Key Takeaways:
-
A production AI medical coding platform requires clinical NLP, ICD-10-CM, CPT, and HCPCS mapping, payer-rule validation, confidence scoring, and human-in-the-loop review.
-
EHR integration through FHIR R4, HL7 CDA, or vendor APIs is a non-negotiable platform.
-
Audit trails and HIPAA controls are architectural requirements that must be designed into the platform from day one.
-
Custom builds cost $120,000–$420,000+, with narrow-scope MVPs starting near $70,000.
-
How Intellivon builds AI medical coding platforms as coding infrastructure, covering AI models, coder workflows, revenue integrity, and post-launch model monitoring
Medical coding is a documentation-intensive process that most health systems are still running manually. Within the manual process, a coder reads through clinical notes and discharge summaries, then translates that clinical language into ICD-10-CM, CPT, and HCPCS codes, one chart at a time. As healthcare documentation compounds and scales with the enterprise growth, this process drastically reduces the ROI and eventually the consumer trust.
The coder shortage is not closing. In fact, AHIMA projects a significant workforce gap through 2029, but at the same time, the documentation burden per encounter is increasing. The manual coding process will not only drain your long-term ROI, but it will also erode the trust of your clients and employees.
An AI medical coding platform changes this operating reality since it reads unstructured clinical text, surfaces ICD-10-CM, CPT, and HCC code recommendations with confidence scoring, and routes exceptions to human review. Their process also works within a compliance architecture that holds up under payer scrutiny.
At Intellivon, we build healthcare AI systems where clinical language understanding and coding logic need to work together in production. This blog draws on our experience and covers what building that platform requires, touching on processes like NLP model selection, EHR integration, HIPAA controls, human-in-the-loop design, and development cost by phase.\

What Is an AI Medical Coding Platform?
An AI medical coding platform reads clinical notes and other medical documents, pulls out diagnoses and procedures, and suggests the correct ICD-10-CM, CPT, and HCPCS codes. It checks those codes against billing rules, flags anything uncertain, and sends it to a human coder to review before submission.
1. AI Coding Platform vs Computer-Assisted Coding Software
Traditional billing systems display simple code suggestions based on text searches, whereas autonomous platforms execute decisions independently. The structural differences below highlight why modern engineering teams choose to build custom AI coding platform development architectures.
AI Coding vs Computer-Assisted Software
| Feature | Computer-Assisted Coding (CAC) | AI Medical Coding Platform |
| Automation Level | The coder must manually review and click every code suggestion. | System processes low-risk encounters autonomously without human input. |
| Core Technology | Basic keyword matching and rigid, regex-based rulesets. | Natural language processing and contextual deep learning models. |
| Integration Method | HL7 CDA static file transfers with batch updates. | Real-time bi-directional FHIR document API endpoints. |
| Error Handling | Flagged manually during internal retrospective audit trails. | Automated confidence scoring routes risky charts to humans. |
Moving from rigid keyword software to a flexible machine learning architecture reduces your long-term maintenance overhead. This technological transition ensures your billing infrastructure adapts dynamically to changing documentation patterns and payer rules.
2. How the Platform Reads Clinical Documentation
An autonomous coding engine ingests diverse medical documentation to extract critical clinical facts. The platform processes raw text using advanced natural language processing to identify diagnoses, procedures, and anatomical locations. This systematic extraction ensures no billable detail is missed during data ingestion.
The system processes several vital clinical documentation streams:
- Physician notes and discharge summaries: Narrative text containing history, physical findings, and final clinical impressions.
- Operative notes: Detailed surgical descriptions are used to isolate specific procedural steps and equipment.
- Lab and imaging reports: Objective diagnostic data that support the medical necessity of assigned billing codes.
- Encounter data: Structured administrative details including patient demographics, visit dates, and provider tracking.
Converting unstructured text into structured data prepares the chart for code assignment. This automated parsing step establishes the foundational data layer required for precise algorithmic analysis.
3. Where AI Coding Fits Inside Revenue Cycle Management
Integrating automation directly into your financial workflow accelerates the path from clinical documentation to final payment. The platform acts as a continuous optimization layer that intercepts data before claims reach the payer. This proactive positioning safeguards your revenue integrity by identifying systemic errors early.
The platform optimizes several critical stages within revenue cycle management:
- Charge capture: Automatically capturing billable services directly from clinical text to prevent lost revenue.
- Clinical documentation improvement (CDI): Flagging incomplete data or ambiguous terms while the patient is still admitted.
- Coding review: Cross-referencing assigned codes against current regulatory guidelines to ensure total accuracy.
- Claim preparation and denial prevention: Validating compliance rules before submission to drastically reduce coding-related denials.
Embedding AI at these touchpoints transforms your billing department into a predictive operation. Consequently, health systems eliminate backlogs and secure stable cash flow across all medical specialties.
Why Healthcare Enterprises Build Custom AI Coding Platforms
Healthcare enterprises build custom AI coding platforms when coding volume, specialty complexity, payer rules, or data-control needs exceed what off-the-shelf tools can handle.
Custom development gives teams control over model behavior, coding workflows, EHR integration, audit design, and denial feedback loops.
1. High Coding Volume Creates Workflow Pressure
Managing thousands of patient encounters daily puts immense operational pressure on health systems and third-party billing teams. High chart volumes frequently lead to human fatigue, causing data entry backlogs and costly clerical mistakes. An automated platform relieves this operational strain by sorting and prioritizing incoming patient charts based on text complexity.
The system analyzes clinical text to optimize your daily processing workflow:
- Routine case automation: Instantly finalizing low-risk charts without requiring human eyes.
- Complex chart routing: Directing multi-specialty encounters straight to your senior coding staff.
- Throughput monitoring: Tracking processing speeds to prevent data bottlenecks in high-volume settings.
This automated triage drastically improves coder productivity and elevates your first-pass coding accuracy rate. By removing simple charts from the manual queue, your staff can focus their energy on validating complicated cases.
2. Specialty-Specific Coding Needs Custom Logic
A generic machine learning model cannot handle the unique terminology variations across different medical domains. For example, a system trained on cardiology data lacks the specific linguistic context needed to process complex orthopedic surgeries. Building a custom application allows you to implement dedicated logic tailored to your specific clinical lines.
Different medical specialties require highly customized language understanding models:
- Radiology and oncology: Extracting precise anatomical locations, tumor sizing, and staging data.
- Cardiology and surgery: Tracking device usage, procedural variations, and concurrent surgical approaches.
- Orthopedics and emergency medicine: Capturing acute injury mechanisms, laterality, and complex external causes.
Deploying specialized models ensures the platform catches the precise nuances of every physician’s note. This specific domain focus prevents overcoding or undercoding errors that trigger immediate audits.
3. Proprietary Payer Rules Create a Built Advantage
Off-the-shelf software packages rarely account for the localized coverage policies and specific contract rules that dictate modern reimbursement. Building custom software gives you the freedom to embed your own historical data directly into the validation logic. This architecture ensures your claims are evaluated against precise payer expectations before submission.
Custom platform logic handles shifting financial and regulatory rules:
- Payer-specific validation: Adjusting code selections based on specific commercial insurance rules.
- Local coverage rules: Linking code generation to geographic Medicare coverage guidelines.
- Denial pattern tracking: Updating internal filters to block codes frequently rejected by specific payers.
Controlling this logic layer protects your revenue integrity far better than a static vendor platform. Your engineering team can update rule engines instantly whenever an insurance company changes its coverage policy.
4. RCM Companies Need Differentiated Product Control
Revenue cycle companies require flexible technology that can mold to the specific requirements of various hospital clients. Off-the-shelf options force you into fixed configurations that limit your operational agility and product positioning. Developing your own system provides total control over user experiences and technical performance dashboards.
Custom platforms provide critical competitive advantages for service companies:
- White-label configurations: Branding the user interface to present a unified product ecosystem.
- Client-specific workflows: Tailoring validation steps to match the exact preferences of individual hospital networks.
- Scalable SaaS delivery: Deploying a multi-tenant cloud architecture that supports rapid customer onboarding.
This complete control over your product design creates a highly differentiated market offering. You can offer custom audit reporting and deep data analytics that standard vendor solutions cannot match.
5. Custom Platforms Improve Data Ownership
Purchasing a generic vendor solution means your proprietary operational data is used to train someone else’s model. In contrast, building a custom platform keeps your training data, feedback loops, and historic patterns completely in-house. This internal data engine becomes a highly valuable corporate asset that appreciates over time.
Retaining full data ownership optimizes your internal development flywheels:
- Model feedback loops: Using real-time human corrections to continuously retrain your internal models.
- Coder decision history: Logging expert corrections to build a unique institutional knowledge database.
- Audit intelligence: Capturing retrospective denial data to make future predictions more accurate.
Securing this data loop establishes permanent product defensibility and long-term asset value. Your models become increasingly accurate as they ingest more of your specific organization’s clinical documentation history.
Why AI Medical Coding Platforms Fail After Deployment
Several AI medical coding platforms fail after the pilot because they recommend codes without creating a traceable path from clinical documentation to the final claim outcome. The real challenge is building a code-to-claim evidence layer that human coders, internal compliance auditors, and commercial insurance payers can naturally trust.
1. Code Prediction Is Not the Same as Coding Readiness
A machine learning model can easily predict a code that appears accurate on a surface level. However, a high model confidence score does not automatically mean a code is completely claim-ready.
The system must still validate complex modifier combinations, verify absolute medical necessity, and evaluate active payer-specific contract logic. Skipping these checks causes immediate clearinghouse rejections despite advanced linguistic processing.
2. Every Code Needs Clinical Evidence Behind It
Automated systems must generate a clear evidence trail by highlighting specific text segments within the electronic health record. The software must parse diagnosis text, isolate procedural descriptions, and perform reliable negation detection to confirm a condition is active.
Furthermore, tracking explicit laterality, clinical severity, and overall documentation completeness prevents inaccurate billing. Providing this visual proof allows human auditors to verify recommendations in seconds.
3. Payer Rules Decide Whether a Code Survives the Claim
Your platform must cross-reference every suggested code against the National Correct Coding Initiative (NCCI) edits before generating a bill.
The system needs to evaluate local coverage determinations (LCD) and national coverage determinations (NCD) to ensure clinical compliance.
Additionally, enforcing precise modifier rules prevents unbundling errors during automated charge capture workflows. Aligning your machine learning outputs with these shifting regulatory frameworks protects your organization from compliance penalties.
4. Coder Overrides Are Product Intelligence, Not Noise
Human corrections represent highly valuable training data that should actively drive continuous model improvement loops. Your engineering architecture must meticulously track accepted, rejected, modified, and escalated codes within the validation dashboard.
Analyzing these patterns allows the software to adjust its internal confidence scoring thresholds dynamically over time. Turning manual overrides into structured feedback loops ensures the platform adapts to real-world edge cases.
5. Denial Feedback Should Train the Platform After Launch
Integrating remittance data directly into the machine learning pipeline allows the system to analyze coding-related denials automatically. The platform must ingest explicit claim rejection reasons and underpayment patterns to pinpoint recurrent systemic errors.
Tracking these outcomes helps developers monitor model drift and optimize the core natural language processing engine. Continuous learning from actual payer responses ensures long-term operational accuracy.
Building a transparent, verifiable data trail prevents post-deployment failure and ensures your automation engine remains accurate over time. This architectural depth transforms raw model predictions into stable, claim-ready financial assets.
AI Medical Coding Platform Architecture
The architecture of an AI medical coding platform must coordinate clinical data ingestion, document normalization, NLP extraction, code recommendation, rule validation, coder review, and billing export. Each engineering layer must create traceable data outputs so technical teams can instantly audit why a code was suggested, modified, approved, or rejected.
The table below breaks down the complete end-to-end software architecture required to process clinical text into validated billing codes.
Architecture and Tech Stack for an AI Medical Coding Platform
| Architecture Layer | Core Functional Processing | Primary Technical Stack |
| Clinical Data Ingestion | Connects to electronic health records to ingest unstructured physician notes, discharge summaries, and operative data. Follows HL7 US Core guidance for real-time EHR document exchange planning. | FHIR DocumentReference API, HL7 CDA, Apache Kafka, AWS MESH |
| Document Normalization | Extracts raw narrative text from image-based formats, isolates distinct note sections, and executes patient-provider identity matching. | Tesseract OCR, OpenCV, Python, PostgreSQL |
| Clinical NLP & Entity Extraction | Runs clinical language understanding models to isolate diagnoses, procedures, anatomical laterality, disease severity, and clinical negation. | Hugging Face Transformers, MedSpacy, ClinicalBERT, PyTorch |
| Code Recommendation | Maps extracted clinical concepts to standardized codes like ICD-10-CM, CPT, HCPCS, and Hierarchical Condition Categories (HCC) based on contextual confidence scoring. | Elasticsearch, custom vector databases, XGBoost |
| Rules & Compliance Validation | Cross-references generated code lists against National Correct Coding Initiative (NCCI) edits and localized insurance rules to prevent billing errors. | Drools Rule Engine, JSON Schema validation, custom Python rule microservices |
| Coder Workflow & Audit | Displays an evidence panel with text highlighting for human review while capturing an immutable audit trail of all manual overrides. | React.js frontend, Node.js backend, GraphQL APIs, AWS CloudTrail |
| Billing & Claims Export | Formats validated transaction sets for clearinghouse routing and listens for real-time denial feedback to retrain underlying machine learning models. | ANSI X12 837/835 processors, secure SFTP, RESTful billing APIs |
Intellivon builds robust billing integration layers that connect your AI platform to legacy financial systems. We focus on secure, reliable data transmissions that keep your accounts receivable pipeline moving. This smooth integration completes the loop from raw clinical documentation to verified cash collection.
Core Features of AI Medical Coding Software Development
An enterprise AI medical coding platform must prioritize features that improve coding accuracy, coder productivity, compliance traceability, and denial prevention. The software platform should not stop at basic code recommendations.
Instead, it must actively support proactive documentation review, real-time rules engine checks, explainable confidence scoring, human coder overrides, immutable audit trails, and financial claim feedback loops.
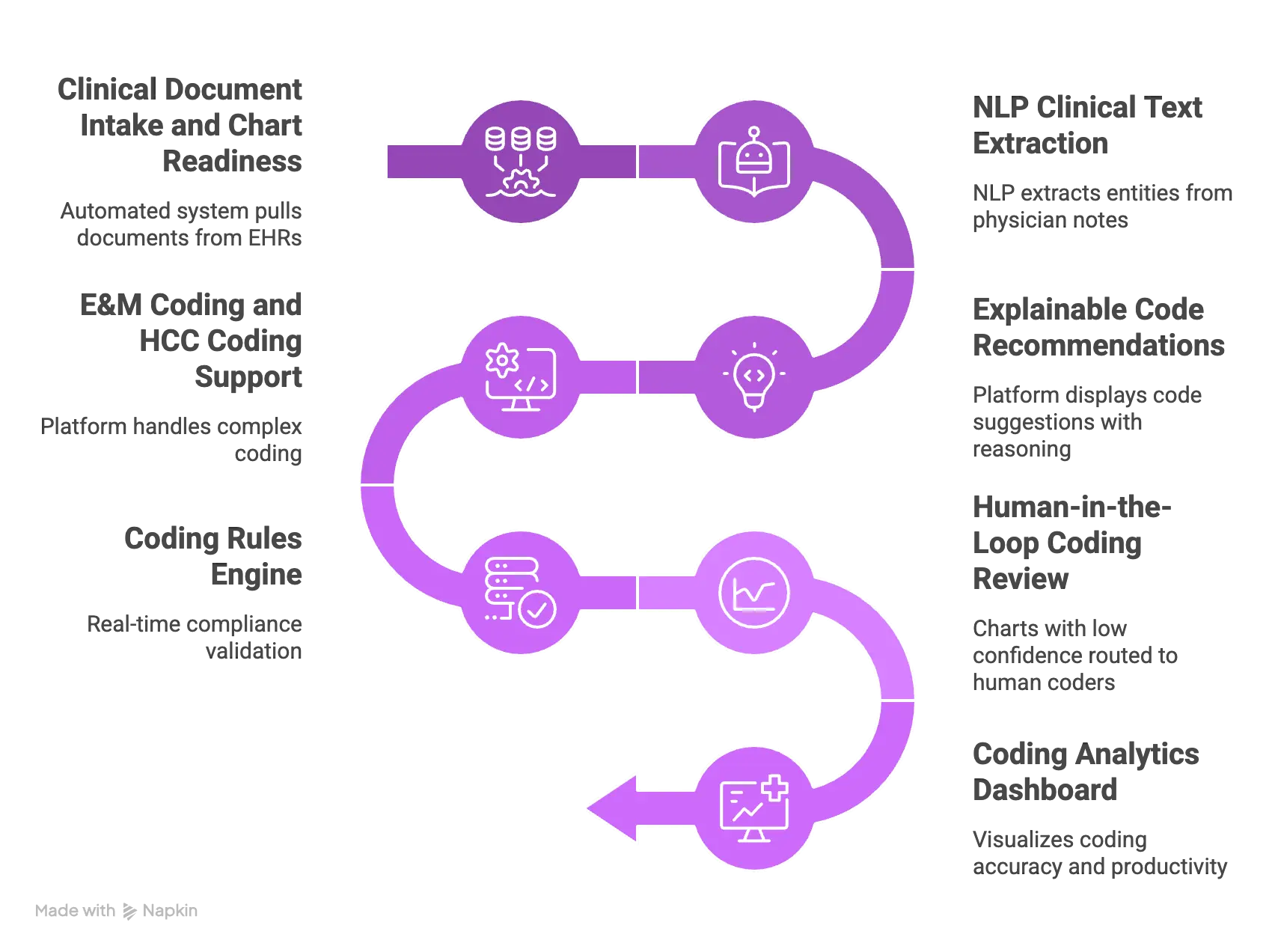
1. Clinical Document Intake and Chart Readiness
An automated system must continuously pull unstructured documents from electronic health records to evaluate chart completeness. The ingestion pipeline tracks encounter status updates and reads the full patient record to confirm if a chart contains enough narrative text for processing.
Identifying these data gaps early prevents your team from attempting to code an incomplete file.
The document intake engine manages specific preparation tasks:
- EHR note synchronization: Automatically fetching narrative records via standard API protocols.
- Encounter validation: Verifying that a clinical visit is officially finalized by the attending physician.
- Omission detection: Scanning records to flag missing documentation before any billing codes are suggested.
2. NLP Clinical Text Extraction
The core processing layer relies on natural language processing to extract meaningful entities from free-text physician notes. The system parses sentences to isolate exact diagnoses, documented procedures, active patient symptoms, and necessary clinical indicators.
Linking this extracted evidence directly to specific code definitions is a mechanical requirement for modern clinical language understanding engines.
The text extraction pipeline manages several critical parsing tasks:
- Entity recognition: Isolating complex clinical terms, pharmaceutical names, and surgical techniques.
- Negation logic: Separating active diseases from documented historical rule-out conditions.
- Context mapping: Connecting anatomical laterality and severity modifiers directly to the primary condition.
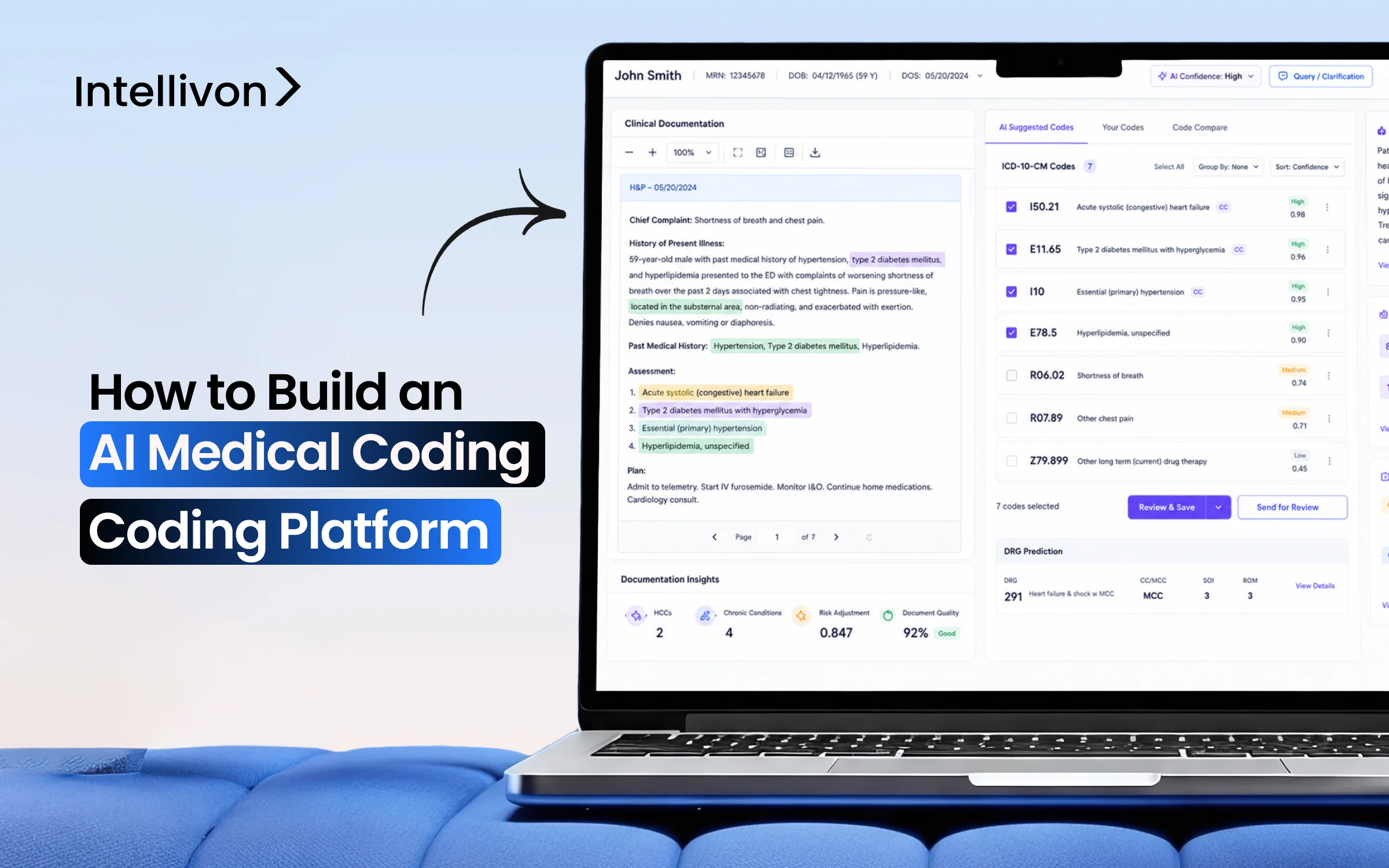
3. Explainable Code Recommendations
Autonomous coding systems must provide completely transparent recommendations rather than operating as an un-auditable black box. The platform displays every suggested code alongside its corresponding text snippet and its exact mathematical confidence score.
Presenting clear reasoning for each suggestion allows human specialists to audit automated decisions in seconds.
The recommendation engine outputs specific data fields for every chart:
- Suggested code set: Assembling complete groupings of valid ICD-10-CM and CPT codes.
- Evidence snippet tracking: Highlighting the exact sentence within the medical record that justifies the code.
- Alternative options: Displaying secondary code variants when clinical documentation permits multiple interpretations.
4. E&M Coding and HCC Coding Support
Managing complex evaluation and management (E&M) leveling and risk adjustment coding requires a highly adaptive software architecture. The platform calculates time-based metrics and evaluates medical decision-making complexity directly from unstructured doctor notes.
Furthermore, tracking chronic diseases across encounters ensures your organization maintains accurate Hierarchical Condition Category (HCC) documentation.
The specialty coding engine executes advanced documentation checks:
- E&M leveling calculations: Analyzing clinical complexity to suggest accurate outpatient and inpatient visit levels automatically.
- Chronic condition recapture: Scanning historical charts to prompt clinical documentation improvement actions for missing risk adjustment codes.
- CDI prompt generation: Delivering real-time alerts to providers when documentation lacks sufficient detail for exact code leveling.
5. Coding Rules Engine
A modern automated platform requires a real-time compliance validation layer to screen code combinations before submission. The system evaluates every suggested billing set against the National Correct Coding Initiative (NCCI) edits and localized insurance rules.
Running these proactive checks eliminates simple compliance errors that lead to automatic clearinghouse rejections.
The validation rules layer executes multiple cross-references simultaneously:
- Bundling validations: Applying strict NCCI edits to prevent unbundling mistakes on surgical claims.
- Coverage mapping: Checking local coverage determinations (LCD) and national coverage determinations (NCD) to ensure clinical validity.
- Payer check updates: Adjusting modifier logic based on the specific commercial insurance policy linked to the patient.
6. Human-in-the-Loop Coding Review
Charts that fall below your target confidence scoring threshold route instantly to a dedicated human validation queue. This workflow interface lets certified medical coders approve, reject, or completely override automated suggestions with minimal effort.
Capturing the precise reason for every human modification is a core requirement for training your platform over time.
The review dashboard facilitates efficient collaboration across department lines:
- Queue routing: Distributing lower-confidence charts to specific specialists based on the medical domain.
- Override logging: Recording the exact reasons why a human professional adjusted a model recommendation.
- Query management: Streamlining the physician query process when clinical documentation requires additional clarification.
7. Coding Analytics Dashboard
To track financial return on investment, your platform must feature a comprehensive business intelligence dashboard. The analytics layer visualizes your total coding accuracy rate, first-pass coding accuracy, and individual coder productivity metrics.
Monitoring these processing statistics allows your operational leaders to identify training gaps and track bottom-line revenue impact.
The reporting engine tracks multiple key performance indicators:
- Automation volume metrics: Measuring the exact percentage of charts processed entirely without human intervention.
- Override rate tracking: Pinpointing specific codes or rules that human specialists frequently modify.
- Denial correlation: Linking post-submission denial data directly back to specific machine learning model versions.
To summarize, core feature development must focus on stabilizing document readiness, structural NLP text extraction, visible explainability parameters, specialized E&M/HCC logic models, automated rule filters, human override interfaces, and aggregated financial analytics.
Incorporating these functional modules guarantees that the completed software addresses every operational checkpoint within a standard healthcare billing cycle.
AI Models Needed for Medical Coding Platform Build
An NLP medical coding platform build needs a hybrid model stack, not one generic Large Language Model. Production systems usually combine clinical NLP, supervised classifiers, semantic retrieval, rule validation engines, confidence scoring modules, and LLM-assisted explanation layers.
This hybrid design keeps recommendations highly accurate while reducing hallucination, compliance, and reimbursement risks.
1. Clinical NLP Models
Extracting underlying medical realities from free-text physician notes requires highly specialized clinical language understanding models. Standard open-source entities are insufficient because they lack the specific medical vocabularies needed to parse complex hospital charting.
The primary model must isolate precise clinical findings, complex pharmaceutical dosing, and intricate procedural notes within long narrative documents.
Technical architectures use domain-adapted models to execute extraction tasks:
- Named entity recognition (NER): Using specialized architectures like ClinicalBERT or MedSpacy to tag distinct anatomical zones, diagnoses, and medical equipment.
- Assertion framework training: Running deep learning assertion classifiers to detect present conditions versus active negations or historical mentions (Source: [ECIR Text2Story Workshop, 2025]).
- Linguistic context mapping: Grouping descriptive symptoms directly with their primary diagnostic entities to preserve sentence structure.
2. Code Mapping Models
Translating structured clinical terms into official billing digits represents a complex, multi-label classification problem. Because the total label space spans over seventy thousand active codes, simple classification networks struggle with accuracy on rare or long-tail medical conditions.
Technical teams solve this scaling bottleneck by combining deep pattern recognition with label-wise attention mechanisms.
The mapping architecture processes historical chart-code pairs using specialized training paradigms:
- Multi-label classification: Implementing deep neural models like PLM-ICD built on RoBERTa to predict multiple code sets simultaneously from a single encounter (Source: [MDPI, 2026]).
- Label-wise attention: Training the network to read the same clinical note differently based on the specific code structure it evaluates.
- Candidate ranking: Applying gradient-boosted trees to score and rank alternative code options before generating final recommendations.
3. LLM Layer for Summaries and Explanations
Large Language Models should operate as supportive quality controllers and text summarizers rather than primary code generators. Allowing an autoregressive model to finalize billing codes directly introduces severe hallucination risks that trigger immediate clearinghouse rejections.
Instead, restrict the generative layer to creating clear, text-based rationales that humans can audit quickly. The generative microservice executes highly controlled text transformation tasks:
- Evidence explanation: Compiling extracted text snippets into a short paragraph that explains the model’s recommendation logic.
- Chart summarization: Condensing long, multi-page discharge summaries into concise operational overviews for human review teams.
- Query draft generation: Writing automated physician query notes when clinical documentation lacks sufficient clarity for precise leveling.
4. Retrieval Layer for Guidelines and Payer Policies
Validating candidate codes requires a dedicated retrieval layer that references official classification books and changing payer rule registries. The system converts raw document text into dense vectors to execute semantic searches across thousands of regulatory pages.
This architecture mimics the exact research steps followed by experienced human coding specialists. The retrieval infrastructure queries distinct external and internal data sources:
- Official index navigation: Searching alphabetical index registries to find precise hierarchical positions within the standard code tree (Source: [Corti Research, 2026]).
- Payer policy mapping: Extracting localized coverage determinations and national coverage determinations to verify active insurance rules.
- Edit rule injection: Pulling active National Correct Coding Initiative (NCCI) manuals to catch unbundling conflicts automatically.
5. Confidence Scoring and Risk Routing Models
To automate workflows safely, the platform requires an algorithmic gating mechanism that separates low-risk charts from complex exceptions. A custom confidence scoring model evaluates extraction certainty, rule matches, and label historical distributions to output a precise decimal rating.
This calculation dictates how an individual encounter moves through your administrative pipeline. The risk router distributes incoming patient charts across distinct work queues:
- High-confidence auto-routing: Finalizing straightforward, low-risk outpatient encounters instantly without human intervention.
- Medium-confidence routing: Transferring ambiguous charts straight to certified human specialists for manual confirmation.
- Low-confidence escalation: Directing highly complex, multi-specialty cases to senior internal compliance auditors for thorough review.
6. Denial Prediction and Feedback Models
The final component in the hybrid stack evaluates completed code packages against historical clearance data to catch potential rejections. By analyzing historical clearinghouse responses, this predictive model identifies hidden patterns that frequently cause insurance companies to block payment.
Incorporating this foresight allows your team to fix formatting mistakes before claims leave your network. The feedback engine manages continuous performance improvement lifecycles:
- Denial risk evaluation: Scoring the probability of a coding-related denial based on historical payer responses.
- Omission risk matching: Flagging potential underpayment threats when the documented clinical context suggests missing code associations.
- Retrospective model tuning: Ingesting 835 remittance files to systematically correct model drift and update active training sets.
Building a production-ready system requires coordinating specialized clinical extraction models, classification classifiers, semantic retrieval layers, and predictive denial networks. Combining these modular AI components prevents costly hallucinations while establishing an explainable, risk-routed processing pipeline that scales safely.
How to Build an AI Medical Coding Platform Step by Step
To build an AI medical coding platform, you must follow a structured sequence spanning scope definition, deep data auditing, secure data pipeline engineering, hybrid machine learning modeling, compliance insertion, and closed-loop optimization.
Executing these phases in precise order ensures your software platform acts as an enterprise-grade financial engine rather than a fragile machine learning demonstration.
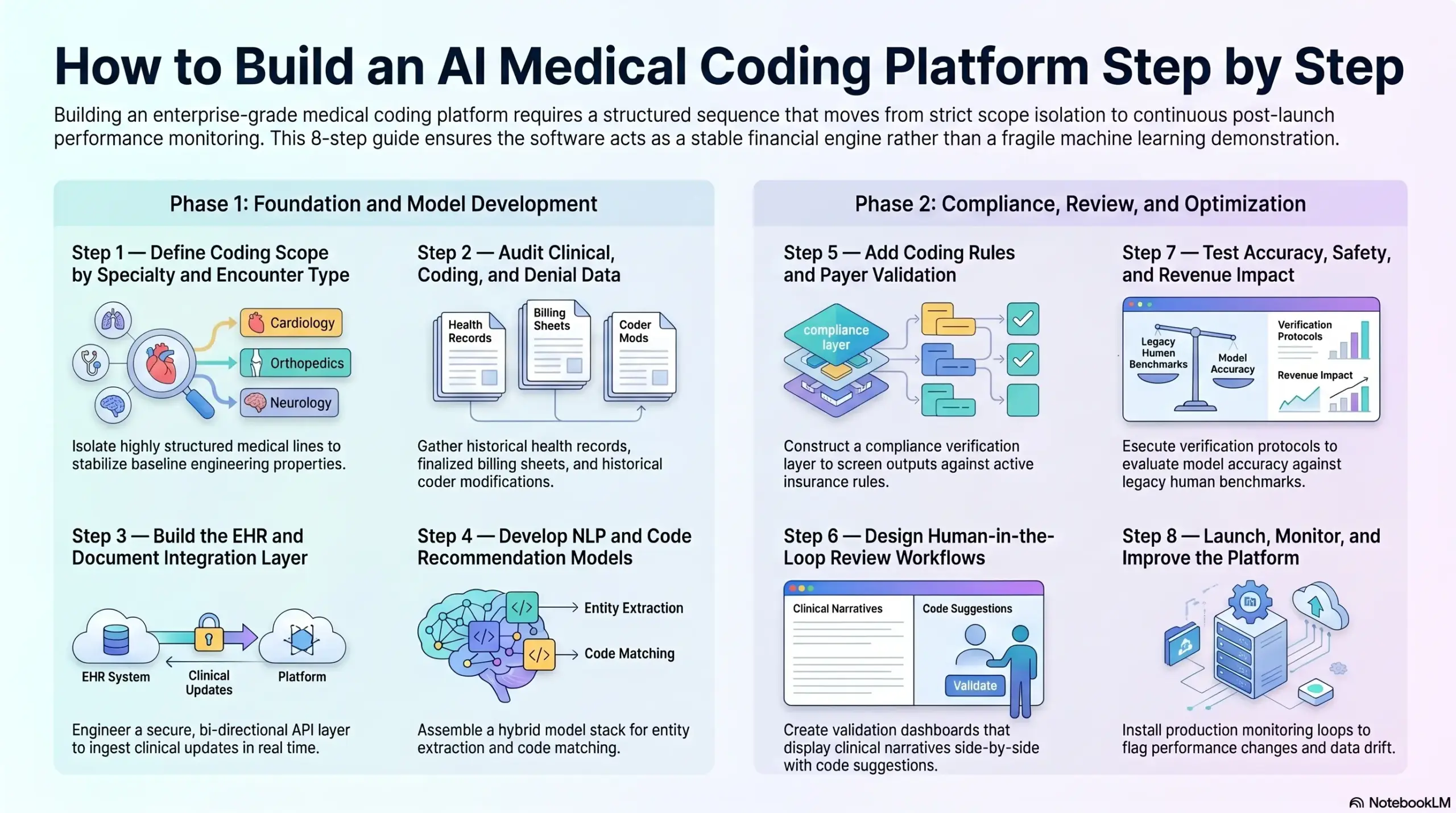
Step 1 — How We Define Coding Scope by Specialty and Encounter Type
Narrowing your initial software scope is necessary to achieve viable model precision during the early development lifecycle. Our team starts the engineering process by isolating highly structured medical lines to stabilize your baseline engineering properties.
Attempting to build an omnibus machine learning model that handles every clinical domain simultaneously results in poor generalization and high error rates.
To construct this baseline, our specialists categorize clinical boundaries across several dimensions:
- Medical domain isolation: We prioritize standardized lines like outpatient radiology, emergency medicine, or ambulatory laboratory services before attempting complex multi-system oncology charts.
- Coding type bifurcation: Our developers explicitly separate professional fee billing from complex facility-side institutional billing within your database schemas.
- Automation mode routing: We programmatically define your minimum viable product (MVP) thresholds for autonomous processing versus assisted human-in-the-loop recommendations.
We advise engineering leaders to begin by targeting outpatient charts where clinical dictation follows predictable, template-driven formatting rules. This strategic constraint allows us to refine the core extraction models without wrestling with dense narrative noise.
Setting clear boundaries during this initial scoping step guarantees your processing pipelines remain stable under production-level data volumes.
Step 2 — How We Audit Clinical, Coding, and Denial Data
Your completed automation platform is only as dependable as the underlying dataset used to train its specialized networks. Gathering a comprehensive repository of historical health records, finalized billing sheets, and historical coder modifications is an absolute functional prerequisite.
This historical evaluation uncovers deep linguistic inconsistencies and documentation errors before our programmers write any model code.
Our data engineering team runs a deep data collection sprint to capture multiple separate information arrays:
- Paired chart repositories: We assemble historical physician notes alongside the final validated ICD-10-CM and CPT code packages approved by your human auditors.
- Modification logging data: We isolate specific files where human billing experts manually altered original software suggestions to discover systemic logic gaps.
- Remittance data matching: We ingest historical insurance clearinghouse rejections to map exact text indicators that historically triggered administrative denials.
Our practitioners execute rigorous data quality assessments to flag truncated records, unreadable text formatting, and contradictory chart-code associations. Cleaning these historical data streams prevents your teams from inadvertently baking legacy human errors directly into your new machine learning training pools.
This deep analytical foundation ensures your recommendation engines learn from verifiable, high-integrity financial outcomes.
Step 3 — How We Build the EHR and Document Integration Layer
A production-grade platform must synchronize seamlessly with external electronic health records to ingest clinical updates in real time. Building fragile file extraction scripts or relying on manual data uploads introduces processing delays that stall your organization’s financial collections.
Instead, we engineer a secure, bi-directional API layer that listens continuously for finalized patient encounters.
The data integration framework we deploy manages multiple communication formats simultaneously:
- Modern API streaming: We utilize the FHIR DocumentReference resource protocol to fetch narrative text files the moment a physician signs off on an encounter.
- Legacy message parsing: We construct dedicated HL7 CDA listeners to handle incoming batch file transfers from older, on-premise hospital servers.
- Identity validation checks: We run real-time algorithmic checks to ensure incoming text strings align perfectly with the correct patient identity registry.
We focus on engineering secure data exchange pipelines that adhere to all federal HL7 US Core transmission guidelines. Our architects implement distributed message streaming to ensure your system handles massive shifts in data volume during peak hospital discharge hours without dropping records.
Establishing this fluid, real-time connectivity ensures your machine learning engines receive fresh data without requiring manual administrative support.
Step 4 — How We Develop NLP and Code Recommendation Models
Once your incoming data streams are completely secure, our machine learning engineers begin assembling your hybrid model stack. This phase requires training a dedicated natural language processing engine to extract medical entities alongside a multi-label classification network to execute code matching.
You must avoid relying on single, generic language model frameworks that lack medical context and introduce severe hallucination risks.
Our core machine learning pipeline handles tasks through separate computing steps:
- Linguistic entity extraction: We train deep neural models to isolate primary diagnoses, surgical procedures, active medications, and clear anatomical laterality.
- Classification code mapping: We deploy label-wise attention networks to evaluate cleaned clinical text arrays against over seventy thousand potential billing targets.
- Explanation block compilation: We use highly controlled generative layers to write clear text rationales that explain why specific codes were selected.
We engineer multi-layered model architectures where every numerical suggestion is mathematically tied to a specific evidence snippet in the patient record. This strict linking design replaces opaque automated logic with complete traceability for internal compliance departments.
Constructing specialized networks ensures the system hits the high precision benchmarks required to operate safely in a live environment.
Step 5 — How We Add Coding Rules and Payer Validation
A code suggestion is mathematically incomplete if it is not validated against active insurance rules and changing federal billing frameworks. This phase involves constructing a dedicated compliance verification layer that screens your model’s outputs before they generate a final bill.
Running these programmatic checks removes simple unbundling mistakes and protects your revenue cycle from automatic rejections.
Our developers build validation microservices that run multi-layered compliance checks on every completed file:
- Bundling edit enforcement: We cross-reference selected CPT targets against National Correct Coding Initiative (NCCI) edit tables to flag unbundling errors.
- Coverage policy matching: We verify proposed items against National Coverage Determinations (NCD) and Local Coverage Determinations (LCD) to guarantee documented medical necessity.
- Payer contract logic: We apply specialized commercial insurance rule packs to ensure claims match localized billing agreements.
Our development methodology decouples the changing rule engine database from your underlying machine learning models. This separation allows your administrative staff to input new insurance rules instantly without forcing a complete model retraining cycle.
Screening code combinations through these programmatic validation matrices maintains your first-pass coding accuracy rate as external regulations shift.
Step 6 — How We Design Human-in-the-Loop Review Workflows
Charts that fall below your predefined confidence thresholds require instant, automated routing to a human validation workspace. The user interface we design presents original physician narratives side-by-side with your software’s code suggestions and visual evidence panels.
This visual alignment allows your certified billing staff to audit complex or ambiguous charts with minimal effort.
Our product designers built the validation dashboard to support multiple expert actions within a unified screen:
- Visual text highlighting: We display the precise text strings within the record that triggered specific code suggestions to accelerate human validation.
- Modification option logs: We force human operators to select an explicit reason from a standard menu whenever they override a software recommendation.
- Communication flow tracking: We integrate automated physician query workflows to clarify ambiguous clinical text directly within the active software environment.
We construct responsive web dashboards that maximize human specialist throughput while reducing cognitive fatigue. Our engineers implement unified communication frameworks that allow clinical documentation improvement specialists to collaborate instantly on complex edge cases.
This accessible interface converts everyday human validation steps into clean, structured data points that continuously help optimize your backend models.
Step 7 — How We Test Accuracy, Safety, and Revenue Impact
Before moving any automated platform into full production, we execute a comprehensive verification protocol using a separate dataset. This testing period evaluates model accuracy and measures how well your validation software performs against legacy human coding benchmarks.
Tracking these operational statistics provides the risk data required to clear internal compliance reviews.
Our quality assurance team monitors multiple performance metrics during this simulation phase:
- First-pass coding accuracy: We measure the absolute correctness of code packages generated without any manual intervention against an external gold standard.
- Human override percentages: We analyze how frequently certified specialists reject or modify specific algorithmic code assignments.
- Processing time variations: We track chart processing acceleration metrics to document operational efficiency improvements across different medical lines.
We establish rigorous testing sandboxes that simulate actual clearinghouse environments to discover potential billing drops prior to launch. Our teams compare automated results directly against historic audit logs to ensure your new software does not trigger overcoding or undercoding risks.
Validating performance against these historical data pools provides your executive team with clear proof of long-term operational value.
Step 8 — How We Launch, Monitor, and Improve the Platform
Moving your software platform into production requires a controlled pilot rollout followed by continuous model tracking. Once live, automated systems face constant model drift as physicians change their clinical dictation styles and payers introduce new authorization definitions.
Your development lifecycle must incorporate automated monitoring tools to flag performance changes the moment they surface.
Our operations team installs a production monitoring loop that coordinates multiple continuous data updates:
- Remittance data ingestion: We automatically parse 835 transaction files to link insurance denials directly back to the active software version.
- Confidence threshold tuning: We adjust your auto-routing gates dynamically based on changing human correction patterns.
- Registry update injection: We deploy updated ICD-10-CM and CPT code registries automatically on an annual basis.
We install continuous telemetry pipelines that track processing performance, system utilization, and data drift concurrently. Our experts help your engineering teams establish reliable automated training loops that use daily human overrides to continuously optimize underlying model layers.
To summarize, building a durable automated billing platform requires executing an eight-step pipeline that moves from strict scope isolation to continuous post-launch performance monitoring.
Safely translating raw clinical text into claim-ready financial assets requires tightly linking advanced natural language processing with modern cloud APIs, decoupling rule microservices, and implementing accessible human-in-the-loop audit dashboards.
EHR, Billing, and Claims Integration Requirements
Autonomous coding platforms must integrate directly with electronic health records, billing systems, practice management software, clearinghouses, and claims environments to influence real revenue outcomes.
Without these production endpoints, an advanced model only acts as an isolated clinical assistant that forces users to execute slow copy-and-paste tasks.
Establishing real-time, bi-directional connectivity allows your software architecture to ingest documentation, calculate codes, export transactions, and capture claim outcomes automatically.
1. EHR Integration for Clinical Notes and Encounter Data
Our engineers deploy secure, real-time integration pipelines that connect directly to major electronic health record networks like Epic, Oracle Health (Cerner), Meditech, and Athenahealth.
We use standard RESTful architectures to track patient visits and pull unstructured doctor documentation the moment an encounter is signed off. This automated ingestion layer replaces slow batch processes with responsive data collection.
To ensure deep cross-vendor compatibility, our development team implements specialized data listeners:
- SMART on FHIR frameworks: We configure secure OAuth 2.0 connection endpoints to search the DocumentReference resource across major hospital installations (Source: [Epic on FHIR, 2026]).
- Dynamic status filtering: Our software monitors explicit metadata parameters to ensure text extraction only runs when a clinical note’s status is officially marked as final.
- Legacy CDA transformation: We build backend conversion scripts to map historical text segments from inbound HL7 clinical document architecture files into uniform JSON structures.
This comprehensive connectivity ensures our extraction models receive fresh data without requiring manual administrative data entry. Isolate the ingestion logic from downstream mapping tasks to prevent performance drops during sudden volume shifts.
2. Billing and Practice Management Integration
Once the natural language processing engine validates code recommendations, our architecture transmits those items directly into your central practice management software. This programmatic syncing step bypasses traditional manual review barriers and speeds up overall charge capture speeds.
The billing export microservice maps multiple structured parameters concurrently:
- Relational data pairing: We bind approved ICD-10-CM codes directly to corresponding CPT and HCPCS codes to establish medical necessity.
- Administrative metadata injection: Our pipelines automatically attach active provider identifiers, national provider numbers, localized fee schedules, and specific place of service numbers.
- Charge router automation: We route completed encounter transactions straight into the organization’s central billing queue for instantaneous financial posting.
Synchronizing these codes directly with your practice management software prevents code drops and eliminates days from your accounts receivable ledger.
3. Clearinghouse and Claims System Integration
Securing your cash flow requires connecting your platform directly to major external clearinghouse networks like Availity or Change Healthcare. Our development team builds automated outbound claim scrubbers that evaluate transaction sets against active payer rules before files leave your internal infrastructure.
This preventative step guarantees your digital claims are structured perfectly prior to final transmission. The claims integration pipeline processes transactions through separate functional steps:
- EDI transaction generation: We convert approved internal billing codes into standardized ANSI X12 837 transaction files automatically (Source: [X12 Standard, 2025]).
- Pre-bill edit scrubbing: Our rules engine evaluates outbound files against national bundling edits to eliminate basic compliance errors before submission.
- Bi-directional feedback mapping: We construct automated parsers that ingest inbound 835 Electronic Remittance Advice files to match insurance payments and denial records to original codes.
We focus on engineering tight clearinghouse connections to build a closed-loop revenue cycle environment. Ingesting actual payer responses helps our developers monitor ongoing model drift and correct hidden processing mistakes.
4. Data Warehouse and Analytics Integration
To provide executive teams with deep business visibility, our architecture pushes processing statistics into centralized corporate data warehouses. This integration layer feeds real-time performance data into analytical tools to measure long-term financial return on investment.
Organizing these data matrices helps compliance leaders monitor accuracy variations across different clinical departments. Our data team configures analytics pipelines to track multiple key metrics:
- Automation volume statistics: We calculate first-pass coding accuracy rates alongside total chart throughput volumes across distinct specialties.
- Human override audits: Our tracking models monitor how frequently human specialists change individual algorithmic code assignments.
- Financial trend calculations: We match automated coding changes directly to shifts in denial rates and overall accounts receivable durations.
This isolated design ensures your executive dashboards display deep operational trends without slowing down your primary production workflows.
5. Identity, Access, and Role Mapping
Operating safely within a hospital environment requires enforcing strict role-based access controls to safeguard sensitive patient information.
Our developers integrate your automated platform with enterprise identity systems using standard protocols like SAML 2.0 and OpenID Connect. This framework guarantees that only authorized staff can view protected health information or alter model outputs.
- Patient record matching: We apply advanced deterministic algorithms to verify that incoming clinical text pairs perfectly match the correct patient master index.
- Granular role definitions: Our configuration isolates accessible features based on user types, separating human coders, internal compliance auditors, and system administrators.
- Audit log generation: We log every user login, chart view, code override, and system export into an unalterable database file to satisfy federal compliance inspectors.
Our specialists engineer strict security architectures that honor all federal data protection guidelines while maintaining efficient operational speeds. This security-first design limits compliance exposure and keeps your administrative workflows completely auditable.
Integrating these separate administrative layers transforms your core machine learning algorithms into a protected, automated financial pipeline that safely speeds up hospital cash collection.
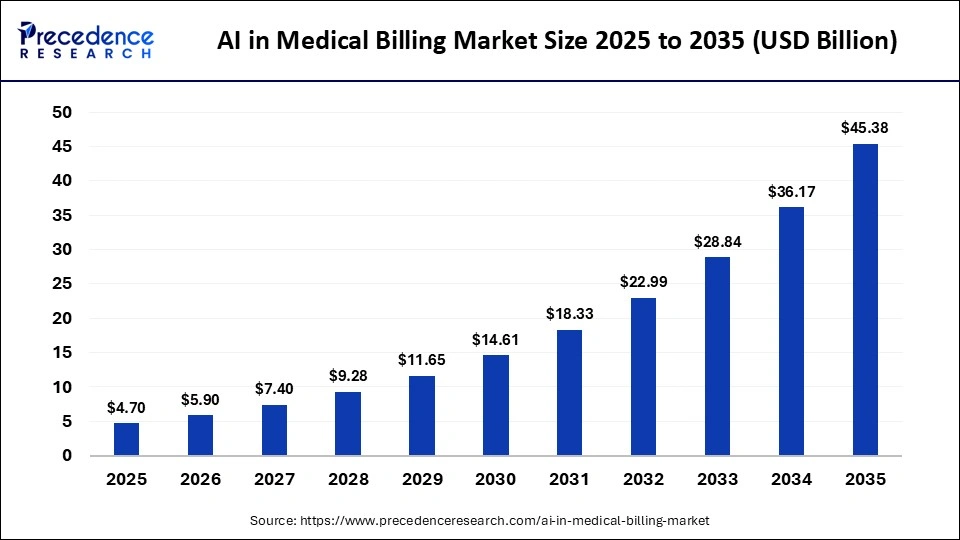
AI Medical Coding Platform Development Cost
AI medical coding platform development cost usually ranges from $120,000 to $420,000+ for a production-ready custom build. A focused MVP can start around $70,000 to $140,000 when it supports one specialty, one EHR integration, and assisted coding instead of autonomous coding.
The final cost depends on how deeply the platform connects with clinical documentation, coding rules, payer logic, coder workflows, and compliance controls. A simple AI coding assistant costs less because it only recommends code.
However, a production-grade platform needs NLP models, ICD-10-CM, CPT, and HCPCS mapping, EHR integration, audit trails, HIPAA safeguards, and post-launch monitoring.
1. MVP Cost Range
An MVP AI medical coding platform usually costs $70,000 to $140,000.
This version works best when you want to validate the platform with one specialty, one EHR integration, and assisted coding workflows before expanding into more complex automation.
2. Mid-Level Platform Cost Range
A mid-level AI medical coding platform usually costs $140,000 to $260,000.
This version is suitable for teams that need stronger NLP, multiple specialties, better coder dashboards, and rule-based validation across coding workflows.
3. Enterprise Platform Cost Range
An enterprise AI medical coding platform usually costs $260,000 to $420,000+.
This scope is designed for hospital networks, health systems, large RCM companies, and healthcare SaaS platforms that need multi-specialty support, multi-EHR integration, advanced compliance controls, and scalable SaaS architecture.
4. Development Phase Cost Breakdown
The cost to build an AI medical coding platform is usually spread across discovery, data preparation, architecture, AI development, integrations, compliance, testing, and deployment.
| Development Phase | Estimated Cost | What It Covers |
| Discovery and workflow mapping | $10,000–$25,000 | Coding scope, specialty selection, workflow review, MVP planning, ROI assumptions |
| Data audit and annotation planning | $15,000–$45,000 | Chart-code pairing, coder edits, denial data, PHI review, labeling rules |
| UX/UI design | $12,000–$35,000 | Coder dashboards, evidence panels, work queues, override flows, audit screens |
| Backend architecture | $30,000–$80,000 | User roles, workflow engine, APIs, rules service, secure data storage |
| EHR and billing integrations | $35,000–$110,000 | FHIR, HL7 CDA, vendor APIs, billing export, encounter matching |
| AI model development | $35,000–$120,000 | NLP extraction, code mapping, confidence scoring, LLM explanations |
| HIPAA and audit controls | $18,000–$60,000 | RBAC, encryption, audit logs, PHI safeguards, access monitoring |
| QA, validation, and pilot | $20,000–$55,000 | Model testing, coder UAT, integration QA, security checks, pilot rollout |
The largest cost drivers are usually EHR integration, AI model complexity, coding-rule validation, and data readiness.
Ongoing Maintenance Cost
Ongoing maintenance usually costs 18% to 25% of the initial build cost per year. So, if the platform costs $240,000 to build, annual maintenance may range from $43,000 to $60,000.
This budget covers coding-rule updates, model monitoring, bug fixes, security patches, EHR API changes, infrastructure maintenance, and feature improvements. It should also include updates for ICD-10-CM, CPT, HCPCS, payer rules, NCCI edits, LCD policies, NCD policies, and medical necessity logic.
Planning an AI medical coding platform budget? Intellivon can estimate development cost based on your coding scope, specialty mix, EHR integration needs, NLP model depth, rule validation requirements, HIPAA controls, audit workflows, and rollout timeline.
Intellivon helps healthcare teams map the platform scope before development, so cost planning stays tied to real coding operations.
Conclusion
An AI medical coding platform must be designed as a secure, end-to-end infrastructure rather than a simple text-prediction tool. The most successful systems bridge the code-to-claim evidence gap by tightly linking clinical document integration, structured NLP extraction, localized payer rules, and human-in-the-loop audit trails.
A custom platform build requires a strategic development path covering scope definition, model engineering, and real-time EHR integration. While engineering an enterprise-grade solution involves a capital allocation between $250,000 and $650,000, building your own architecture provides long-term control over proprietary training data, reduces coding-related denials, and ensures total revenue cycle integrity.
Build an AI Medical Coding Platform With Intellivon
At Intellivon, we help hospitals, RCM companies, and healthcare SaaS teams plan and build custom AI coding platforms around real coding operations. The goal is not to replace coding teams blindly. The goal is to help healthcare organizations scale coding capacity with control.
A. Define the Right Coding Automation Scope
Intellivon maps MVP scope, specialty selection, CAC vs autonomous coding decisions, workflow priorities, and ROI assumptions before development starts.
B. Design the Platform Architecture Around Coding Operations
Intellivon designs EHR document flow, coding queues, rules engines, evidence-linked recommendations, billing handoffs, and audit history.
C. Build AI Models Coders Can Trust
Intellivon builds clinical NLP, code mapping, LLM support, confidence scoring, evidence extraction, and specialty-level model testing.
D. Integrate With Healthcare Systems
Intellivon connects EHRs, billing systems, practice management tools, clearinghouses, claims platforms, and data warehouses.
E. Make Coding AI Secure and Monitorable
Intellivon builds HIPAA-ready architecture, PHI controls, role-based access, audit logs, denial feedback loops, and model drift monitoring.
Things To Know About AI Medical Coding Platforms
Q1. Can We Build An Autonomous Medical Coding System Without Replacing Coders Completely?
A1. Yes, autonomous coding can handle narrow, high-volume, low-risk cases, but coders should still review complex charts. The safest model uses confidence scoring, documentation checks, payer-rule validation, and audit thresholds. Coders then focus on exceptions, CDI issues, audits, and high-value claims.
Q2. What Should An AI Medical Coding Platform Actually Help Coders Do?
A2. An AI medical coding platform should help coders find clinical evidence, identify ICD-10-CM, CPT, and HCPCS codes, flag missing documentation, and review charts faster. It should show confidence scores, rule checks, and code rationale so coders can make faster decisions without losing control.
Q3. How Much Does An AI Medical Coding Platform Cost?
A3. An AI medical coding platform usually costs $120,000–$420,000+ for a production-ready custom build. A focused MVP can start around $70,000–$140,000 with one specialty, one EHR integration, and assisted coding. Costs rise with autonomous coding, payer rules, HIPAA controls, and multi-specialty support.
Q4. Should We Build Vs Buy AI Medical Coding Software?
A4. Buy AI coding software when workflows are standard, timelines are short, and vendor features are enough. Build when you need proprietary payer rules, specialty-specific coding, model ownership, deep EHR integration, or SaaS differentiation. A hybrid model works when you extend CAC tools with custom intelligence.