Key Takeaways:
- Real-time risk scoring must operate inside the transaction, not after it, as instant payment rails and machine-speed fraud have made latency a direct liability.
- Effective scoring engines combine event-driven pipelines, pre-computed feature stores, and multi-model orchestration to deliver decisions in under 100ms.
- Reducing false positives requires dynamic thresholds mapped to customer lifetime value.
- Build costs range from $10,000 for a rule-based MVP to $80,000 and above for a full real-time engine with compliance architecture, multi-model orchestration, and sub-100ms decisioning.
- How Intellivon builds real-time risk scoring systems your fintech fully owns, with event-driven pipelines, continuous learning loops, and compliance-ready explainability built in from day one.
The conventional approach to risk scoring was built on the assumption that decisions could tolerate delay. Batch processing, quarterly rule updates, and models retrained on lagging data all made sense when transactions settled in days. That assumption no longer holds. This is because Instant payment rails, autonomous B2B transactions, and synthetic identity fraud operating at machine speed have made latency a liability, but not an inconvenience.
Risk scoring must now happen inside the transaction and not after it. That requires event-driven pipelines, pre-computed feature stores, and models serving decisions in under 100ms without sacrificing regulatory explainability or business accuracy.
This is a hard infrastructure problem disguised as a data science problem, and platforms treating it as the latter are building on shaky ground. At Intellivon, we build real-time risk scoring systems for fintech enterprises navigating exactly this gap. This post breaks down what it actually takes to build one that performs at the speed fraud moves.

Why Do Fintechs Need Real-Time Risk Scoring?
Fintechs operate in high-velocity environments where delays in risk assessment can lead to massive losses from fraud or defaults. Real-time risk scoring uses AI and machine learning to evaluate transactions instantly, protecting revenue and compliance in a market projected to exceed $300 billion by 2027.
1. Combating Fraud in High-Volume Transactions
Fraud losses in fintech hit $12.5 billion globally in 2025, with synthetic identities and account takeovers surging 32% year-over-year.
Real-time scoring analyzes 300+ signals, like device fingerprints, behavioral biometrics, and velocity checks, flagging 95% of anomalies within milliseconds, far surpassing batch processing. This prevents $1.2 million average breach costs per incident.
2. Meeting Instant Approval Demands
Digital lending and BNPL platforms require sub-second decisions to match user expectations, where 70% abandon carts if approvals exceed 3 seconds.
Real-time models dynamically score creditworthiness using alternative data (e.g., utility payments, social graphs), boosting approvals by 20-30% while cutting defaults 15%. Batch systems simply can’t compete in peer-to-peer or embedded finance.
3. Ensuring Regulatory Compliance
Regulations like PSD3 and DORA mandate continuous monitoring, with fines reaching €20 million for lapses. At the same time, real-time scoring automates KYC/AML checks, reducing false positives by 40% via adaptive thresholds. It generates audit-ready explainability logs, vital as 62% of regulators now demand real-time reporting.
4. Optimizing Capital and Liquidity
Traditional scoring ties up capital in reserves; real-time granularity enables just-in-time provisioning, freeing 10-25% in liquidity for growth amid Basel IV constraints. Dynamic models adjust risk weights instantly to market shifts, minimizing 5-8% over-reserving common in static approaches.
Fintechs need real-time risk scoring to slash fraud, accelerate growth, and comply in a $40 billion AI risk management market expanding 28% CAGR through 2030. Early adopters like Nubank report 50% fraud drops, whereas laggards risk obsolescence as competitors embed it natively.
What Is a Real-Time Risk Scoring System?
A real-time risk scoring system is a digital engine that evaluates financial transactions instantly. It uses automated algorithms to assign a numerical safety score to every action as it happens.
Consequently, businesses can detect fraud or credit risks in milliseconds rather than hours. This technology relies on live data streams to stop suspicious activities before they finish. It provides a vital layer of protection for modern digital platforms.
Core Components of a Risk Scoring System
Building a robust risk engine requires a high-performance architecture. These systems must process millions of data points without causing latency. Business leaders should focus on four foundational pillars to ensure system reliability.
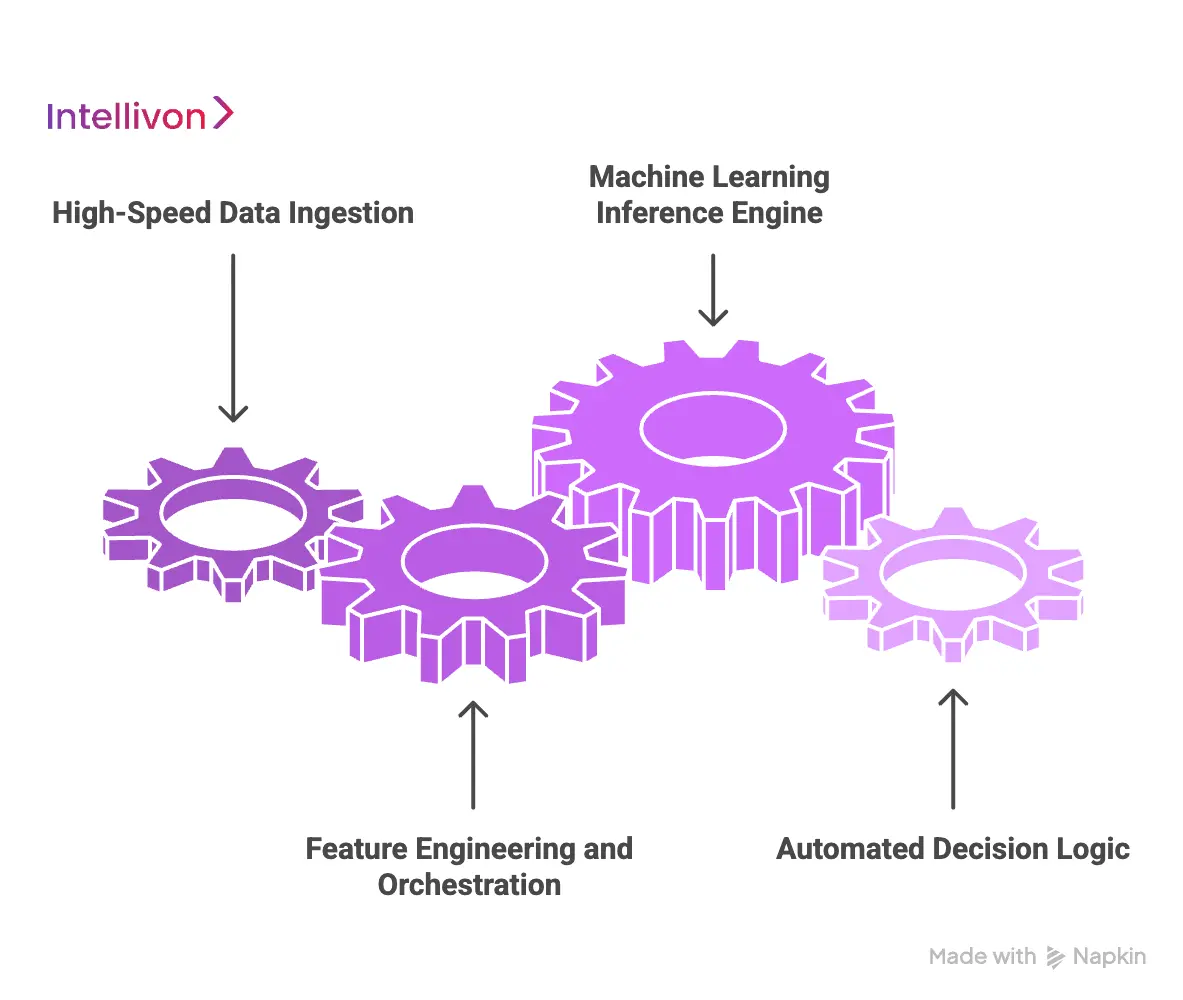
1. High-Speed Data Ingestion
Modern scoring engines rely on real-time data pipelines. Systems like Apache Kafka or AWS Kinesis ingest transaction streams as they occur. This layer captures device IDs, geolocation, and user behavior instantly.
High-speed ingestion ensures the model has fresh data for every assessment. Without this, the system falls back into slow batch processing.
2. Feature Engineering and Orchestration
Raw data must transform into actionable insights through feature engineering. This component calculates variables like transaction frequency or sudden spending spikes.
Orchestration layers then coordinate these features across different models. Effective orchestration prevents data silos and ensures consistent scoring across the platform.
3. Machine Learning Inference Engine
The inference engine is the brain of the system. It runs pre-trained models against incoming data to generate risk scores. These models often use Gradient Boosting or Neural Networks for high accuracy.
At the same time, speed is critical here, as the engine must return a score in milliseconds. A well-tuned engine balances complex calculations with rapid execution.
4. Automated Decision Logic
The final component translates scores into business actions. Decision logic applies pre-defined rules to accept, flag, or reject transactions. For example, a score above 80 might trigger an immediate block.
Conversely, mid-range scores may require multi-factor authentication. This automation removes human error and ensures instant response times.
These core components must work in perfect harmony to protect the enterprise. Integrating these layers allows for a seamless user experience without compromising security. A modular approach ensures that each part can scale as transaction volumes grow.
How Signals Become One Live Risk Score
Transforming raw data into a single, actionable risk score is a highly sophisticated process. It requires the simultaneous orchestration of hundreds of variables within a fraction of a second.
This live synthesis allows the system to distinguish between a legitimate customer and a high-risk threat instantly.
The Signal Synthesis Process
The system begins by gathering diverse signals from every touchpoint. These inputs range from hardware specifics to real-time behavioral patterns.
By aggregating these fragments, the scoring engine creates a comprehensive digital snapshot of the transaction. The following signals are critical for an accurate live score:
- Behavioral Biometrics: Tracking how a user types, scrolls, or holds their device to verify identity.
- Device Fingerprinting: Identifying unique hardware attributes and detecting the presence of VPNs or emulators.
- Transaction Velocity: Measuring the frequency and volume of attempts within a specific time window.
- Geospatial Analysis: Comparing the current IP location against the user’s historical travel patterns.
- Historical Context: Checking the transaction against the user’s typical spending habits and risk profile.
2. Weighting and Final Output
Once the signals are gathered, the machine learning model applies specific weights to each factor. For instance, a device mismatch might carry more weight than a slightly higher transaction value.
The engine then calculates the final probability of risk. Therefore, the resulting score represents the mathematical likelihood of fraud or default. This streamlined approach ensures that high-volume platforms remain both secure and user-friendly.
Decision Outputs: Approve, Review, Block, Step-up
The final stage of the risk scoring lifecycle is the execution of a specific business action. Once the engine generates a numerical value, the system must determine the most appropriate response.
This automated decisioning ensures that security protocols do not hinder the customer journey unnecessarily.
Mapping Scores to Actionable Outcomes
A well-configured platform uses tiered thresholds to categorize risk levels. These thresholds allow the system to handle thousands of requests per second without manual intervention.
Each category triggers a unique workflow designed to balance safety with user experience. Enterprise leaders typically utilize the following four decision outputs:
- Approve: This occurs for low-risk scores where the transaction matches historical patterns. The process completes instantly, ensuring a frictionless experience for the legitimate user.
- Block: The system terminates the request immediately when scores indicate high-confidence fraud. This prevents capital loss and protects the platform’s integrity from malicious actors.
- Review: Mid-range scores that appear suspicious but not definitively fraudulent are sent for manual inspection. This allows human analysts to investigate complex cases without outright rejection.
- Step-Up: If the system detects a minor anomaly, it triggers additional authentication. Users may need to provide a biometric scan or a one-time passcode to proceed safely.
Strategic implementation of these outputs minimizes operational overhead while maximizing protection. By automating the majority of decisions, the enterprise can focus resources on high-stakes investigations. This tiered approach provides the agility required to scale in competitive fintech markets.
How Is AI Reshaping Credit Risk in Fintech?
AI is fundamentally altering the economics of risk management by enabling institutions to process information as it is created. This shift allows for more profitable lending decisions without increasing risk exposure.
Consequently, AI has moved from a luxury to a foundational requirement for survival in the modern economy.
1. Why static risk models fail in modern fintech
Traditional credit models rely heavily on credit bureau data and basic financial ratios that offer only a lagging snapshot. These static views fail to capture the reality of gig economy workers or individuals with thin financial files.
Therefore, legacy systems often reject creditworthy borrowers, resulting in significant lost revenue and higher default rates during market shifts.
2. From rule engines to adaptive AI systems
Old-school rule engines operate on rigid “if-then” logic, which sophisticated attackers can easily identify and circumvent. Adaptive AI systems solve this by learning from every new transaction and identifying emerging patterns that humans might miss for weeks.
This continuous learning cycle ensures the system remains resilient against evolving financial threats.
3. Real-time decisioning powered by ML inference
Machine learning inference allows platforms to evaluate a borrower’s risk profile in milliseconds during the application process. This speed is essential for embedded finance products that require instant approvals at the point of sale.
Automation here significantly reduces the operational cost per application while maintaining high accuracy.
4. AI as a competitive advantage in lending
Lenders utilizing AI can price risk with higher precision, offering competitive rates to low-risk individuals ignored by traditional banks. This precision allows for aggressive growth strategies without compromising the balance sheet.
Furthermore, sub-second approvals create a superior user experience that drives long-term customer retention.
By integrating adaptive intelligence, fintechs transform risk from a static barrier into a dynamic growth lever. This transition ensures that every lending decision is both scalable and high-margin.
What Types of AI Systems Power Credit Risk?
Fintech leaders must choose the right architectural mix to balance accuracy with speed. Different AI models excel at specific tasks, from predicting defaults to unmasking complex fraud rings.
Understanding these systems is the first step toward building a high-margin lending or payment platform.
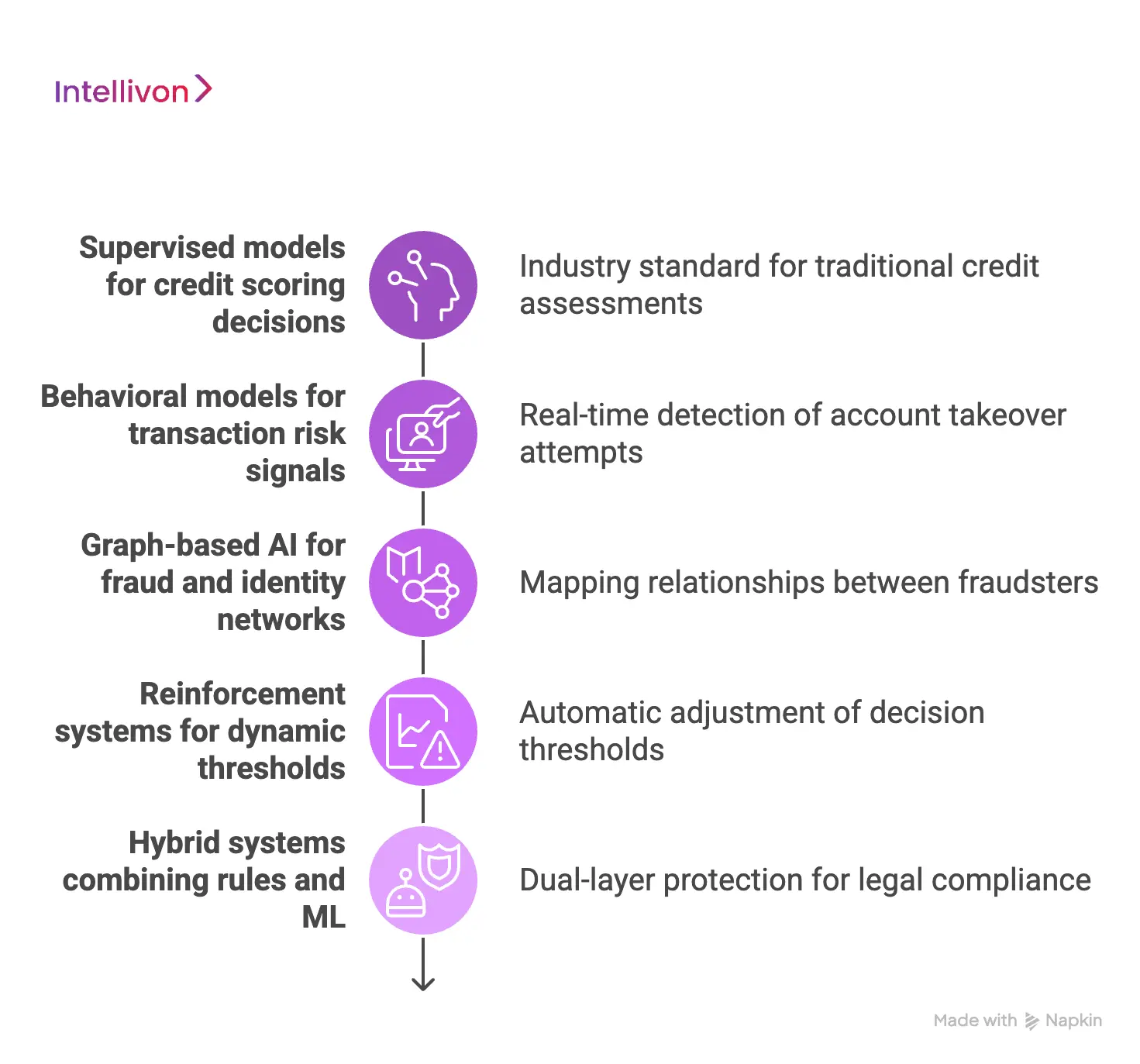
1. Supervised models for credit scoring decisions
Supervised learning is the industry standard for traditional credit assessments. These models are trained on massive datasets of historical “good” and “bad” loans.
By analyzing past outcomes, the AI learns to predict the likelihood of a future default. This approach provides the high level of accuracy required for capital-heavy lending decisions.
2. Behavioral models for transaction risk signals
Behavioral models focus on how users interact with a digital interface. These systems analyze subtle signals like typing speed, scroll patterns, and session duration.
Any deviation from a user’s typical digital footprint triggers an immediate alert. Consequently, these models are exceptional at detecting account takeover attempts in real-time.
3. Graph-based AI for fraud and identity networks
Modern fraudsters often operate in organized rings using interconnected identities. Graph-based AI maps these relationships by linking phone numbers, IP addresses, and bank accounts.
This structural analysis reveals hidden clusters of synthetic identities that standard models might miss.
- Identify synthetic IDs: Detects accounts created from fragments of real data.
- Map fraud rings: Visualizes the links between seemingly unrelated transactions.
- Uncover circular payments: Spots funds moving in loops to artificially inflate credit scores.
4. Reinforcement systems for dynamic thresholds
Risk shifts based on market conditions and criminal tactics. Reinforcement learning systems adjust decision thresholds automatically based on performance feedback.
If a system becomes too restrictive, the AI “learns” to loosen parameters to recover lost revenue. This self-tuning capability ensures the platform remains profitable without constant manual intervention.
5. Hybrid systems combining rules and ML
The most resilient platforms utilize a hybrid approach. This combines the “hard rules” of human experts with the “soft intelligence” of machine learning. While the AI identifies complex patterns, the rule engine ensures the system strictly adheres to legal and compliance mandates.
This dual-layer protection offers the best of both worlds: speed and total control.
By integrating these specialized AI types, enterprises create a comprehensive shield against financial loss. This multi-layered defense is what separates market leaders from their competitors.
Which Use Cases Need Real-Time Risk Scores?
Strategic capital deployment requires identifying specific operational bottlenecks where speed directly impacts profitability. For many enterprises, the difference between a secure transaction and a lost asset is measured in milliseconds.
Real-time scoring depends on enabling high-velocity business models that legacy systems would stifle.
1. Transaction fraud scoring at authorization
The most critical use case is the point of authorization. At this moment, the system must decide whether to permit a fund transfer or card swipe. Real-time scoring analyzes the metadata of the transaction against the user’s historical profile instantly.
Therefore, suspicious activity is blocked before the money ever leaves the account. This immediate intervention is the only effective way to stop high-frequency fraud attacks.
2. Onboarding and synthetic identity risk checks
Customer acquisition costs are high, so friction during onboarding must be minimal. However, synthetic identity fraud (where cyber-criminals blend real and fake data) is a growing threat.
Real-time risk engines cross-reference application data with external databases and device telemetry during the sign-up flow. This allows the system to verify a legitimate human in seconds. Consequently, you can grow your user base rapidly without opening the gates to bad actors.
3. AML alert prioritization and case routing
Anti-Money Laundering (AML) teams are often overwhelmed by “noise” and false positives. Real-time scoring prioritizes alerts based on the severity and probability of actual criminal behavior. The system routes high-risk cases to senior investigators immediately while automating low-risk documentation.
This triage process ensures that your most expensive human resources focus on the most dangerous threats. It transforms compliance from a slow manual queue into an agile, data-driven operation.
4. Credit and exposure checks in live workflows
In modern fintech, credit is often extended dynamically, such as in BNPL or margin trading. Real-time exposure checks ensure that a user’s total risk remains within safe limits as they transact. If a user’s risk profile changes, the system can adjust limits instantly.
This prevents over-exposure and protects the firm’s liquidity during volatile market shifts. It allows for more aggressive lending by maintaining a constant, live grip on the balance sheet.
Implementing these use cases ensures that your platform remains both scalable and secure. These applications turn risk management into a core driver of your firm’s operational efficiency and growth.
What Data Powers Better Risk Scores in Fintech?
Strategic risk management is only as strong as the data feeding the engine. For enterprise leaders, the goal is not simply to collect more information, but to ingest high-fidelity signals at the right time.
Quality data prevents model drift and ensures resilience against sophisticated financial threats.
1. Payment and KYC signals
Core assessment begins with a fusion of payment metadata and identity verification signals. Beyond basic transaction amounts, the system must analyze alternative data like phone tenure and digital footprints.
These signals reveal whether a user is a legitimate consumer or a synthetic identity. Combining these with authentication results creates a multi-dimensional view of every participant in your ecosystem.
2. Streaming and historical data
High-performance scoring requires a balance between “hot” streaming data and “cold” historical archives. Streaming pipelines ingest live events like geolocation shifts or sudden velocity spikes instantly.
Conversely, historical data provides the baseline context needed to recognize normal spending habits. Integrating these flows allows the AI to spot anomalies invisible in isolated datasets.
3. Avoiding data swamps
Many firms fail by dumping unorganized data into reservoirs, creating “data swamps” that are impossible to navigate. These swamps lack the governance needed for real-time retrieval, leading to high latency.
Instead, leaders are moving toward a unified “signal layer” that orchestrates all decision-making. A single source of truth ensures consistent risk strategies across your entire portfolio.
Curating a high-signal environment ensures your risk models are both predictive and protective. This foundation allows for aggressive expansion while maintaining a lean, automated compliance footprint.
How Should You Architect the Scoring Engine?
Building a world-class risk engine requires more than just an accurate model. The underlying architecture must support massive throughput while maintaining extreme reliability.
For entrepreneurs, the goal is to build a system that remains invisible to the user but impenetrable to the fraudster. A successful build balances three critical factors: speed, scalability, and structural flexibility.
1. Event-driven pipelines for low-latency scoring
Modern risk engines must transition from scheduled processing to event-driven architectures. Using tools like Apache Kafka or Redpanda allows the system to react the moment a transaction is initiated.
Each event triggers a chain reaction of validation checks without waiting for a database to refresh. Consequently, the system can handle sudden traffic spikes during peak shopping seasons without slowing down.
2. Feature stores for real-time and batch access
A feature store acts as a centralized library for the data points your models need to make a decision. This component is vital because it ensures that the data used for training is identical to the data used during live scoring.
By unifying these views, you eliminate “training-serving skew,” which is a common cause of model failure.
- Unified Data Access: Provides a single interface for both historical research and live inference.
- Point-in-time Correctness: Ensures the model only sees data that would have been available at the moment of the transaction.
- Rapid Feature Deployment: Allows data scientists to push new risk signals into production in minutes rather than weeks.
3. Rules, models, and orchestration in one stack
The most resilient engines do not rely on a single algorithm. Instead, they use an orchestration layer to manage a “stack” of multiple models and expert rules simultaneously. This layer decides which model to trust based on the transaction type or user segment.
Therefore, a hybrid approach ensures that even if one model misses a pattern, the secondary layers provide a necessary safety net.
4. Designing for sub-100ms decision latency
In the competitive world of fintech, every millisecond counts toward the customer experience. Designing for sub-100ms latency requires optimizing every step, from data ingestion to the final decision output.
This often involves moving computations closer to the data source or using high-performance languages like Go or Rust for the scoring microservices. Maintaining this speed ensures that security checks never become a reason for cart abandonment.
A robust architecture turns technical complexity into a repeatable business advantage. It provides the stability required to scale your platform into a global market leader.
How Do You Reduce False Positives at Scale?
Excessive false positives act as a silent tax on fintech growth by alienating legitimate users. When a system flags an innocent customer, it creates friction that leads to permanent churn. Consequently, optimizing for precision is as critical as detection.
Sophisticated leaders prioritize “surgical” risk management that targets bad actors while leaving honest transactions untouched.
1. Why most teams over-trigger alerts
Most platforms suffer from “alert fatigue” because their systems are tuned for maximum catch rates without considering the cost of errors. Broad parameters in rule-based engines capture legitimate edge cases alongside actual fraud.
This results in a massive backlog of manual reviews that slows down the entire business. Furthermore, teams often fear lowering thresholds, unaware that customer friction often costs more than the potential loss.
2. Setting thresholds by loss and customer value
Strategic risk management requires mapping thresholds to customer lifetime value (CLV). A long-term user with a perfect history should not face the same scrutiny as a first-time applicant.
By applying “lighter” friction to your most profitable segments, you ensure security resources focus on high-uncertainty transactions. This approach balances safety with the need to maintain a seamless user experience for your best customers.
3. Protecting high-value B2B payment flows
B2B transactions involve larger sums, making a false positive devastating to professional relationships. Real-time scoring for B2B must account for historical business cycles and established supplier-buyer relationships.
- Firmographic Validation: Verifying the legitimacy of the business entity instantly.
- Authorized Signatory Analysis: Confirming the identity of the specific individual initiating the transfer.
- Invoice Consistency: Matching transaction amounts to typical procurement patterns.
4. Testing threshold changes without major exposure
Updating risk parameters in a live environment is dangerous without “Shadow Mode” testing. This involves running new scoring logic in the background alongside the production system to analyze performance.
Therefore, you can confidently deploy updates only after proving they reduce false positives while maintaining high detection. This ensures your updates are data-driven rather than speculative.
By moving away from “one-size-fits-all” security, you protect both your revenue and your reputation. This balance is the hallmark of a mature, enterprise-grade risk operation.
What Compliance Must the System Support?
Regulatory bodies demand that AI-driven decisions remain transparent, defensible, and legally sound.
Consequently, your architecture must feature “compliance by design” to prevent crippling fines and reputational damage.
1. ECOA, UDAP, AML, and model risk controls
Fintechs must navigate a complex web of mandates to maintain operational licenses. The Equal Credit Opportunity Act (ECOA) and UDAP rules ensure that models do not discriminate or mislead consumers.
Simultaneously, Anti-Money Laundering (AML) controls require continuous monitoring to block illicit fund flows in real-time.
Model risk management is equally vital, requiring regular stress testing to ensure AI accuracy during sudden market shifts.
2. Audit trails for every scoring decision
Regulators now require total “explainability” for every automated decision your platform executes. An audit trail must capture which specific signals influenced a score at a precise point in time.
This includes the model version, ingested features, and the threshold logic applied during the transaction. Therefore, you maintain an immutable record of the decision process for any future regulatory inquiry or customer challenge.
3. Fairness checks across customer segments
Bias in machine learning is a significant legal liability that requires proactive mitigation. Automated fairness checks must run continuously to ensure protected groups are not unfairly penalized by the engine.
- Disparate Impact Testing: Measuring if model outcomes disproportionately affect specific demographic segments.
- Feature Bias Mitigation: Ensuring that proxy data points do not inadvertently introduce historical prejudices.
- Segmented Performance Monitoring: Tracking model accuracy across different age, gender, or geographic groups.
4. Data residency and cross-border risk scoring
Scaling internationally requires strict adherence to data residency laws like GDPR or DPDP. These rules often mandate that personal data remains within specific geographic borders during its processing.
Building a cross-border system requires a decentralized architecture that scores transactions locally while syncing global risk intelligence. This ensures you maintain a unified defense without violating the digital sovereignty of local privacy laws.
Adhering to these standards protects the firm from legal exposure while building critical trust with stakeholders. This proactive approach ensures your platform remains resilient against the next wave of global financial regulation.
How Do You Fit This Into Legacy Infrastructure?
Replacing a core banking system is often a non-starter due to the extreme risk and technical debt involved. Therefore, the strategic goal is to build an intelligent “overlay” that enhances legacy systems without requiring a total overhaul.
1. Working around brittle APIs
Legacy cores often rely on rigid, SOAP-based APIs or even flat-file transfers that cannot support sub-second decisioning. To bypass these bottlenecks, architects deploy “Sidecar” microservices that handle the heavy AI lifting outside the main core.
These services listen to transaction logs or database change events to trigger risk scores asynchronously. Consequently, you can modernize your risk logic while the legacy system continues to perform its primary accounting functions.
2. Unifying fragmented systems
Many enterprises operate across a patchwork of siloed systems acquired through mergers or rapid expansion. Instead of a costly replatforming effort, you can implement a unified “Abstraction Layer” that consolidates data from these disparate sources into a single stream.
- API Gateways: Acting as a central hub to standardize data formats across different subsystems.
- Metadata Normalization: Ensuring a “date of birth” field looks the same regardless of its source system.
- Centralized Orchestration: Managing risk policies once and pushing them across all business units simultaneously.
3. Handling vendor outages and missing signals
Relying on external data providers for KYC or credit checks introduces a significant point of failure. A resilient architecture includes “Fallback Logic” that allows the system to make a safe decision even when a third-party vendor is offline.
If a primary identity signal is missing, the engine can pivot to secondary behavioral signals to calculate a “Confidence Score.” This ensures that your platform stays operational and secure during widespread infrastructure outages.
4. Phased rollout without blocking operations
Moving to a real-time system is a journey, not a singular event. A phased rollout allows you to introduce the new engine to a small percentage of low-risk traffic first. This “Canary Deployment” strategy enables you to monitor the AI’s performance in a live environment without risking the entire portfolio.
Therefore, you can iterate on your models and iron out integration bugs before scaling the solution to your most critical B2B or high-volume retail flows.
Integrating modern AI into legacy environments turns your existing infrastructure into a powerful asset rather than a liability. This phased approach provides the most stable path toward true digital transformation in finance.
How We Build Real-Time Risk Scoring Systems Step-By-Step
At Intellivon, we view risk architecture as a strategic asset rather than a defensive barrier. Our methodology focuses on eliminating latency while maximizing the predictive power of every data point.
We follow a rigorous, eight-step engineering lifecycle to ensure your platform remains secure, compliant, and ready for global scale.
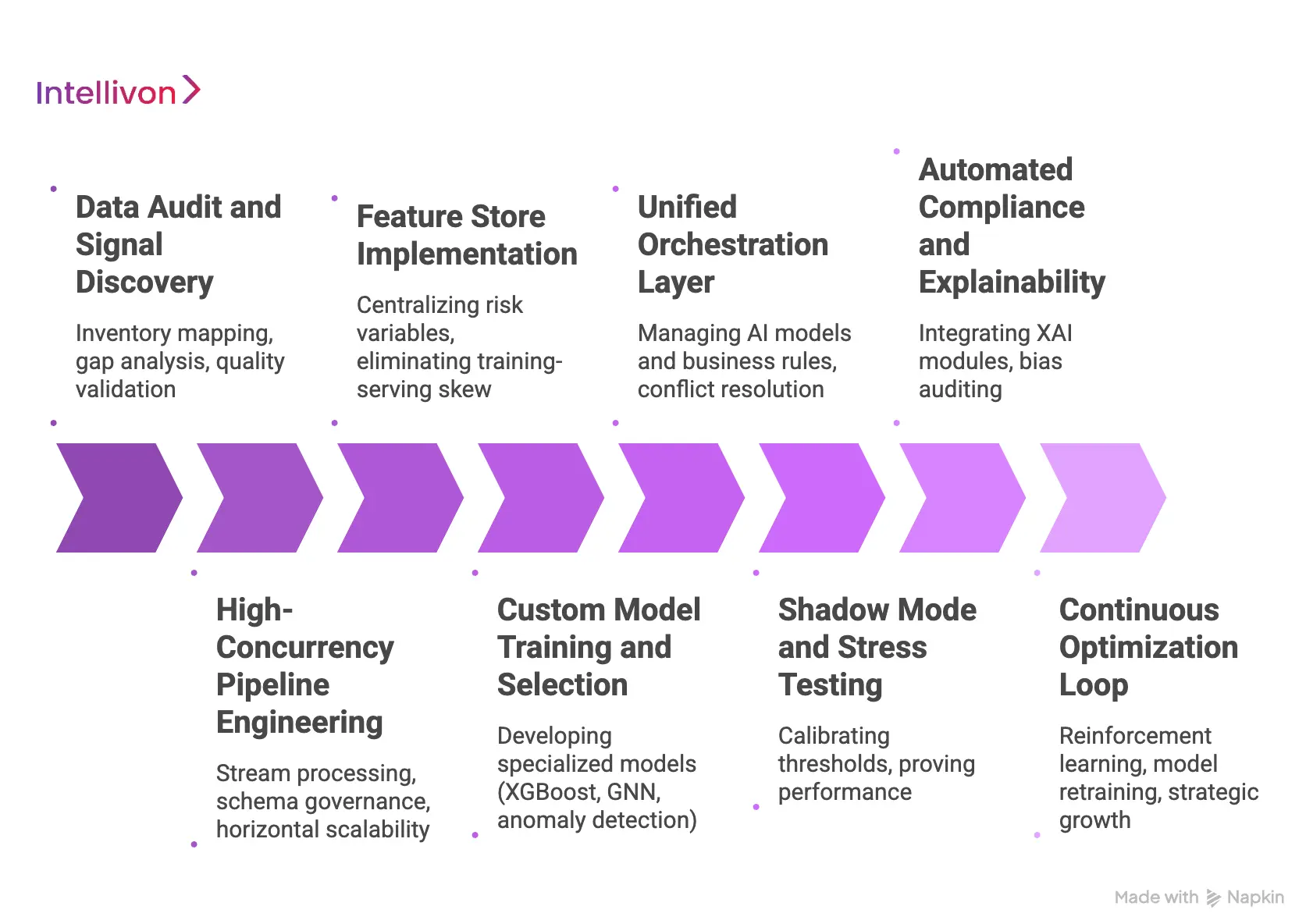
1. Data Audit and Signal Discovery
We begin by auditing your existing data landscape to identify high-value risk signals. This involves uncovering hidden insights in your transaction logs and identifying gaps where alternative data could improve accuracy.
- Inventory Mapping: We catalog every available internal data source, from legacy SQL databases to modern event logs.
- Gap Analysis: Our team identifies missing signals, such as behavioral biometrics or third-party identity intelligence, needed for a complete risk profile.
- Quality Validation: We stress-test the reliability and “freshness” of your data to ensure it can support real-time decisioning.
2. High-Concurrency Pipeline Engineering
Our team builds the “nervous system” of the platform using event-driven architectures. This ensures that every transaction is ingested and processed in under 50 milliseconds, regardless of global volume.
- Stream Processing: We utilize Apache Kafka or Redpanda to manage high-throughput data streams without bottlenecks.
- Schema Governance: We implement strict data schemas to ensure consistency as information flows from your front-end to the scoring engine.
- Horizontal Scalability: The pipeline is designed to scale automatically during peak periods, such as Black Friday or major market shifts.
3. Feature Store Implementation
We centralize your risk variables in a production-grade feature store. This eliminates the “training-serving skew” by ensuring your models use the same data logic during development as they do in live production.
| Feature Type | Source | Purpose |
| Streaming Features | Live Clickstream | Captures immediate behavior (e.g., typing speed, session duration). |
| Aggregated Features | Transaction History | Calculates 24-hour spending velocity or 30-day averages. |
| Static Features | KYC/Identity | Verifies account age, nationality, and verified identity status. |
4. Custom Model Training and Selection
We develop a suite of specialized models tailored to your specific business risks. This multi-model approach provides deeper coverage than any generic, off-the-shelf solution.
- Gradient Boosting (XGBoost): Excellent for credit risk and predicting the likelihood of loan defaults.
- Graph Neural Networks (GNN): Specifically designed to unmask complex fraud rings by analyzing interconnected data points.
- Anomaly Detection: Unsupervised models that flag “never-before-seen” patterns that may indicate a new type of cyberattack.
5. Unified Orchestration Layer
We deploy an orchestration engine that manages the interplay between AI models and expert-defined business rules. This layer decides which logic to prioritize based on the specific transaction context or user profile.
- Conflict Resolution: If a rule says “Block” but the model says “Approve,” the orchestration layer applies your specific business priority.
- Dynamic Routing: Low-risk users skip intensive checks to save on API costs, while high-risk users are routed through deeper verification layers.
- Microservices Architecture: Every component is decoupled, allowing you to update specific models without taking the entire system offline.
6. Shadow Mode and Stress Testing
Before going live, we run the system in “Shadow Mode” against your real traffic. This allows us to calibrate thresholds and prove performance without affecting a single live user or transaction.
- Performance Comparison: We measure the new engine against your legacy system to quantify the improvement in detection and speed.
- Threshold Tuning: We simulate various “what-if” scenarios to find the perfect balance between fraud prevention and user friction.
- Load Testing: We push the system to its breaking point to ensure 99.99% uptime during massive transaction spikes.
7. Automated Compliance and Explainability
We integrate “Explainable AI” (XAI) modules that generate an audit trail for every score. This ensures your platform satisfies ECOA and GDPR requirements with transparent, defensible decision-making logic.
- Local Interpretability: For every rejected transaction, the system provides specific “reason codes” explaining why the score was high.
- Bias Auditing: We run continuous tests to ensure the model is not inadvertently discriminating against protected demographic groups.
- Regulatory Reporting: Automated tools generate the documentation required for DORA, PSD3, and other global financial mandates.
8. Continuous Optimization Loop
Post-launch, we implement reinforcement learning loops that allow the system to adapt to new fraud patterns automatically. This ensures your defense grows stronger with every transaction processed.
- Feedback Integration: Confirmed fraud cases are fed back into the model to improve future detection accuracy.
- Model Retraining: We automate the deployment of updated models as soon as a performance gain is detected in the testing environment.
- Strategic Growth: As your business expands into new markets, we adjust the signals and weights to reflect local risk profiles.
By following this structured path, Intellivon transforms complex technical requirements into a streamlined, high-performance reality. Ready to transform your risk management into a growth engine? Partner with Intellivon to lead the fintech evolution.
Cost to Build A Real-Time Risk Scoring System
Building a real-time risk scoring system involves designing a full-stack decision infrastructure that can process transactions in milliseconds, integrate with multiple data sources, and remain compliant under regulatory scrutiny.
At Intellivon, we approach cost as a function of system capability, data complexity, and real-time performance requirements. The goal is not just to build a model, but to deploy a production-grade risk engine that scales with your fintech operations.
Cost Ranges by Scope and Complexity
The total investment depends on how advanced and scalable the system needs to be.
| Build Scope | Timeline | Investment Range |
| MVP (rules + basic scoring) | 6–10 weeks | $10,000 – $20,000 |
| AI-enabled scoring system | 10–16 weeks | $20,000 – $40,000 |
| Advanced real-time risk engine | 4–6 months | $40,000 – $80,000 |
- MVP systems typically include rule-based scoring, limited data inputs, and basic dashboards.
- AI-enabled systems introduce machine learning models, feature stores, and real-time pipelines.
- Advanced systems support high transaction volumes, multi-model orchestration, and full compliance layers.
This phased approach allows fintechs to launch quickly and evolve toward more sophisticated decision-making without a full rebuild.
Key Cost Drivers Across Data and ML Layers
Several technical factors directly influence the cost of building a risk scoring system:
- Data integration complexity: Number of sources (KYC, payments, device, third-party APIs)
- Real-time infrastructure: Event streaming, low-latency pipelines, and orchestration layers
- Model sophistication: Rules vs ML vs hybrid systems with multiple models
- Feature engineering layer: Building reusable, real-time feature stores
- Compliance requirements: Audit trails, explainability, and regulatory alignment
The more real-time and interconnected your system is, the more investment is required in architecture, and not just models.
Hidden Costs Teams Often Underestimate
Many fintech teams underestimate the operational cost of running a real-time risk system in production.
- Model monitoring and drift detection systems
- Continuous retraining of pipelines and data labeling
- False positive handling and manual review workflows
- Infrastructure scaling with transaction growth
- Compliance audits and reporting requirements
Ignoring these factors early often leads to higher rework costs and slower scaling later.
Conclusion
Building a real-time risk scoring system is a strategic necessity for market leadership. By transitioning from reactive batch processing to proactive AI-driven intelligence, your enterprise can slash fraud while accelerating growth.
High-performance architecture is required to secure your capital and optimize your global operations. Transform your risk management into a scalable, competitive advantage that empowers your long-term vision.
Build a Real-Time Risk Scoring System With Intellivon
Building an AI-native payment infrastructure rests on designing a system where every payment decision is made in real time, across fraud, routing, settlement, and compliance. At Intellivon, we build payment infrastructure where AI is embedded into the core decisioning layer.
This enables faster transactions, lower risk, and seamless scalability across modern payment rails. Our approach ensures your platform operates in real-world conditions, handling high volumes and evolving fraud patterns without performance trade-offs.
A. Designing Real-Time Payment Decision Architectures
Payment infrastructure today operates in milliseconds. We design systems where every transaction is evaluated, routed, and executed instantly without latency.
- Low-latency decision pipelines for sub-second transaction processing.
- Event-driven systems using streaming frameworks like Kafka.
- Unified decision engines across fraud, routing, and compliance.
- Seamless orchestration across card, ACH, RTP, and cross-border rails. This ensures every payment decision happens within the transaction flow, not after it.
B. Enabling Agent-Ready Payment Architectures
As agentic commerce evolves, payment systems must support AI-initiated transactions safely and reliably.
- Separation of decisioning and execution layers for modular control.
- Secure handling of credentials through advanced tokenization.
- Delegation frameworks for controlled payment authority.
- Compatibility with emerging agentic protocols and global standards. This ensures your infrastructure is ready for AI agents without compromising control or security.
C. Embedding Explainability and Compliance Into the Core
AI in payments must be transparent and compliant by design. We build systems that meet regulatory requirements without slowing operations.
- Transaction-level explainability for every automated AI decision.
- Continuous audit trails across all system actions.
- Compliance-ready architecture aligned with PCI DSS and GDPR.
- Role-based controls for governance and investigation workflows. This ensures your system remains auditable, compliant, and regulator-ready at all times.
D. Integrating AI Across the Payment Ecosystem
AI-native infrastructure only works when it connects seamlessly across systems. We design integration layers that unify your payment stack.
- API-first architecture for modular and fast system connectivity.
- Integration with gateways, processors, and core banking systems.
- Unified intelligence across card, ACH, RTP, and cross-border flows.
- Phased modernization without disrupting existing operations. This allows you to evolve your infrastructure without replacing everything at once.
At Intellivon, we help you map your transaction volume, system complexity, and business goals into a clear AI-native architecture and roadmap. Talk to our team to get a tailored payment infrastructure strategy and project estimate.
FAQs
Q1. What is real-time risk scoring in fintech?
A1. Real-time risk scoring is an automated process that evaluates the safety of a financial transaction as it occurs. By using machine learning and live data streams, the system assigns a risk value in milliseconds. This allows platforms to block fraud or approve credit instantly, ensuring security without compromising the user experience.
Q2. How fast should a risk scoring engine be?
A2. A modern risk engine must achieve sub-second latency to remain competitive. Ideally, the entire decisioning process, from data ingestion to final output, should occur in under 200 milliseconds. This speed ensures that security checks do not cause transaction timeouts or lead to customer frustration during high-velocity digital checkout flows.
Q3. Can real-time scoring work with legacy systems?
A3. Yes, you can integrate real-time scoring without replacing your existing core. By utilizing sidecar microservices and API abstraction layers, modern engines ingest data from legacy databases in parallel. This approach allows you to run sophisticated AI logic externally, providing a high-speed intelligence layer over older, slower banking infrastructure.
Q4. How do fintechs reduce false positives?
A4. Fintechs reduce false positives by shifting from rigid rules to adaptive machine learning models. These systems use behavioral biometrics and historical context to distinguish between legitimate edge cases and actual fraud. Implementing “Shadow Mode” testing allows teams to fine-tune thresholds, ensuring that only truly suspicious activities trigger an intervention.
Q5. How much does a risk scoring system cost?
A5. The cost varies based on transaction volume, data complexity, and the level of customization required. Building a custom enterprise solution involves investment in high-performance architecture, cloud infrastructure, and specialized AI engineering. While upfront costs are significant, the long-term ROI is delivered through reduced fraud losses and lower manual review overhead.