Key Takeaways:
-
AI claims scrubbing validates EDI 837 claims, NCCI rules, payer edits, and authorization before submission.
-
Deterministic rules engines, NLP extraction, and predictive denial scoring must work together in production.
-
Custom builds cost $85,000 to $290,000 within 5 to 15 months, depending on enterprise scale.
-
HIPAA controls, audit logs, confidence scoring, and MLOps monitoring are non-negotiable production requirements.
-
How Intellivon builds AI claims scrubbing platforms as revenue-cycle infrastructure from the ground up.
Claims scrubbing software validates every outgoing claim against coding rules, payer-specific requirements, and clinical documentation standards before submission. It checks ICD-10-CM and CPT combinations, runs NCCI edits, verifies modifiers, and flags missing authorizations before submission. That pre-submission window is where most preventable denials originate, and where rule-based scrubbers consistently fall short.
According to the Deloitte Center for Health Solutions, predictive claim validation can prevent up to 85% of avoidable denials. However, rule-based scrubbers rarely come close to that figure. Instead, they handle NCCI edits reliably but cannot adapt to mid-year payer rule changes or validate medical necessity from clinical documentation.
AI claims scrubbing software closes both gaps. It combines a dynamically updated payer rules engine with NLP validation across clinical documentation, assigning a confidence score that routes each claim to automated submission or flags it for human review.
At Intellivon, we build AI claims scrubbing systems where payer rules, NLP model design, and compliance architecture are decided together. This blog covers what building that software requires, which includes payer rules engine design, NLP model selection, EHR and clearinghouse integration, HIPAA controls, and development cost by phase.

What Is AI Claims Scrubbing Software in Healthcare?
AI claims scrubbing software is a digital safety net that reviews medical bills for mistakes before they go to insurance companies. Traditional tools only look for obvious typos like missing names or wrong ID numbers. This intelligent system reads doctor notes, catches complicated coding errors, and predicts if an insurance company will reject the bill.
Think of this software as an automated spell-checker for medical bills. Old systems only catch basic typos like a missing signature or an invalid ZIP code. This new system reads the actual doctor notes to make sure the treatment matches the diagnosis. It catches hidden mistakes before you submit the bill, which keeps insurance companies from rejecting your claims.
1. Claim Scrubber vs Claims Editing Software vs Denial Prediction
Many billing platforms group these three tools together, but they perform entirely different roles in your revenue cycle.
- Claim Scrubber: A standard tool that checks files for formatting rules and basic missing text before the bill leaves your system.
- Claims Editing Software: A more advanced system that looks closely at medical rules, combining specific treatment codes to prevent billing errors.
- Denial Prediction: An intelligent AI model that reads clinical data to forecast whether an insurance payer will reject a bill.
| Feature | Claim Scrubber | Claims Editing Software | Denial Prediction |
| Primary Focus | Syntax and formatting | Coding compliance | Financial risk scoring |
| Technology | Static rule checklists | Code bundling logic | Machine learning models |
| Data Source | EDI fields | CPT and ICD-10 codes | Full clinical medical notes |
Traditional scrubbers only check your formatting, while advanced editing systems fix coding mistakes, and prediction models stop denials before they happen.
2. Pre-Submission Claim Validation
This process acts as a financial checkpoint that reviews every medical bill for accuracy before submission.
- It catches costly mistakes by comparing diagnoses against the specific procedures performed by doctors.
- It automatically stops bills that contain duplicate charges or violate local insurance rules.
- By catching errors early, it protects your revenue integrity from costly administrative delays.
3. EDI 837 Validation
This technical check ensures your medical bills match the strict electronic formats required by insurance networks.
- The system scans the official ANSI X12 837 transaction file, which is the federal standard used to transfer healthcare claims to payers (Source: [X12, 2026]).
- It verifies that necessary elements like provider tax numbers and patient ZIP codes reside in the correct digital loops.
- Failing this step causes immediate file rejection by your clearinghouse before an insurance company ever reviews it.
4. Claim Rejection vs Denial
Understanding the difference between a rejection and a denial changes how your team manages billing issues.
- Claim Rejection: A formatting or data error found during the EDI 837 check that prevents the payer from processing the bill.
- Claim Denial: A decision made by the insurance company after processing that states they will not pay for the medical service.
- Rejections require quick data fixes, whereas denials require a complex and expensive clinical appeals process.
5. Clean Claim Rate and First-Pass Acceptance Rate
These two metrics tell you exactly how well your pre-submission billing workflow is performing.
- Clean Claim Rate: The percentage of medical bills sent out that contain zero errors on their very first submission.
- First-Pass Acceptance Rate: The percentage of bills that payers successfully accept into their systems without any immediate automated pushback.
- Improving these numbers directly accelerates your cash flow and reduces manual rework for your billing team.
6. Where It Sits in the RCM Workflow
An intelligent validation platform integrates directly between your electronic health records and your clearinghouse.
- It automatically ingests clinical data right after a doctor completes their medical documentation.
- It applies real-time fixes before generating the final electronic billing file.
- This placement creates a secure control layer that protects your cash flow without slowing down daily operations.
Once the definition is clear, the next section should show why legacy claim scrubbers are no longer enough for payer-specific revenue operations.
Why Legacy Claim Scrubbers Fail as Payer Rules Change
Legacy claim scrubbers fail when their static rules cannot keep up with changing insurance requirements and complex medical regulations. The issue is that rules decay unless the platform can ingest, version, test, and deploy updates continuously.
Traditional software relies on manual updates that take too long to program. This delay allows outdated rules to remain active, causing high denial rates for your newest procedures.
1. Payer Rule Decay and the Update Architecture
Insurance companies alter their billing guidelines constantly, which causes software rules to break over time.
- Medicare updates its official National Correct Coding Initiative (NCCI) and Medically Unlikely Edits (MUE) files every quarter.
- Old software requires programmers to manually type these quarterly additions, deletions, and revisions into the system.
- A modern rule orchestration platform automates this by pulling data directly from federal registries and deploying updates through an automated pipeline.
2. Static Rules vs Dynamic Rule Orchestration
Traditional billing tools use rigid checklists that check every insurance claim the exact same way.
- Static Rules: Hardcoded logic that treats a local insurance plan the same as a major federal program, missing key nuances.
- Dynamic Orchestration: Smart software that selects specific validation checks based on the payer, state, and provider contract.
- This dynamic approach ensures your bills face the exact criteria the insurance company will use to evaluate them.
3. Managing NCCI and Medically Unlikely Edits
Preventing basic coding mistakes requires automated compliance checks for federal volume limits.
- The system cross-references national bundles to ensure clinicians do not bill for overlapping services on the same day.
- It monitors maximum units per line item to catch units that exceed normal daily limits before submission.
- This automated verification protects your practice from audits and immediate automated rejections.
4. LCD and NCD Compliance for Medical Necessity
Proving that a treatment was medically necessary requires perfect alignment with local and national policies.
- National Coverage Determinations (NCD): General rules that outline when federal insurance will cover a specific procedure.
- Local Coverage Determinations (LCD): Specialized rules that vary by region and determine coverage based on local policies.
- The software scans these policies in real time to verify that your patient’s recorded symptoms justify the ordered treatment.
5. Diagnosis-Procedure Mismatches and Code Bundling
Insurance companies deny claims instantly when the documented medical codes do not match or are separated incorrectly.
- Diagnosis-Procedure Mismatch: A critical error where the recorded illness does not match the treatment provided.
- Unbundling Edits: An illegal practice where automated systems break a single comprehensive procedure code into multiple expensive parts.
- The software catches these code mismatches and bundling errors instantly, keeping your billing practices clean and compliant.
6. Modifier Validation and Specialty Logic
Specialized medical fields need customized billing rules to handle complex procedure modifiers correctly.
- The platform verifies specific medical modifiers to explain unique circumstances, like performing surgery on both sides of the body.
- It applies custom scrubbing logic tailored to your specific medical specialty, whether you run orthopedics or cardiology.
- This automated verification ensures your claims match the unique billing realities of your practice areas.
The fix is not replacing rules with AI. The fix is designing the right boundary between deterministic rules and AI models. This balanced architecture allows you to maintain rigid regulatory logic while letting machine learning handle messy clinical data.
How AI Claims Scrubbing Software Works Before Submission
AI claims scrubbing software works by ingesting claim, clinical, eligibility, authorization, and payer-rule data, then running every claim through validation layers before submission.
The platform checks structural completeness, coding relationships, medical necessity, payer contract logic, denial probability, and correction workflows before routing clean claims to the clearinghouse. Specifically, this real-time process turns a static checklist into an active revenue integrity control layer.
Consequently, your system stops treating claims as passive data files. Instead, it treats them as complex financial transactions that require deep clinical verification.
1. Comprehensive Data Ingestion from Healthcare Systems
An AI scrubbing system must gather disparate information from multiple software environments simultaneously.
- The platform utilizes native APIs and HL7/FHIR protocols to ingest raw files from your Electronic Health Record (EHR) and Practice Management (PM) tools.
- It extracts historical data streams from billing platforms and past clearinghouse response loops to build a complete record of the patient encounter.
- This automated data collection eliminates manual entry errors because it pulls directly from the original source documentation.
2. Multi-Layered Clinical Code Validation
Once the system ingests the data, it evaluates the technical relationships between different medical code sets.
- ICD-10-CM Validation: The platform checks the recorded patient diagnosis codes to ensure they are highly specific and active for the current fiscal period.
- CPT and HCPCS Validation: The software scans procedure and outpatient service codes to prevent diagnosis-procedure mismatches before submission.
- Evaluation and Management (E&M): It analyzes billing levels to catch undercoding detection gaps that lose revenue or overcoding detection spikes that trigger audits.
3. Advanced Billing Logic and Rules Processing
The platform next applies contract compliance logic to protect your revenue integrity across diverse insurance networks.
- It runs automated modifier validation to confirm that special circumstances, like bilateral surgeries, have the exact billing additions required.
- The system performs duplicate claim detection by scanning historical databases to find matching dates of service and procedure codes.
- It verifies coordination of benefits rules and timely filing validation windows to ensure the claim routes to the correct payer before deadlines pass.
4. Prior Authorization and Charge Capture Validation
The system also verifies that administrative permissions match the technical billing lines exactly.
- It automatically checks for a prior authorization mismatch by cross-referencing approved insurance tokens against the submitted CPT codes.
- The software conducts real-time charge capture validation to ensure that all documented clinical procedures actually appear on the final financial itemization.
- For example, real-time AI scrubbing platforms look for missing clinical evidence to map eligibility and coverage requirements perfectly before the claim leaves your office.
5. The Sequential System Flow
The entire pre-submission validation pipeline occurs through an automated series of interconnected technical milestones.
- Encounter Locked: The clinician finishes their documentation and locks the encounter file inside the primary EHR environment.
- Data Transmission: Charges and codes pass directly to the central billing system, where a claim draft automatically enters the scrubber.
- Rules Engine Check: A deterministic rules engine validates strict formatting, billing logic, and initial EDI 837 structural loops.
- NLP and ML Analysis: Natural Language Processing reads the documentation evidence, while a machine learning model scores the overall denial risk.
- Exception Routing: Clean claims route directly to the clearinghouse, whereas claims with errors route to human review queues for fast exception handling.
- Feedback Integration: The clearinghouse transmits 277 and 835 transaction files back into the system to continually update the predictive analytics models.
This workflow only works when the architecture separates rules, AI, integrations, and review queues cleanly. Consequently, engineering teams must understand the exact software components required to handle these massive clinical data streams.
How AI Claims Scrubbing Software Learns After Every Denial
AI claims scrubbing software becomes more valuable when it learns from payer responses after submission, not only from rules before submission.
A payer rule intelligence layer uses 835 remittance data, Claim Adjustment Reason Codes (CARC), Remittance Advice Remark Codes (RARC), clearinghouse rejections, denial trends, manual corrections, and reviewer overrides to update claim edits, payer profiles, and risk scoring over time. Therefore, your validation loop stays sharp as insurance networks change their underlying evaluation logic.
Consequently, the platform converts past financial losses into preventative digital walls. This closed-loop design ensures that a specific denial reason only catches your billing team off guard exactly once.
1. Why Static Claim Scrubbing Rules Lose Accuracy After Launch
A scrubber that launches with strict rules can still become outdated within months if no one builds a rule refresh process.
- Software rule decay occurs naturally because major federal networks like Medicare modify their official NCCI and MUE files every single quarter.
- Commercial insurance contracts shift unexpectedly, and local coverage policies adjust clinical documentation rules without warning.
- Furthermore, clearinghouses alter their internal text edits much faster than healthcare networks can update their native billing software.
- If your platform uses frozen logic, your clean claim rate will decline within ninety days of deployment.
2. How 835, CARC, and RARC Data Feed the Learning Loop
The system reads standard electronic payment files to uncover the hidden reasons behind payer rejections.
- The ingestion engine scans the official X12 837 claim transaction reference for submission, but it relies on the incoming X12 835 transaction to build a behavioral memory.
- Specifically, the X12 835 transaction provides payment and adjudication information while detailing exactly why a claim was adjusted or denied.
- The platform extracts standardized CARC and RARC tokens to classify payment adjustments and cluster specific denial patterns by individual insurance companies.
- This automated data tracking helps CTOs see how payers alter their processing rules in real time.
3. How to Convert Denial Patterns Into New Claim Edits
When the machine learning models identify an emerging denial pattern, the platform builds an automated path to correct it.
- For example, if a specific payer repeatedly denies a CPT and modifier combination for an orthopedic service, the platform notices the financial anomaly immediately.
- Rather than simply reporting the issue on a dashboard, the system generates a candidate edit rule automatically.
- It simulates this candidate rule against thousands of your historical claims to check for false positives before deployment.
- Finally, it routes the tested rule to billing leaders through a human-in-the-loop review queue for one-click activation.
4. Which Rule Updates Should Be Automated and Which Need Human Approval
An enterprise-grade system must separate simple formatting fixes from complex clinical policy adjustments.
- Simple structure corrections can skip human eyes entirely, but changes to medical necessity validation always require expert oversight.
- This distinction prevents automated updates from accidentally overriding sensitive provider contract specifications.
The following structural framework shows how the platform manages different edit updates securely:
| Rule Type | Update Method | Governance Focus |
| Formatting errors | Auto-update | Direct database injection |
| Missing required fields | Auto-update | Instant loop verification |
| Payer-specific modifier patterns | Human-approved | Billing manager sign-off |
| Medical necessity edits | Human-approved | Clinical documentation review |
| LCD and NCD policy logic | Compliance-reviewed | Regulatory legal validation |
| High-dollar denial prevention rules | Senior reviewer approval | Executive executive override |
5. How the Platform Builds Payer-Specific Denial Memory
By saving every historical transaction outcome, the software builds a deep, plan-level knowledge base.
- The system creates specialized provider profiles that isolate regional payer differences and custom contract rules.
- It maps how individual insurance offices interpret specific modifier codes for different clinical specialties.
- This granular data layer tracks which code combinations yield the highest first-pass acceptance rates for every unique plan.
- Therefore, you are not just building a basic error checker, but you are building a proprietary payer intelligence asset.
This feedback architecture transforms your software from a reactive tool into a predictive revenue shield.
6. KPIs That Prove the Payer Intelligence Layer Is Working
Enterprise technology leaders must monitor specific operational metrics to ensure their machine learning models actually improve billing outcomes over time.
- The system tracks how effectively past payment data stops duplicate errors from recurring on new submissions.
- It measures how often your technical teams accept the platform’s automated rule suggestions without manual edits.
- Monitoring these indicators helps you confirm that your intelligent automation reduces administrative burdens rather than creating extra work.
| KPI | What It Measures | Target Baseline |
| Repeat denial reduction | Whether the system learns from past payer responses | Greater than 40% reduction |
| Rule candidate accuracy | Whether AI-suggested edits are useful | 95% acceptance rate |
| Override rate | Whether billing teams trust the rules | Less than 5% of claims |
| False-positive rate | Whether the scrubber blocks too many valid claims | Less than 1% of the total batch |
| Payer-specific denial drop | Whether payer intelligence improves over time | Month-over-month decline |
| Manual rule maintenance hours | Whether automation reduces admin burden | 80% time savings |
Tracking these core metrics ensures your development team can justify the upfront engineering costs. Consequently, the next logical step is evaluating the complete architectural design required to sustain these performance gains.
AI Claims Scrubbing Software Architecture for RCM
Enterprise AI claims scrubbing software architecture should include an ingestion layer, claim normalization service, deterministic rules engine, AI validation layer, payer-rule repository, workflow queue, audit layer, analytics module, and integration layer.
This structure prevents the platform from becoming a hardcoded edit tool that breaks whenever payer policies change. Specifically, designing a modular framework keeps your core validation services isolated from messy data streams.
Consequently, technology teams can deploy fast microservices that scale independently. This structural independence prevents massive system slowdowns when processing large batches of billing files.
The following technical framework outlines the exact architectural layers and technologies required to run this real-time system:
| Architectural Layer | System Responsibilities and Actions | Production Tech Stack |
| Data Ingestion & Exchange | Ingests raw clinical data and orchestrates modern interoperability pathways. Maps older data streams while managing newer secure records. | HL7 v2 Engine, FHIR R4 API, HAPI FHIR Server, Apache Kafka |
| Format Validation | Parses outbound billing data to check compliance. Verifies structural correctness before the file reaches the clearinghouse network. | ANSI X12 837 Parser, Python, Go, AWS Lambda |
| Deterministic Rules Engine | Evaluates rigid regulatory compliance rules. Checks federal maximum units and flags code combinations across specialty profiles. | Drools Rules Engine, Redis Cache, PostgreSQL |
| AI Validation & NLP | Extracts clinical entities from raw text records. Matches unstructured medical notes to specific codes and assigns predictive denial risk scores. | Hugging Face Transformers, PyTorch, FastAPI, Scikit-learn |
| Workflow & Audit Queue | Routes high-risk validation failures to human reviewers. Generates an unchangeable trail for complete historical tracking. | React.js, Node.js, PostgreSQL Audit Tables, RabbitMQ |
| MLOps & Monitoring | Monitors live production models for real-time drift. Tracks how accurately the system predicts insurance network behavior. | MLflow, Prometheus, Grafana |
Balancing FHIR and EDI 837 Environments
Modern healthcare systems require your architecture to bridge the gap between emerging web standards and legacy transmission formats smoothly.
- The official FHIR R4 Claim resource natively supports complex adjudication or authorization requests for medical goods and services.
- However, the standard ANSI X12 837 file remains the mandatory federal format used to transfer healthcare claims to actual payer networks.
- Therefore, your ingestion service must map real-time FHIR data objects into structured EDI loops without losing clinical text definitions.
- This translation layer ensures your machine learning tools can read rich clinical notes while your outbound pipeline stays perfectly compliant with traditional clearinghouse requirements.
After the architecture is clear, the rules engine becomes the most important build decision. Selecting the correct processing logic dictates how quickly your platform adapts to shifting regulatory environments.
AI Models Needed for AI Claims Scrubbing System
An intelligent claims scrubbing system needs multiple AI models, not one general-purpose model. The production stack should include NLP for clinical text extraction, machine learning for denial risk scoring, anomaly detection for unusual billing patterns, LLM-assisted summarization, and confidence scoring that routes uncertain claims to human reviewers.
Therefore, your engineering team must build specialized networks that handle specific pieces of the medical billing puzzle.
Consequently, you avoid the trap of using a single large model to handle exact regulatory code validation. This multi-model strategy ensures your system stays accurate while processing millions of diverse data variables.
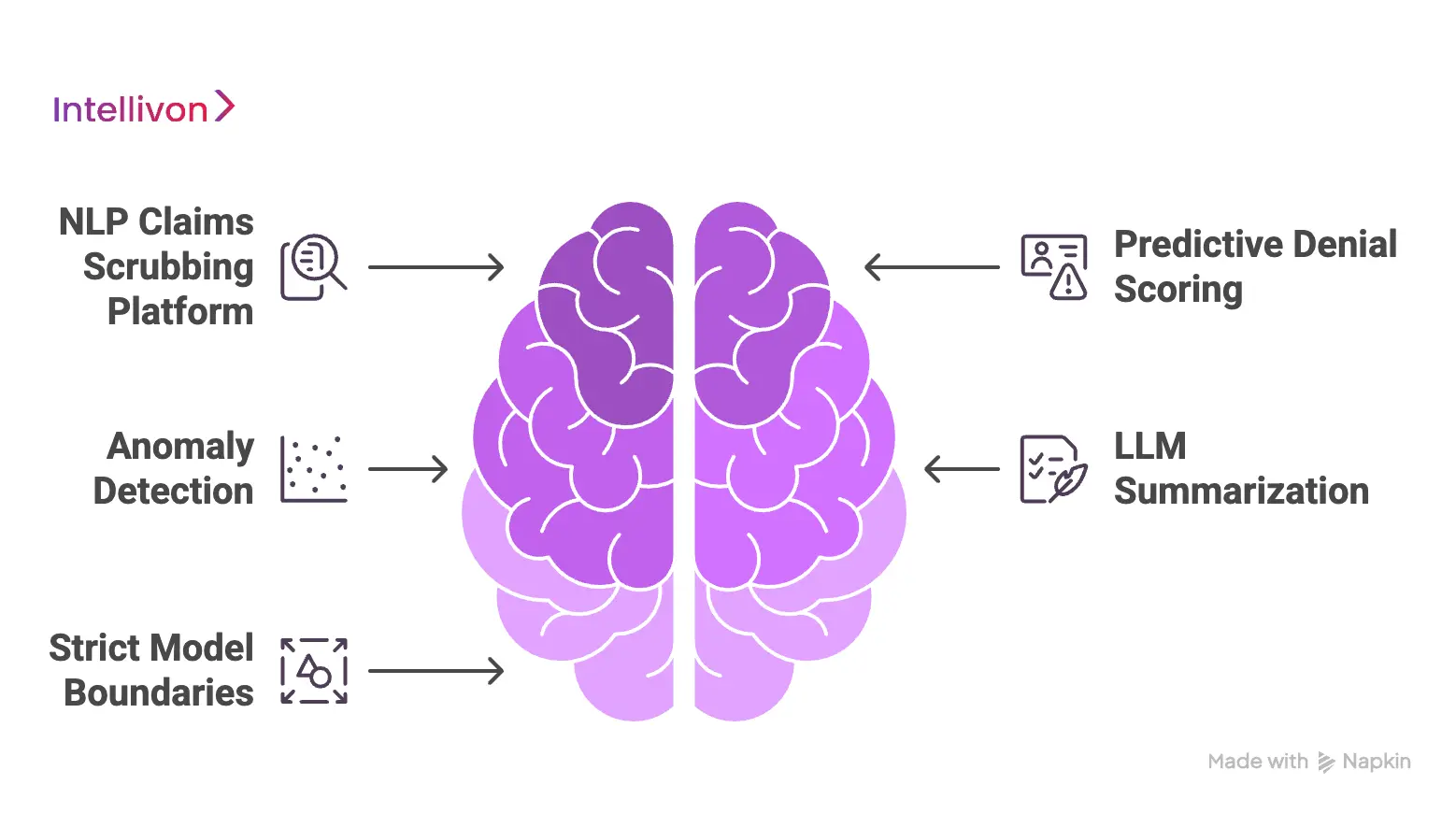
1. Building an NLP Claims Scrubbing Platform
Medical billers frequently face denials because the explicit text inside doctor notes does not match the finalized billing codes.
- Traditional systems cannot read these raw clinical narratives, which leaves hidden code mismatches completely undetected before submission.
- To solve this gap, an NLP claims scrubbing platform is built that implements named entity recognition models to extract explicit clinical concepts from unstructured notes.
- This architecture scans the text for specific time statements, anatomical locations, and exact drug quantities to confirm that your documentation supports the final CPT code selection.
- For instance, advanced machine learning tools read historical charts to flag documentation gaps like a missing modifier before the file ever reaches a human reviewer.
2. Predictive Denial Scoring and Anomaly Detection
Once the system extracts the text data, machine learning classification networks evaluate the overall financial risk of the file.
- Predictive Denial Scoring: A supervised machine learning model analyzes historical billing logs to assign a real-time risk percentage to every outbound claim file.
- Anomaly Detection: An unsupervised model spots unusual billing patterns, such as a sudden spike in a rare code combination that might trigger an unexpected payer audit.
- These predictive tools flag high-risk items instantly, allowing you to intercept problem bills before they leave your billing environment.
3. LLM Summarization and the Explainability Layer
When an AI model flags a claim as high risk, your human billing team needs to know exactly why the system flagged it.
- LLMs should never be used to decide if a claim is valid, but they excel at creating brief explainability summaries for manual operators.
- The system uses an LLM to read the complex risk outputs from your underlying machine learning models and translate them into a clear two-sentence warning.
- This summary highlights the exact location of the code error and suggests the specific documentation fix needed to clear the validation block.
- Therefore, your staff can fix complicated medical billing errors in seconds without searching through massive multi-page medical charts manually.
4. Establishing Strict Model Boundaries and Human Review
Maintaining long-term system accuracy requires setting absolute operational limits between your software code, your neural networks, and your human operators.
The following framework outlines how a health network routes processing tasks across these strict boundaries:
- Rules Engine: Handles deterministic, non-negotiable checks like rigid formatting rules, quarterly NCCI limit updates, and basic eligibility requirements.
- NLP Layer: Focuses entirely on documentation evidence extraction, pulling explicit terms from doctor narratives to verify medical necessity.
- Machine Learning Model: Evaluates historical payer behavior drift and models model drift to score the overall statistical probability of a claim denial.
- LLM Layer: Translates complex statistical risk scores into simple text summaries to help billing agents manage exceptions quickly.
- Human Review Queue: Acts as the final decision authority whenever the automated systems output a confidence score below your preset threshold.
AI improves claim decisions only when the platform has the right data pipelines feeding it. Consequently, developers must integrate these advanced classification systems directly into their existing electronic health networks.
Data Requirements for Custom Claims Scrubbing Platform
Custom claims scrubbing platform development depends on clean historical and operational data from claims, encounters, codes, denials, remittance files, eligibility checks, authorizations, payer rules, contracts, and clinical documentation. Without this foundation, AI models may flag obvious formatting errors but completely miss the payer-specific patterns that drive real revenue leakage.
Therefore, your development team must establish robust data engineering pipelines before training any machine learning networks.
Consequently, you ensure your models learn from actual operational realities rather than theoretical compliance guidelines. This data-first approach forms the foundation of a highly accurate predictive system.
1. Compiling Historical Claim Transactions
Your machine learning models require a deep historical baseline to accurately identify hidden rejection risk patterns.
- The engineering team must ingest 12 to 24 months of completed medical billing data into a centralized data lake.
- This repository must contain balanced records of fully approved claims alongside both fully rejected and denied files.
- Gathering this historical volume allows your classification algorithms to establish clear mathematical baselines for clean bills across diverse payer networks.
2. Integrating Inbound Remittance Data
Understanding exactly why an insurance company refused payment requires deep automated tracking of post-submission transaction logs.
- The system maps structured electronic remittance datasets directly back to the original outbound billing code loops.
- Specifically, the official 2025 CAQH Index analyzes national transaction volume, cost, and completion times to pinpoint exactly where manual administrative workarounds inflate operational burdens.
- The ingestion pipeline extracts standardized CARC and RARC codes from these transaction logs to classify payment updates automatically.
- This continuous tracking allows your platform to convert complex transaction-level operational data into actionable pre-submission edits.
3. Eligibility and Prior Authorization Mapping
The platform must link real-time patient validation events directly to your core financial billing lines.
- The system logs historical eligibility verification records to confirm that specific insurance plans were active on the exact date of medical service.
- It parses prior authorization approvals to ensure that specific tracking tokens match the submitted clinical procedure codes.
- Linking these pre-care data points helps you stop immediate administrative denials caused by basic clerical mismatches.
4. Ingesting Unstructured Clinical Documentation
Training natural language processing models to verify medical necessity requires direct access to original narrative source texts.
- The data pipeline ingests unstructured clinical notes, doctor charts, and typed encounter summaries directly from your integrated EHR networks.
- It combines this raw narrative information with precise charge capture logs to verify that every billed service has matching physical evidence.
- This clinical data injection allows the platform to catch complex documentation gaps before an external payer audit flags them.
5. Mapping Claim Correction and Override Histories
Tracking how your human billing experts resolve past errors provides excellent training data for your automated recommendation networks.
- The database records every manual correction, text adjustment, and code update performed by your billing staff over the past two years.
- It tracks historical manual rule override events to identify which automated validation filters produce excessive false positives.
- Learning from these human adjustments helps the software optimize its internal confidence scoring thresholds continuously.
6. Establishing the Production Data Readiness Checklist
Before your developers write any custom validation algorithms, your infrastructure must clear a strict engineering checklist to guarantee long-term system performance:
- Data Volume Minimums: Secure a comprehensive cache containing twelve to twenty-four months of continuous medical billing histories.
- Format Linkage: Create exact relational mappings connecting outbound 837 files, incoming 835 remittance data, and individual EHR encounter records.
- Denial Normalization: Standardize varied commercial rejection codes into a unified taxonomy to ensure clean machine learning analysis.
- Specialty Profiles: Build unique baseline coding frameworks categorized by individual clinical medical fields.
- Audit Trail Completeness: Ensure your historical log files track all manual edits, user overrides, and system timestamps completely.
Once the data foundation is ready, the build process can move from concept to implementation. Consequently, engineering teams can begin executing the structured technical milestones required to launch a production-ready enterprise solution.
How to Build AI Claims Scrubbing Software Step by Step
Building a production-ready validation platform requires a highly structured engineering pipeline that balances rigid regulatory compliance with flexible machine learning capabilities. Moving from a messy, disjointed data environment to an automated, intelligent revenue shield involves seven distinct development milestones. Each step must be executed in precise sequence to ensure the final platform remains reliable under heavy transaction loads.
Consequently, engineering teams avoid building a fragile, hardcoded script that fractures when insurance guidelines change. Here is how Intellivon builds an enterprise-grade solution for your revenue cycle.
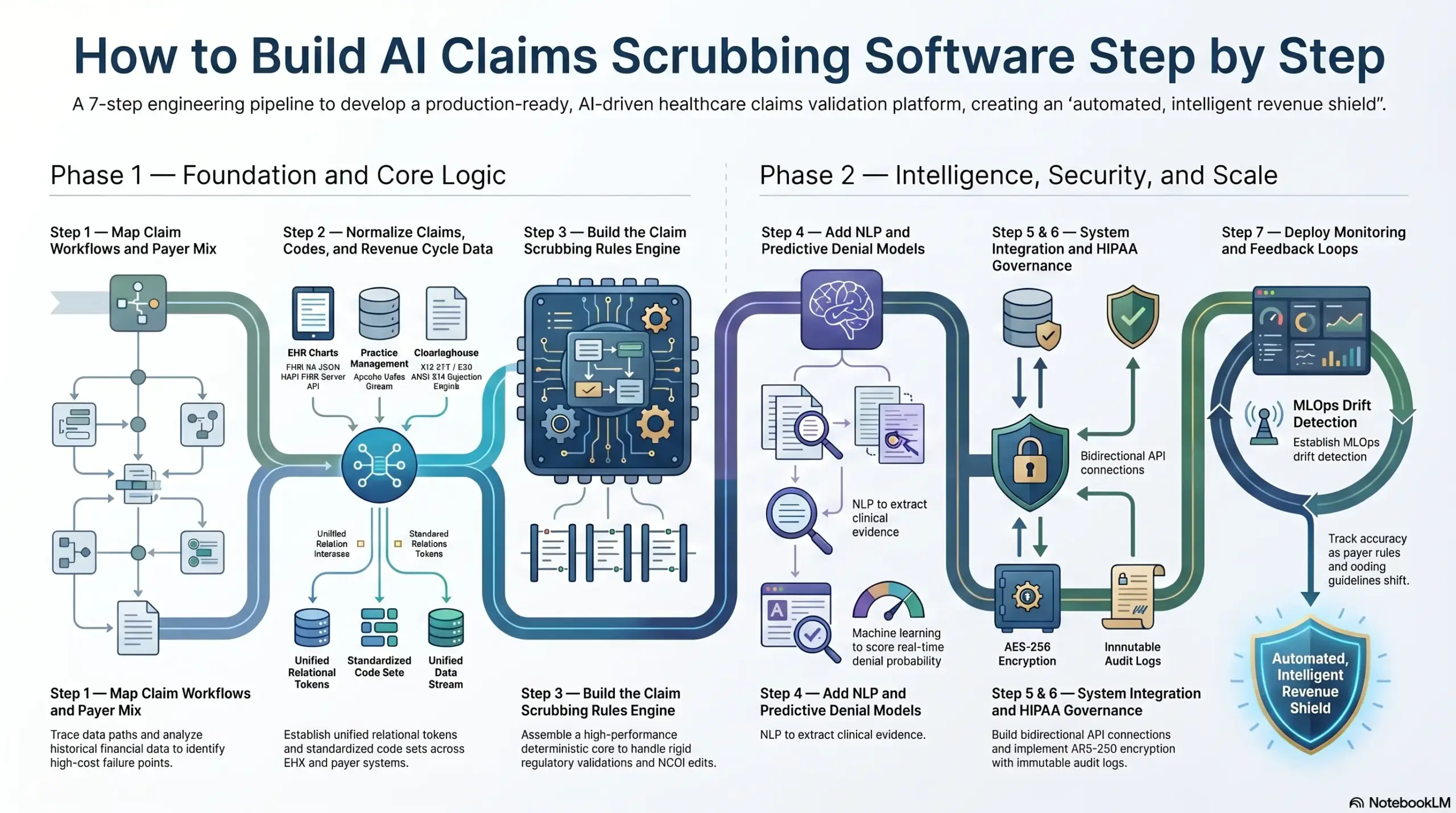
Step 1 — Map Claim Workflows and Payer Mix
We begin by mapping how claims move from encounter creation to submission, rejection, denial, correction, and payment.
This foundational stage identifies exactly which errors must be caught before submission, which payer rules cause the most manual rework, and which clinical specialties require custom validation profiles.
- Workflow Extraction: We trace the complete data path across your billing ecosystem to identify hidden handoff friction.
- Denial Data Segments: Our engineers analyze twelve to twenty-four months of historical financial data to separate simple clearinghouse formatting rejections from complex payer clinical denials.
- Payer Taxonomy Matrix: We create a dedicated processing index that maps your specific payer mix, separating federal programs from commercial networks.
- Metric Baselines: We calculate your exact baseline clean claim rate and first-pass acceptance rate before writing any code.
What Goes Wrong If Skipped
Skipping this initial mapping phase causes development teams to build generic validation checks while missing the high-cost, payer-specific failure points that actually cause your revenue leakage.
Step 2 — Normalize Claims, Codes, and Revenue Cycle Data
We normalize your incoming claim data before building any rules or AI models because EHR, PM, clearinghouse, and payer systems rarely describe the same claim field in the same way.
A reliable scrubber requires shared identifiers, normalized code sets, and consistent denial categories across every integrated network.
- Claim ID Normalization: We establish unified relational tokens that link disparate clinical and financial records back to a single patient encounter.
- Code Set Standardization: Our pipeline maps varying database inputs into a centralized, auto-updating repository of active CPT, HCPCS, and ICD-10-CM codes.
- Provider and Location Alignment: We normalize physician National Provider Identifier (NPI) logs, location credentials, and taxonomies across all clinics.
- Field Ingestion Mapping: We construct automated data pipelines that parse and map corresponding variables between FHIR objects and electronic ANSI X12 loops.
| System Source | Input Format | Target Normalized Entity | Ingestion Technology |
| EHR Charts | FHIR R4 JSON | Clinical Encounter Object | HAPI FHIR Server API |
| Practice Management | Database SQL | Billing Line Item | Apache Kafka Stream |
| Clearinghouse Feedback | X12 277 / 835 | Normalized Denial Category | ANSI X12 Ingestion Engine |
What Goes Wrong If Skipped
If you skip this data normalization step, your machine learning models will learn noisy, inaccurate relationships. Consequently, your dashboards will misreport the true causes of denials, and your billing teams will quickly lose trust in the platform’s automated recommendations.
Step 3 — Build the Claim Scrubbing Rules Engine
We build the rules engine as the deterministic core of the claims scrubber because billing compliance requires perfectly explainable decisions.
This high-throughput layer validates code combinations, payer requirements, NCCI edits, MUE limits, modifier logic, medical necessity rules, duplicate claims, timely filing, and authorization mismatches before any AI scoring begins.
- Deterministic Core Assembly: We build a high-performance rules engine using open-source frameworks like Drools to handle rigid regulatory validations in parallel.
- Quarterly Update Integration: The system connects directly to federal registries to update national code bundles and volume limits automatically every ninety days.
- Payer Rule Versioning: We implement strict database versioning so compliance teams can track exactly which rules were active on any historical date of service.
- Permission Governance: Our developers build rule testing modules that allow administrators to configure specialized validation profiles without writing code.
What Goes Wrong If Skipped
Without a deterministic engine core, the platform becomes an unreliable suggestion tool rather than a defensible claims editing system. It will struggle to enforce non-negotiable federal regulations, leading to compliance risks and preventable audit flags.
Step 4 — Add NLP and Predictive Denial Models
We add AI only where it improves context, prediction, or prioritization beyond fixed rules.
At the same time, we deploy Natural Language Processing (NLP) to extract evidence from clinical notes, while predictive machine learning models score overall denial risk using historical payer behavior, documentation gaps, and remittance outcomes.
- NLP Parsing Pipeline: We deploy specialized named entity recognition networks to scan unstructured doctor charts for concrete clinical evidence.
- Evidence Translation: The software compares extracted clinical terms directly against your finalized billing codes to catch diagnosis-procedure mismatches early.
- Predictive Risk Scoring: Supervised machine learning models analyze hundreds of historical transaction variables to calculate a real-time denial probability score.
- Explainability Interface: We use large language models exclusively to translate statistical model vectors into clear, two-sentence text summaries for human reviewers.
What Goes Wrong If Skipped
Omitting the AI layer leaves your organization exposed to complex, text-based billing errors. Your software may catch basic missing names, but it will completely miss complex documentation gaps and changing payer behaviors.
Step 5 — Integrate EHR, PM, Clearinghouse, and Payer Systems
We integrate the claims scrubber directly into the software applications your billing teams already use because disconnected validation creates duplicate work.
The platform connects with EHRs, practice management systems, clearinghouses, payer APIs, eligibility systems, and authorization workflows using HL7, FHIR R4, EDI, and secure web APIs.
- Bidirectional Integration: We build secure API connections to pull draft bills out of your practice management tools and write back verified corrections automatically.
- FHIR Interoperability: Our developers use modern web frameworks to pull clean clinical metadata directly from active EHR chart servers.
- Clearinghouse Connections: We establish direct communication channels to transmit outbound electronic billing batches directly into your clearinghouse networks.
- Feedback Ingestion Loops: The integration layer ingests incoming digital transaction files to update your predictive analytics dashboards automatically.
What Goes Wrong If Skipped
Skipping deep integration forces your billing staff to manually export spreadsheets and re-enter code corrections across multiple applications. This friction eliminates the real-time efficiency advantages of having an automated validation system.
Step 6 — Build HIPAA Controls, Audit Logs, and Access Governance
We build HIPAA controls into the platform from the very first development sprint because claims scrubbing software handles protected health information (PHI), billing data, payer rules, and user decisions.
The infrastructure incorporates administrative, physical, and technical safeguards to fully satisfy the federal HIPAA Security Rule.
- Data Encryption Protocols: We implement strict cryptographic protection for all PHI both while moving across networks and while stored in databases.
- Identity Access Governance: Our engineers build granular role-based controls to ensure only authorized billing agents can access sensitive patient data files.
- Immutable Audit Logging: We design unchangeable database log tables that capture a permanent timeline of every single system correction and manual rule override.
- Secure Model Inference: We containerize our machine learning and NLP models within your private cloud environment to prevent third-party data leakage.
| Security Component | Technical Implementation | Compliance Purpose |
| Data At Rest | AES-256 Bit Encryption | Protects stored patient charts and records |
| Data In Transit | TLS 1.3 Secure Channels | Secures real-time FHIR and EDI transfers |
| User Access | OAuth 2.0 with Granular RBAC | Restricts PHI exposure to authorized billers |
| System Modification | Ledger-Style Immutable Audit Logs | Satisfies federal compliance trace requirements |
What Goes Wrong If Skipped
Failing to embed rigorous security safeguards directly into your initial database designs makes the platform incredibly difficult to certify and risky to scale. A single unencrypted log file can expose your organization to massive federal non-compliance penalties.
Step 7 — Deploy Monitoring, Feedback Loops, and Rule Updates
We deploy continuous monitoring and automated feedback loops because claims scrubbing accuracy changes constantly as payer rules, provider behavior, coding guidelines, and denial patterns shift.
The platform actively tracks model performance, rule decay, and real-time override rates.
- MLOps Drift Detection: We establish automated tracking pipelines to monitor live machine learning model accuracy and identify shifts in payer behavior patterns.
- Rule Performance Analytics: The system flags active validation rules that produce high false-positive rates to prevent unnecessary workflow delays.
- Automated Alert Channels: We construct immediate notification pipelines that alert engineering teams the moment performance metrics drop below your custom thresholds.
- Continuous Ingestion Loops: The platform automatically reads daily payment data streams to refine its underlying risk classification models continually.
What Goes Wrong If Skipped
If you launch your platform without automated performance monitoring, its accuracy will slowly degrade. As insurance companies quietly alter their internal processing rules, your software will continue using outdated logic, and your denial rates will return to baseline.
With the build process clear, the next question is cost. Understanding the financial investment required helps healthcare leaders budget for a highly effective, enterprise-grade deployment.
AI Claims Scrubbing Software Development Cost Breakdown
AI claims scrubbing software development usually costs $180,000–$300,000+, depending on claim volume, payer-rule complexity, EHR and clearinghouse integrations, AI model depth, HIPAA controls, and enterprise workflow requirements.
A focused MVP with core rules and limited integrations sits closer to $180,000–$220,000, while a multi-specialty, multi-payer platform with NLP, predictive denial scoring, payer intelligence, and MLOps can reach $260,000–$300,000+.
| Development Phase | Estimated Cost | What It Covers |
| Discovery, workflow mapping, and denial analysis | $15,000–$25,000 | Claim lifecycle mapping, payer mix review, denial root-cause analysis, MVP scope |
| UX/UI for billing, coding, and review queues | $18,000–$30,000 | Scrubbing dashboard, claim error views, reviewer queues, override workflows |
| Backend architecture and data normalization | $30,000–$55,000 | Claim objects, payer profiles, code mapping, API structure, data pipelines |
| Rules engine development | $35,000–$70,000 | NCCI, MUE, LCD/NCD, payer edits, modifiers, timely filing, COB, specialty rules |
| EHR, PM, clearinghouse, and payer integrations | $35,000–$75,000 | HL7, FHIR R4, EDI 837/835, clearinghouse APIs, payer APIs |
| NLP and AI model development | $35,000–$70,000 | Clinical text extraction, denial scoring, confidence scoring, and explainability |
| HIPAA security and audit controls | $20,000–$40,000 | RBAC, encryption, PHI tokenization, immutable audit logs, access governance |
| QA, testing, deployment, and monitoring | $18,000–$35,000 | Test claims, rule simulation, model testing, deployment, MLOps dashboards |
Ongoing maintenance usually costs 18%–30% of the initial build cost per year. This covers payer-rule updates, NCCI/MUE changes, security patches, AI monitoring, integration maintenance, new payer logic, compliance documentation, and performance tuning.
Free Cost Estimate: Get Your AI Claims Scrubbing Software Cost Estimate
Planning an AI claims scrubbing software build? Intellivon can help you estimate development cost based on claim volume, payer mix, rules engine depth, EHR integrations, AI model requirements, HIPAA controls, and rollout scope.
Build vs Buy Claims Scrubbing Software: When Custom Wins
Build AI claims scrubbing software when your payer mix, specialty workflows, denial patterns, compliance needs, or product roadmap cannot fit inside a vendor’s standard rules.
Buy when you need fast deployment, basic claim checks, limited customization, and predictable subscription pricing more than workflow ownership or proprietary payer intelligence.
Therefore, the choice depends entirely on your transactional volume and strategic business objectives.
Consequently, you avoid wasting capital on software that either underperforms or overcomplicates your daily revenue cycle. The following structured framework helps technology leaders navigate this critical operational decision:
| Evaluation Factor | Choose Commercial Buy Path | Choose Custom Build Path |
| Validation Needs | Basic formatting and syntax edits | Complex clinical NLP necessity matching |
| Workflow Design | Standardized, out-of-the-box templates | Multi-specialty, multi-contract pipelines |
| Engineering Focus | Limited internal technical ownership | Desire for proprietary data asset ownership |
| Strategic Goal | Fast deployment with standard utility | Launching a differentiated healthcare product |
| Error Handling | Catching simple typographical errors | Real-time predictive denial risk scoring |
When Custom Software Architecture Outperforms Off-The-Shelf Tools
Custom software does not win because it is more advanced or uses complex tech stacks.
- Instead, it wins when your enterprise reaches a level of claim volume or contract complexity that off-the-shelf software cannot handle.
- For example, large healthcare networks deal with distinct local payer interpretations that commercial tools fail to track.
- Furthermore, many founders ask on communities like Reddit whether automated scrubbers can actually replace human billers or if they only catch low-level data errors.
- The truth is that commercial software only handles low-level formatting typos, whereas a custom build serves as an active decision-support layer for your human staff.
- Building a tailored system allows you to embed specialized coding logic directly into your daily operations.
- This focus ensures you capture lost revenue that generic commercial applications completely ignore.
Even when custom wins, there are cases where it is the wrong move. Understanding the hidden engineering risks of custom development helps your team plan for long-term product viability.
ROI Metrics for AI-Powered Claims Editing Software
AI-powered claims editing software should be measured by clean claim rate, first-pass acceptance rate, rejection rate, denial rate, rework cost, days in AR, manual review time, appeal volume, and recovered revenue.
These operational metrics prove whether the platform actually improves revenue operations or only adds another useless digital dashboard. Therefore, your business case must tie engineering milestones directly to measurable financial improvements.
Tracking these core performance indicators helps your finance team calculate a precise amortization schedule.
1. Measuring Core Transmission and Validation Rates
The primary indicator of an effective pre-submission infrastructure is an immediate drop in transaction rejections.
- Clean Claim Rate: This baseline measures the exact percentage of medical bills sent out that contain absolutely zero formatting or data structural errors on their first transmission.
- First-Pass Acceptance Rate: This index tracks the proportion of submitted transaction files that successfully enter a payer’s processing system without immediate automated pushback.
- Improving these numbers reduces the total volume of claims trapped in expensive administrative loops.
2. Quantifying Rework Costs and Days in AR
Manual data corrections strain human resources and slow down overall cash collection cycles significantly.
- Cost Per Reworked Claim: This metric calculates the complete administrative overhead, including software costs and labor hours, required to fix a denied bill manually.
- Days in AR: This performance metric tracks the average number of days it takes your organization to collect full cash payments from insurance carriers.
- Specifically, the official 2025 CAQH Index highlights a massive $21 billion industry savings opportunity that remains achievable by eliminating administrative waste and expanding electronic automation (Source: [CAQH, 2026]).
- Using automated validation cuts out manual entry delays, directly reducing your outstanding collection cycles.
3. Evaluating Model Performance and User Trust
An enterprise-grade system must maintain a careful balance between aggressive error trapping and operational workflow speed.
- AI False-Positive Rate: This parameter tracks how often your machine learning models flag a completely valid claim as a high-risk error.
- Rule Override Rate: This tracking log measures how frequently your experienced billing staff manually bypasses an automated system warning.
- If your system produces high false-positive rates, your staff will develop notification fatigue and lose trust in the automated suggestions.
4. Tracking Long-Term Revenue Integrity Gains
The ultimate test of an advanced revenue control layer is its ability to protect cash collections through precise underpayment detection.
- The system scans clinical narratives to ensure your team is not undercoding complex encounters and leaving earned revenue behind.
- Simultaneously, it prevents overcoding errors that lead to expensive, retrospective structural audits by major insurance networks.
- This proactive auditing ensures your revenue integrity remains secure throughout shifting compliance landscapes.
5. Operational Performance Benchmarks
To justify the upfront software build costs, your technology team should aim for the following production-ready target improvements after launch:
| Performance Metric | Pre-Launch Baseline | Targeted Post-Launch Improvement |
| Clean Claim Rate | Current historical percentage | +5% to +12% absolute improvement |
| First-Pass Acceptance Rate | Current system percentage | +4% to +10% system increase |
| Preventable Denials | Monthly count and value | 15% to 30% absolute reduction |
| Manual Review Time | Staff hours per week | 25% to 45% operational time savings |
| Rework Cost Burden | Average cost per claim | 15% to 35% cost reduction |
| Days in AR Cycles | Current outstanding average | 5 to 15-day operational reduction |
Setting explicit performance targets ensures your engineering team designs specific data pipelines to meet your core financial goals.
Conclusion
AI claims scrubbing software is not just a temporary feature. It is a core revenue-cycle infrastructure layer that combines payer rules, claim validation, clinical evidence, AI scoring, compliance, and continuous monitoring.
Ultimately, AI claims scrubbing software delivers lasting value only when healthcare enterprises build it around payer-rule change, integration reality, and audit-ready human review.
An experienced development partner helps healthcare teams build custom claims scrubbing systems around real workflows, rather than generic automation templates.
If you are evaluating a custom build, the next step is not development. It is a clear roadmap for scope, integrations, rules, AI models, cost, and compliance.
Build AI Claims Scrubbing Software With Intellivon
Intellivon builds AI claims scrubbing software around real healthcare revenue workflows, payer-specific edit logic, secure EHR integrations, explainable AI recommendations, HIPAA controls, and measurable claim accuracy outcomes.
With 500K+ engineering hours, ex-MAANG engineers, and deep experience across AI, healthcare platforms, SaaS systems, API integrations, and enterprise software development, Intellivon helps healthcare teams move from static claim scrubbers to scalable AI-powered claims validation infrastructure.
A. Define The Right Claims Scrubbing Scope
Before development starts, we help you define which claims validation workflows should be automated first and which workflows still need billing, coding, or compliance review.
This includes mapping pre-submission claim validation, payer-specific edit rules, NCCI edits, MUE checks, code validation, modifier validation, medical necessity checks, eligibility verification, prior authorization mismatches, and denial-prone claim patterns.
We help you plan:
- MVP scope and claim validation priorities
- Payer-specific and specialty-specific edit logic
- Rules engine and AI automation opportunities
- Denial reduction, ROI, and KPI assumptions
- Compliance, rollout, and build-vs-buy requirements
B. Design The Platform Architecture Around Revenue Cycle Operations
AI claims scrubbing software needs an architecture that can handle real payer, coding, billing, and documentation complexity. That means the platform must process claims data, clinical documentation, payer rules, clearinghouse responses, user decisions, audit logs, and AI recommendations without creating another disconnected tool.
Intellivon designs AI claims scrubbing platforms around a modular, scalable architecture.
Your platform can include:
- Claims data normalization and EDI 837 validation
- Payer-rule processing with NCCI and MUE edit logic
- NLP clinical text extraction and denial risk scoring
- Human review queues and audit-ready activity logs
- Role-based dashboards and revenue analytics infrastructure
C. Build AI Models That Billing Teams Can Trust
AI should help billing, coding, and denial teams catch claim risks earlier with clear evidence. It should not create black-box recommendations that teams cannot explain, review, or defend.
Intellivon builds AI models with clinical evidence extraction, confidence scoring, review thresholds, and explainable recommendations so teams can understand why a claim, code, modifier, payer rule, or documentation gap was flagged.
Your AI claims scrubbing platform can include:
- NLP extraction from clinical documentation
- Diagnosis-procedure and medical necessity validation support
- Denial risk scoring and payer-specific pattern recognition
- Undercoding, overcoding, and claim error prioritization
- Confidence scoring and human-in-the-loop review workflows
D. Integrate With Healthcare Billing And Claims Systems
AI claims scrubbing software depends on accurate data movement across clinical, billing, clearinghouse, payer, and finance systems.
That is why Intellivon plans integrations early. We help connect your platform with the systems needed to validate claim data, review documentation, apply payer edits, submit claims, analyze rejections, process remittance files, and monitor revenue performance.
We support integrations across:
- Epic, Cerner / Oracle Health, and practice management systems
- FHIR APIs, HL7 interfaces, and secure healthcare APIs
- Clearinghouses, EDI 837 workflows, and EDI 835 workflows
- Payer APIs, eligibility verification, and prior authorization systems
- Finance systems, data warehouses, and BI tools
Ready To Build AI Claims Scrubbing Software?
If you are planning to build AI claims scrubbing software, Intellivon can help you define the right roadmap before development begins.
We will help you identify the best claims validation opportunities, map payer-specific rules, plan EHR and clearinghouse integrations, design secure architecture, build explainable AI models, and create a scalable platform around clean claim performance.
Ready to build a controlled AI claims validation infrastructure for your hospital, RCM company, physician group, or healthcare SaaS platform? Contact Intellivon today to discuss your project.
Things To Know About AI Claims Scrubbing Software
Q1. How much does AI claims scrubbing software cost to build?
AI claims scrubbing software usually costs $85,000–$290,000+ to build. A focused MVP with rules-based validation and one or two integrations sits near the lower range, while an enterprise platform with NLP, denial prediction, payer-rule updates, EDI 837/835, FHIR R4, HIPAA controls, and MLOps moves toward the higher range.
Q2. How long does claims scrubber software development take?
A2. Claims scrubber software development usually takes 5–9 months for an MVP and 9–15 months for an enterprise rollout. The timeline depends on payer-rule complexity, historical claims data quality, EHR access, clearinghouse integration, AI model requirements, and compliance review depth.
Q3. Can AI claims scrubbing software be HIPAA compliant?
A3. Yes, AI claims scrubbing software can be HIPAA compliant when it includes encryption, role-based access control, PHI tokenization, audit logs, secure APIs, vendor controls, and documented administrative, physical, and technical safeguards. HHS states that the HIPAA Security Rule protects electronic PHI through those safeguard categories.
Q4. Should healthcare companies build or buy AI claims editing software?
A4. Healthcare companies should buy AI claims editing software when they need standard claim checks quickly. They should build when payer mix, specialty logic, denial patterns, workflow ownership, SaaS commercialization, or compliance requirements create needs that vendor templates cannot support.