only flags suspicious transactions. It starts learning from historical fraud data, user behavior, device signals, merchant activity, chargebacks, and manual review outcomes.
Key components may include:
- Supervised ML models for known fraud patterns
- Anomaly detection for unusual transaction behavior
- Analyst review queue and case management
- Feedback capture from chargebacks and investigations
- Fraud trend dashboards and risk segmentation
- API integration with payment gateways or processors
This version is suitable for growing fintechs, PSPs, marketplaces, and digital banking products that handle higher transaction volumes and need faster fraud decisions.
3. Enterprise Self-Learning Fraud Platform: $90,000–$180,000+
An enterprise-grade fraud platform requires deeper architecture. It must score transactions in real time, update risk logic based on new outcomes, support multiple fraud models, and give risk teams explainable decision trails.
Key components may include:
- Real-time event streaming architecture
- Feature store for live and historical risk signals
- Multi-model fraud detection layer
- Graph-based fraud ring detection
- Dynamic rules and threshold management
- Model retraining and version control
- Explainable AI reports for fraud teams
- Audit-ready logs for compliance reviews
This build is best suited for enterprises where fraud detection directly affects revenue, customer experience, and regulatory risk.
4. Regulated Multi-Region Fraud Infrastructure: $180,000–$300,000+
Large enterprises often need fraud detection infrastructure that operates across countries, payment rails, entities, and regulatory environments.
This version includes everything from the enterprise build, but with added controls for data residency, regional compliance, governance, model monitoring, and high-availability architecture.
Key components may include:
- Multi-region deployment architecture
- Region-specific data storage and access controls
- Advanced fraud model governance
- Compliance-ready audit trails
- High-availability infrastructure
- Cross-border payment risk scoring
- Custom fraud dashboards for multiple teams
- Integration with KYC, AML, and transaction monitoring systems
This is the right option for digital banks, global PSPs, large marketplaces, payment networks, and enterprise fintech platforms operating at scale.
If your enterprise is handling growing payment volumes, rising chargebacks, or high false positives, Intellivon can help you design a fraud detection engine that fits your current infrastructure and scales with your payment ecosystem.
Conclusion
Building a self-learning fraud engine is a vital move for any growing fintech. It transforms your security from a cost center into a powerful growth driver. By automating risk decisions, you protect revenue and improve customer trust simultaneously.
Advanced technology ensures your platform scales safely while maintaining a frictionless user experience. Therefore, investing in high-grade AI solutions is the logical step toward long-term resilience. Secure your financial future today by building a smarter defense.
Build a Self-Learning Fraud Engine With Intellivon
Building a self-learning payment fraud detection engine requires designing a live fraud decisioning system where payment data, risk signals, rules, analyst feedback, and compliance controls work as one connected infrastructure.
At Intellivon, we build enterprise fraud detection engines where AI is embedded directly into the payment decision layer. This allows fintech platforms, PSPs, digital banks, and marketplaces to score transactions in real time, detect evolving fraud patterns, reduce false positives, and create audit-ready fraud decisions at scale.
A. Designing Real-Time Fraud Decision Systems
Payment fraud happens in seconds, so fraud detection cannot operate after the transaction is complete. We design real-time fraud decision systems that evaluate each transaction during the payment flow without creating unnecessary delays.
- Low-latency risk scoring: We build scoring pipelines that evaluate fraud risk before authorization, payout, or transaction approval.
- Event-driven fraud architecture: Streaming systems process transaction, device, user, and merchant signals as they enter the platform.
- Unified decision engines: AI scores, business rules, velocity checks, and compliance logic converge into one decision layer.
- Approve, block, or review flows: The engine routes transactions based on risk thresholds, fraud patterns, and business priorities.
This ensures fraud decisions happen inside the payment lifecycle, not after chargebacks, losses, or customer friction have already occurred.
B. Building AI Models for Payment Risk
A self-learning fraud engine needs more than one model. We design multi-model fraud detection systems that identify known fraud, detect abnormal behavior, and uncover hidden links between users, merchants, devices, and transactions.
- Supervised fraud models: Models learn from confirmed fraud, chargebacks, disputes, and historical transaction outcomes.
- Anomaly detection models: The system flags unusual payment behavior that does not match normal customer or merchant patterns.
- Graph-based fraud intelligence: Linked entities such as cards, accounts, devices, IPs, and merchants reveal coordinated fraud rings.
- Explainable risk scoring: Each fraud decision includes clear reason codes so risk teams can understand why action was taken.
This gives enterprises stronger fraud accuracy without relying only on rigid rules or black-box AI decisions.
C. Creating Feedback Loops for Continuous Learning
Self-learning fraud detection depends on clean, governed feedback loops. We build systems that learn from real outcomes while keeping model updates controlled, measurable, and auditable.
- Chargeback feedback pipelines: Confirmed chargebacks become training signals for improving future fraud predictions.
- Analyst review outcomes: Manual decisions from fraud teams are captured and reused to refine risk scoring.
- Model drift monitoring: The system tracks when fraud patterns change, and model accuracy starts to decline.
- Version-controlled retraining: New model versions are tested, validated, and deployed without disrupting live payment operations.
This helps your fraud engine adapt to new attack patterns while avoiding unsafe automation or uncontrolled model behavior.
D. Integrating Fraud Engines Into Payment Flows
Fraud detection only creates value when it works inside your actual payment infrastructure. We design integration layers that connect fraud intelligence with gateways, processors, banking systems, wallets, payouts, and review tools.
- Payment authorization integration: Fraud scores are embedded into card, wallet, ACH, and bank transfer workflows.
- Gateway and processor connectivity: The engine connects with payment partners to support real-time transaction decisions.
- Step-up authentication triggers: Medium-risk transactions can move to verification instead of automatic decline.
- Fraud operations workflows: Review queues, alerts, dashboards, and investigation tools help teams act on risk faster.
This allows enterprises to reduce fraud without damaging approval rates, customer experience, or payment performance.
Whether you need an MVP fraud scoring engine, a full AI-powered fraud platform, or a multi-region payment risk system, our team can help you design the architecture, build the models, integrate the workflows, and estimate the development roadmap.
FAQs
Q1. What is a self-learning payment fraud engine?
A1. A self-learning engine is an adaptive system that uses machine learning to identify financial risk. Unlike rigid rules, it evolves by analyzing real-time data and historical outcomes. This process allows the platform to recognize new fraud patterns automatically. Consequently, it provides a dynamic defense that grows stronger with every transaction processed.
Q2. How does AI detect payment fraud in real time?
A2. The system ingests hundreds of data points the moment a payment starts. It compares this data against known legitimate and fraudulent behaviors using complex mathematical models. Therefore, it generates a risk score in milliseconds. This speed allows the engine to block suspicious attempts before the money ever leaves the account.
Q3. What data is needed to train a fraud model?
A3. Effective models require a mix of historical transaction details and confirmed outcomes. This includes user behavior, device fingerprints, and IP addresses. In addition, bank chargeback labels are essential for teaching the AI what fraud looks like. Richer datasets lead to more accurate predictions and a much lower risk for your platform.
Q4. Can a fraud engine reduce false positives?
A4. Yes, a self-learning engine is far more precise than traditional filters. It analyzes the subtle context behind every purchase instead of using broad blocks. This nuanced approach separates true threats from honest customers who might be traveling or shopping late. Therefore, you approve more good orders and increase your total revenue.