Key Takeaways
-
AI denial prediction software scores claims before submission and routes high-risk cases for review.
-
Production builds require claims history, EDI 835 data, and payer-specific denial reason codes.
-
Supervised ML models, explainable AI controls, and drift monitoring to keep prediction accuracy production-grade.
-
Development costs range from $90,000 to $320,000, with 6 to 12 months for hospital-grade platforms.
-
How Intellivon builds denial prediction as a revenue-cycle infrastructure where prediction, workflow, compliance, and ROI integrate.
Revenue cycle teams at most hospitals are working on a problem they can only see in hindsight. A claim goes out, the payer adjudicates it, and an EDI 835 remittance file arrives 30 to 45 days later carrying the denial reason codes. By that point, the documentation is locked, the coding decision is weeks old, and the submission window has already closed. As a result, the team is recovering from them, one appeal at a time, cycle after cycle.
That timing gap is exactly what AI denial prediction software is built to close. By scoring each claim’s denial probability before it leaves the billing system, it moves the intervention point upstream, where corrections are still possible, and revenue is still recoverable. Instead of working a denial queue, the revenue cycle team works a risk queue. The operational difference is significant.
Intellivon builds these systems for hospitals and RCM technology companies, and the decisions in this post come from that production experience. This blog post covers ML model architecture, payer-specific training data requirements, EHR and EDI 835 integration, HIPAA compliance engineering, phased development costs, and a build-versus-buy framework.

What AI Denial Prediction Software Does Inside Revenue Workflows
Custom AI denial prediction software provides hospitals with an automated, pre-submission risk layer.
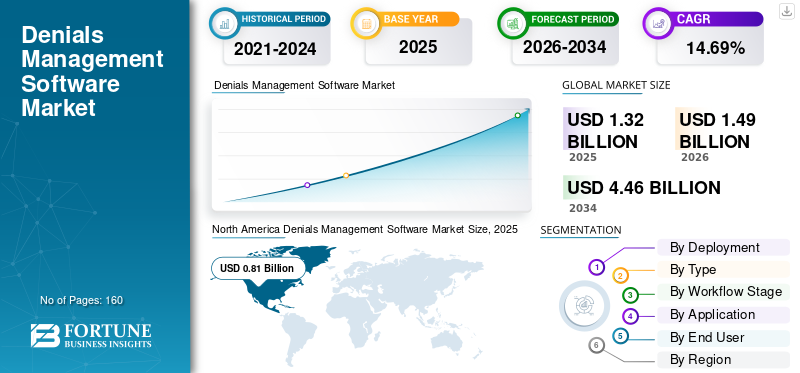
The denials management software market is expanding quickly as providers focus on reducing revenue leakage. Valued at USD 1.32 billion in 2025, the market is projected to reach USD 4.46 billion by 2034, growing at a 14.69% CAGR. North America led the market in 2025 with a 61.36% share.
Instead of simply cataloging rejections after they happen, this machine learning system evaluates the distinct data relationships within a claim to catch errors before submission.
Understanding the difference between tracking, management, and prediction is essential for revenue cycle technology leaders.
- Denial Tracking: This is a retrospective process that logs and categorizes claim rejections using standard Claim Adjustment Reason Codes after the remittance file arrives.
- Denial Management: This is a reactive operational workflow where hospital billing staff modify, appeal, and resubmit claims that have already been rejected by payers.
- Denial Prediction: This is a proactive software layer that sits between the billing system and the clearinghouse to stop rejections from occurring in the first place.
This predictive engine operates directly within the core stages of the revenue cycle. It ingests data from patient registration, eligibility verification, medical coding, and charge capture. The system scores the claim before the final claim scrubbing step.
This specific positioning allows hospitals to maximize their first-pass acceptance rate, which is the percentage of claims cleared on the very first submission. Catching errors early directly reduces avoidable denials, protecting net revenue and dropping the average number of days in accounts receivable.
Six Operational Buckets
The machine learning models within the platform classify risks into six main operational buckets:
- Medical Necessity Denial: The system identifies discrepancies where the documented clinical diagnosis code does not align with the specific procedural code according to national coverage rules.
- Coding-Related Denial: The engine catches invalid modifiers, unbundled procedures, or outdated codes that violate updated coding guidelines.
- Eligibility Denial: The software cross-references benefit details to flag instances where the patient’s plan coverage was inactive at the time of service.
- Prior Authorization Denial: The model detects when a specific procedure code requires an approved authorization number that is missing or incorrect.
- Timely Filing Denial: The system calculates the exact difference between the date of service and the current date to alert billers before a payer deadline passes.
- Documentation-Related Denial: Natural language processing models scan clinical charts to ensure that the required text support exists before the bill goes out.
Once the system’s role is clear, the next question is why hospitals build it instead of buying another generic denial dashboard.
Why Hospitals Build AI Denial Prediction Software Instead Of Denial Trackers
Hospitals build custom AI denial prediction software because generic tools cannot capture the unique data relationships within their local payer contracts, clinical workflows, and historical claim outcomes.
Custom development allows health systems to inject predictive intelligence directly into the pre-submission phase to prevent revenue leakage before it occurs.
A standard retrospective dashboard merely reports past financial losses rather than preventing future ones.
- Payer-Specific Variability: Insurance providers use different adjudication rules that change without public notice. Custom machine learning models map these local patterns by training on a hospital’s specific historical data.
- Specialty-Specific Nuances: High-margin service lines like oncology or orthopedics involve complex clinical documentation and strict prior authorization rules that standard software fails to validate.
- Logic Control: Product leaders need full ownership over their prediction logic so they can update training data as soon as an insurance contract changes.
Marketplace plan denial rates vary widely by individual insurer and geographic state, which makes localized, payer-specific analysis essential for survival.
For a deeper breakdown of the full denial lifecycle, see our guide on how to build an AI claims denial management platform.
The choice between purchasing a vendor tool or building a proprietary platform depends on your operational scale and long-term business goals.
1. Low Customization Needs in Standard Environments
Vendor denial tracking tools work well for smaller healthcare operations that do not experience complex contract rules or varied workflow routing needs across separate hospital locations. These tools provide a quick path to basic dashboard tracking and standard out-of-the-box reporting.
- Standard Outpatient Workflows: Vendor tools handle routine, high-volume outpatient services where medical necessity rules remain steady and predictable over long periods.
- Smaller Claim Volume: These tools suit organizations that lack the massive historical datasets required to train accurate custom deep learning models.
- Limited Engineering Capacity: Choosing a vendor tool protects small IT teams from the ongoing demands of data pipeline management and model optimization.
2. Complex Multi-Facility Infrastructures
Multi-facility health systems build custom software to aggregate data across multiple legacy EHR systems. This unified data layer gives leadership a single, accurate view of pre-submission risk across the entire enterprise.
- System Integration: Custom builds pull data from disparate billing platforms, resolving software conflicts that native vendor tools cannot handle.
- Data Aggregation: Centralizing historical claims allows data science teams to find hidden patterns that cause systemic rejections across facilities.
- Workflow Routing: High-risk claims are directed to specific regional billing experts based on the type of error detected.
3. High Denial Volume and Pattern Recognition
Organizations with high claim volumes build proprietary platforms to turn their massive data stores into a financial advantage. Large datasets allow engineering teams to train deep learning models that spot tiny, expensive patterns in claim rejections.
- Model Accuracy: High volume provides the millions of data points needed to minimize false positives in risk scoring.
- Pattern Detection: Custom algorithms find non-obvious correlations between specific provider groups, procedure codes, and denial reasons.
- Leakage Prevention: Catching repetitive, high-volume errors early protects the hospital from compounding cash flow delays.
4. Proprietary Denial Risk Scoring and Product Autonomy
Technology leaders and revenue cycle management software companies build custom systems to secure complete ownership over their intellectual property. Creating a unique risk-scoring algorithm builds long-term asset value and removes vendor lock-in.
- IP Ownership: Building custom code ensures that your predictive models remain a core proprietary asset of your business.
- Product Flexibility: Product managers can modify the user interface and feature set to match internal priorities exactly.
- Strategic Control: The organization controls its own software update roadmap without waiting for external vendor patches.
The build decision becomes easier when stakeholders understand the exact feature set needed.
Core Features Of AI Denial Prediction Software
An enterprise AI denial prediction software platform must provide direct preventative controls rather than basic visual data dashboards. A fully functional system allows health systems to isolate claim-level errors, interpret model decisions, track insurance behavior variations, and calculate exact financial risk before submission.
The scale of this issue is immense, with research showing that roughly $262 billion in annual healthcare claims face initial rejections from insurance providers.
Features only work when the underlying architecture connects clinical, billing, payer, and remittance data correctly.
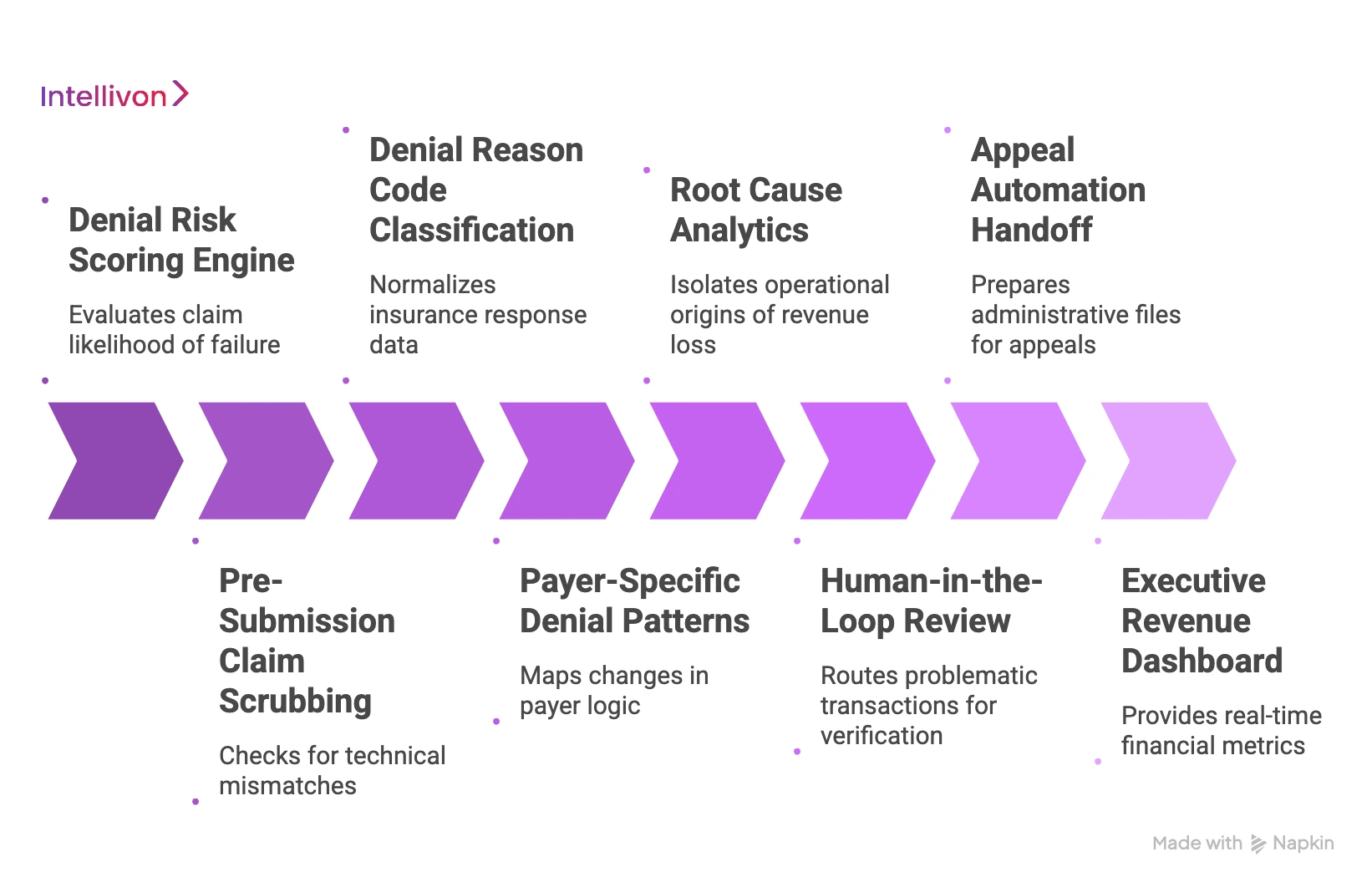
1. Denial Risk Scoring Engine
The scoring engine evaluates every raw claim file to determine its likelihood of failure before the data is transmitted over the network. It outputs a standardized risk profile that drives downstream queue prioritization.
- Claim-Level Risk Score: The model outputs a definitive percentage index that represents the mathematical probability of a rejection.
- Risk Category Assignment: The platform tags the file with its primary failure driver, such as eligibility or prior authorization anomalies.
- Probability Band Grouping: Claims are sorted into high, medium, or low risk tiers to manage manual review velocity.
- Revenue Exposure Calculation: The engine multiplies the risk percentage by the total dollar value of the claim to isolate high-value vulnerabilities.
2. Pre-Submission Claim Scrubbing
This module subjects the active claim data to an exhaustive programmatic inspection to catch technical mismatches before submission. It combines clinical data models with direct insurance guidelines.
- Advanced Coding Checks: The system verifies that all Current Procedural Terminology (CPT) tokens align accurately with documented International Classification of Diseases (ICD-10) diagnosis labels.
- Real-Time Eligibility Validation: The software pings payer portals to confirm the patient has active policy coverage for the listed treatment date.
- Authorization Mismatch Detection: The engine cross-references clinical service details with saved authorization documents to spot missing or invalid tracking numbers.
- Payer-Specific Rule Enforcement: The algorithm checks the claim against unique contract logic that dictates distinct billing rules for individual insurance groups.
3. Denial Reason Code Classification
This component normalizes messy incoming insurance response data into standardized structural categories for precise analysis. It translates raw data strings into clear, actionable data definitions.
- EDI 835 Remittance Mapping: The pipeline ingests and decodes raw Electronic Data Interchange (EDI) 835 files to capture exact Claim Adjustment Reason Codes.
- Related Cause Grouping: The application aggregates disparate code strings into macro-level functional buckets to uncover systemic billing issues.
- Preventability Assessment Analysis: The model separates completely avoidable administrative mistakes from structural, non-preventable clinical coverage limits.
4. Payer-Specific Denial Patterns
This analytical layer maps changes in how individual insurance corporations evaluate and process claims over time. It exposes hidden changes in automated payer logic.
- CPT and ICD-10 Tracking: The engine monitors combinations of procedural and diagnostic definitions to detect sudden spikes in specific rejection types.
- Modifier and Specialty Auditing: The platform tracks how modifiers are processed across distinct clinical specialties to prevent repetitive compliance errors.
- Location and Status Monitoring: The database aggregates claim outcomes across different facilities and authorization states to pinpoint localized workflow bottlenecks.
5. Root Cause Analytics
This system isolates the precise operational origins of revenue loss across your corporate infrastructure. It transforms historical data into specific, targeted management updates.
- Departmental Breakdown Views: The platform tracks rejection trends across distinct clinical departments to isolate where technical training is needed.
- Payer and Code Family Tracking: Leadership can view failure rates grouped by specific commercial insurers and related code categories.
- Provider and Claim Age Monitoring: The analytics engine highlights specific clinical teams generating errors and tracks how claim age impacts ultimate recovery rates.
6. Human-in-the-Loop Review
This module routes problematic transactions to internal specialists for verification before any data leaves the local network environment. It maintains data safety while improving automation accuracy.
- Intelligent Exception Routing: Claims that show high risk scores or low model confidence scores automatically move to specialized manual queues.
- Staff Feedback Capture: The user interface records every correction made by a human reviewer to gather training data for the model.
- Retraining Data Generation: Saved manual corrections are converted into structured training tokens to update future machine learning cycles.
7. Appeal Automation Handoff
When a rejection does slip through, this feature prepares the necessary administrative files to speed up the recovery process. It connects pre-submission analytics directly to backend recovery workflows.
- Documentation Collection Triggers: The software scans electronic health record systems to compile the clinical notes required for an official appeal.
- Appeal Packet Suggestions: The platform builds structured templates that match the specific documentation rules preferred by the target payer.
- Recovery Outcome Tracking: The engine logs completed appeal paths to determine which clinical arguments yield the highest collection success.
8. Executive Revenue Dashboard
This management screen provides revenue cycle leaders with real-time financial metrics across the entire enterprise network. It monitors long-term financial health and operational performance.
- Denial Rate Trends: The screen charts the overall percentage of rejected transactions across different operational timelines.
- First-Pass Acceptance Rate Monitoring: Managers can track the precise percentage of claims that successfully pass payer boundaries on the first attempt.
- Net Revenue Impact Tracking: The system calculates the exact cash volume protected by the pre-submission software layer to demonstrate concrete return on investment.
These interconnected software features must operate as a unified platform to effectively secure a hospital network’s revenue streams. If any individual module fails to sync with your broader billing infrastructure, high-risk claims will bypass validation and trigger preventable financial losses.
AI Denial Prediction Software Architecture
An enterprise-grade AI denial prediction software architecture must combine real-time data ingestion, structural normalization, feature engineering, and model inference into a unified platform. Building a disconnected prediction engine that cannot communicate directly with your daily billing queues creates operational silos and limits the financial impact of your machine learning models.
A modern system must use a layered data pipeline to transform complex healthcare transactions into clean mathematical variables that drive instant risk calculations.
To maintain clean transaction pipelines, engineering teams must build a clear separation between raw data collection and downstream scoring models.
- System Decoupling: Isolating data extraction from model execution ensures that heavy machine learning calculations do not lag the primary hospital billing software.
- Decentralized Event Streaming: Using asynchronous messaging frameworks allows the platform to process millions of concurrent claim updates without data loss.
- Governed Pipeline Access: Restricting model entry via strict identity protocols ensures that patient data stays secure across every microservice layer.
AI Architecture and Tech Stack
The table below breaks down the technical stack and operational roles for each architecture layer inside a hospital network.
| Architecture Layer | Operational Responsibility | Recommended Technology Stack |
| Data Ingestion | Extracts raw, unstructured encounters and structural transaction data from live health environments. | Apache Kafka, AWS Kinesis, Debezium (CDC) |
| Data Normalization | Converts disparate patient, provider, and clinical code definitions into unified database schemas. | Apache Spark, Python (Pandas), PostgreSQL |
| Feature Store | Manages historical payer trends, claim ages, and validation metrics for immediate model retrieval. | Feast, Redis, AWS SageMaker Feature Store |
| Model Layer | Executes risk probability algorithms, cause classifiers, and dynamic appeal predictive logic. | TensorFlow, PyTorch, XGBoost, MLflow |
| Workflow Layer | Routes risky items directly into internal work queues based on the calculated confidence score. | Camunda, Apache Airflow, Custom React UI |
| Governance Layer | Tracks data compliance, verifies model drift boundaries, and retains administrative system changes. | AWS CloudTrail, OpenSearch, Great Expectations |
The HIPAA Security Rule mandates that covered entities implement strict administrative, physical, and technical safeguards to preserve the absolute confidentiality and integrity of electronic protected health information.
For a broader revenue-cycle architecture context, see our guide on AI revenue cycle management software development.
AI Models Behind A Machine Learning Denial Prediction System
An enterprise machine learning denial prediction system must combine deterministic rules engines with statistical machine learning models to maximize tracking accuracy. Healthcare denials emerge from a mix of hard contractual constraints and soft, evolving insurance behaviors.
Combining a logic-based rules processing layer with dynamic gradient-boosted classifiers allows engineering teams to catch explicit coding violations while simultaneously projecting hidden risk patterns across multiple plan types.
To deploy a highly accurate prediction network, engineers must build dedicated pathways for both structured transaction data and unstructured medical text.
1. Supervised Classification Models
Supervised machine learning classifiers serve as the foundational predictive layer by calculating the overall probability of a claim passing or failing. These networks require a dual-labeled dataset containing millions of historically approved and denied transactions to establish baseline accuracy.
- Binary Probability Outputs: The system outputs a clean mathematical confidence percentage between 0% and 100% for each outbound billing file.
- Historical Risk Mapping: The algorithm uses past financial outcomes to identify non-obvious data relationships that correlate heavily with structural rejections.
- Automated Queue Flagging: Claims that exceed a specific historical risk threshold are instantly extracted from the automated billing stream.
2. Gradient Boosting and Tree-Based Models
Tree-based architectures like XGBoost or LightGBM process structured, tabular claim files to balance computational speed with high accuracy. These models excel at handling complex, categorical healthcare data fields without requiring lengthy pre-processing steps.
- Tabular Data Excellence: The system efficiently processes dense matrix inputs, including thousands of unique provider, facility, and insurance carrier identification codes.
- Inherent Feature Importance: Built-in calculation matrices allow engineering teams to rank which specific variables have the highest mathematical impact on denial risk.
- High Model Explainability: The tree structure gives revenue cycle leaders a transparent, auditable breakdown of how the machine learning model arrived at an individual risk rating.
3. Natural Language Processing Models
Natural Language Processing models analyze unstructured clinical documents to locate critical information gaps that standard billing lines cannot show. This language parsing layer converts free-text medical notes into structured data features.
- Clinical Chart Auditing: Specialized language models scan physician notes and discharge summaries to verify that the text actively supports the applied billing codes.
- Payer Document Parsing: The software reads messy physical denial letters and incoming correspondence to extract specific regulatory arguments.
- Unstructured Gap Alerts: Staff receive instant, clear notifications when an insurance requirement is mentioned in a text field but missing from the final claim forms.
4. Denial Reason Code Classification Systems
This specialized classification layer uses historical transaction data to group disparate, messy insurance carrier responses into standard operational categories. It standardizes thousands of separate Claim Adjustment Reason Codes into clean data definitions.
- Remittance Data Normalization: The algorithm ingests raw EDI 835 response text and accurately maps inconsistent insurance notes to internal system categories.
- Preventability Assessment Analysis: The model automatically separates basic clerical administrative errors from deeper, systemic clinical coverage limitations.
- Root-Cause Trend Isolation: Grouping related rejection codes allows management to quickly isolate which internal workflows are driving localized revenue loss.
5. Appeal Success Prediction Engines
This predictive component scores active rejections by estimating the mathematical probability of overturning an insurance decision through an official appeal. It ensures that recovery teams focus their finite labor hours on high-value, winnable disputes.
- Recovery Probability Scoring: The tool outputs a win-rate percentage based on historical recovery patterns for the exact code and payer combination.
- Operational Cost Balance: The platform contrasts the calculated recovery probability against the administrative cost of processing the manual dispute.
- Automated Strategy Selection: High-probability claims are fast-tracked into automated appeal pipelines, while low-scoring files bypass manual handling completely.
6. Hybrid Deterministic Rules Engines
A hybrid deterministic rules layer executes explicit, non-statistical billing logic before data ever reaches the advanced machine learning modules. This protects computational resources by handling static boundary checks first.
- Static Compliance Validation: The engine automatically blocks claims that violate hard regulatory deadlines or national coverage determinations.
- Authorization Requirement Tracking: The software instantly checks if a specific procedural code requires an approved pre-certification token.
- Immediate Local Gatekeeping: Administrative teams can manually add new contractual rules immediately after completing a new negotiation with an insurance carrier.
These distinct statistical models and deterministic rules engines must operate as an interconnected evaluation system to protect a hospital’s cash flow.
If your tabular classifiers fail to communicate with your natural language processing pipelines, complex documentation gaps will bypass your pre-submission filters and trigger immediate rejections.
What Data Is Needed To Build AI Denial Prediction Software?
You cannot build accurate AI denial prediction software without the right mix of past billing data, insurance responses, and clinical records. Machine learning models need to study your historical successes and failures to spot the patterns that lead to rejections. If you feed the system incomplete or messy data, it will give you incorrect risk scores that slow down your billing team.
Before you start writing code, you must collect and clean three distinct types of data.
- The Inbound Claim File (What You Sent): The exact codes, costs, and provider details you submitted to the insurance company.
- The Outbound Remittance File (What They Paid): The dollar amounts the insurance company actually paid, along with their official reasons for any rejections.
- The Patient Clinical Chart (The Medical Proof): The unstructured notes and doctor descriptions that prove the treatment was necessary.
1. Historical Billing and Submission Files
This dataset tells the AI model exactly what your hospital billed for, who provided the care, and where the service took place. It forms the foundation of every machine learning feature you build.
- EDI 837 Electronic Claim Files: These standard digital files contain the structural breakdown of the bill before it goes to the insurance company.
- Payer Identification Numbers: Unique codes that identify the specific insurance company and the exact type of plan the patient uses.
- Clinical Code Strings: Complete lists of the CPT procedure codes, ICD-10 diagnosis labels, and billing modifiers applied to the bill.
- Provider and Location Specifics: Data points showing which doctor performed the service and whether it happened in an operating room, clinic, or ER.
2. Insurance Response and Remittance Files
This data shows the machine learning model’s final outcome of the transaction. It acts as the “answer key” that the system uses to learn what a rejection looks like.
- EDI 835 Remittance Documents: The electronic paperwork that shows exactly how much money the insurance company paid out.
- Official Denial Reason Codes: Standardized numeric codes that explain the exact administrative or clinical reason for the rejection.
- Payment and Processing Timelines: Timestamps that show how many days passed between your submission date and the payer’s final response.
- Payer Adjudication Patterns: Hidden historical records that show how strictly a specific insurer enforces its local billing rules.
3. Operational Verification and Approval Data
This data layer tells the system whether your front-desk staff completed the necessary verification steps before the patient received care. It helps catch administrative errors early.
- Real-Time Eligibility Logs: Digital verification records that prove the patient’s insurance policy was active on the date of service.
- Prior Authorization Tracking Status: System flags that confirm whether an approval number was secured from the insurer for a specific procedure.
- Pre-Certification Token Matches: Data fields that link the insurance company’s approval document directly to the electronic bill.
- Front-End Verification Timestamps: Records that track how close to the appointment date your staff verified the patient’s benefits.
4. Clinical Context and Text Documentation Markers
This information provides the deep medical details that insurance companies demand to prove a treatment was necessary. It converts complex medical descriptions into data that the AI can read.
- Unstructured Physician Notes: Free-text descriptions written by doctors detailing the patient’s symptoms, physical exams, and clinical history.
- Electronic Health Record Markers: System checkmarks that show whether mandatory clinical forms were fully completed.
- Specialty Diagnostics Reports: Lab values, imaging summaries, and pathology findings that justify high-cost medical treatments.
- Document Completeness Scores: Numerical ratings that measure how much required paperwork is present in the patient’s file before billing.
5. Historic Appeals and Value Recovery Outcomes
This dataset tracks what happened when your billing team tried to fight a rejection in the past. It teaches the AI which claims are worth disputing.
- Historical Appeal Packages: Copies of the clinical arguments, formal letters, and medical charts sent to contest an insurance rejection.
- Payer Appeal Overturn Rates: Clean records showing which specific insurance companies are most likely to reverse a denial upon review.
- Labor Tracking Metrics: Data showing how many staff hours were spent preparing and monitoring an individual dispute.
- Net Recovery Cash Volumes: The exact amount of money successfully collected after deducting the administrative cost of the appeal.
Your predictive software will fail if these distinct data streams are not properly linked within a single database. If your engineering team cannot feed clean historical transaction records into your model training pipelines, your software will calculate incorrect risk scores and miss critical billing errors.
How To Build an AI Denial Prediction Software
Building custom AI denial prediction software requires your engineering team to establish a strict, step-by-step production pipeline. Instead, product leaders must design a system that ingests raw clinical events, extracts high-value behavioral features, runs real-time risk calculations, and pushes alerts directly into existing hospital work queues.
Executing this development plan requires a disciplined focus on data engineering, systems integration, and human-in-the-loop workflow design.
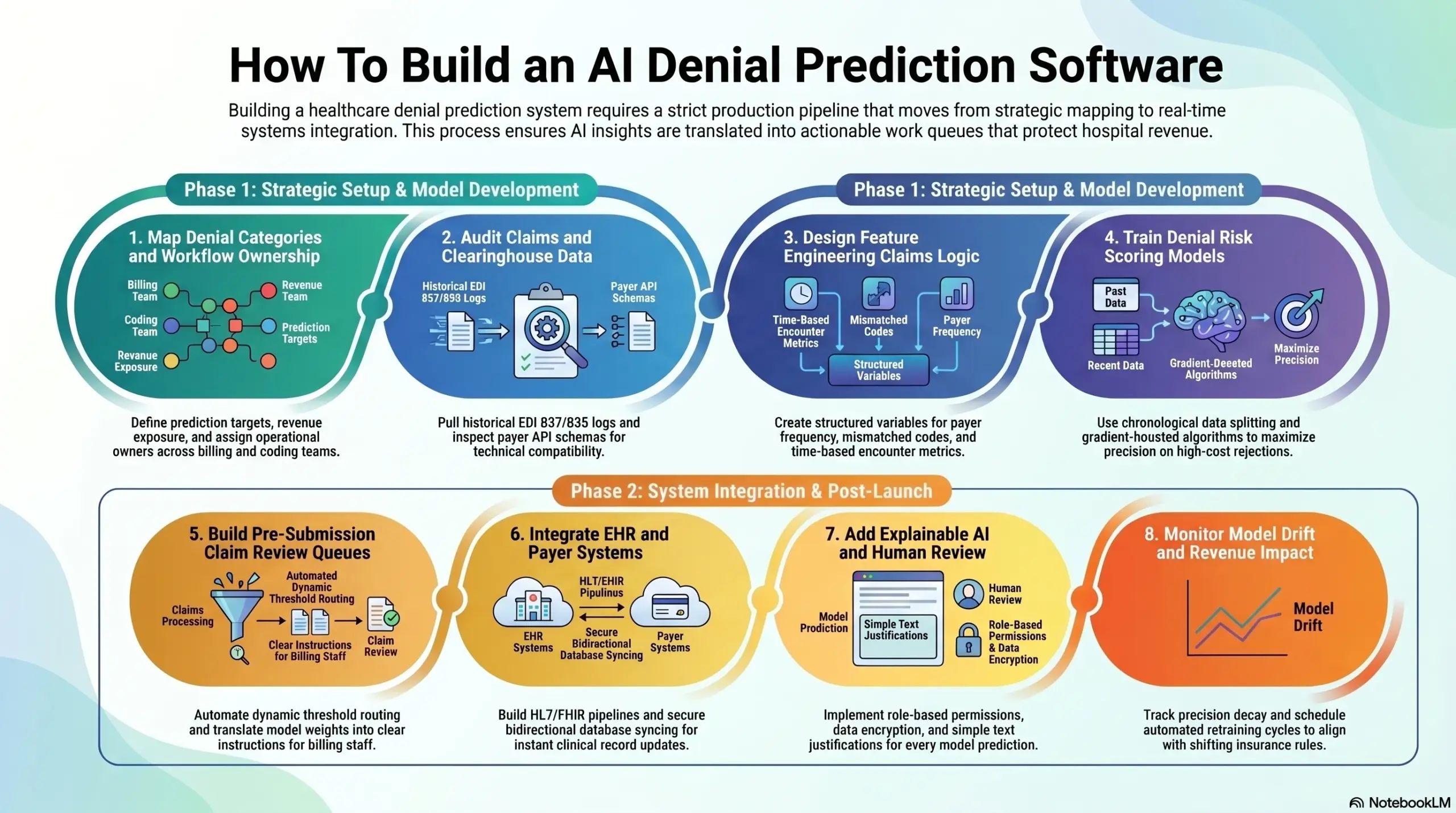
Step 1: Map Denial Categories And Workflow Ownership
Start by mapping denial types, revenue exposure, and workflow owners before writing code. This defines what the platform predicts, who acts on each alert, and which denial categories matter most. Without this step, the model may optimize for generic denial volume instead of the hospital’s actual revenue risk.
- Denial Taxonomy Structure: Group historical insurance rejections into clear operational buckets like eligibility mismatches or prior authorization gaps.
- Financial Exposure Sorting: Calculate the total dollar value at risk for each rejection type to ensure the software prioritizes high-value claims.
- Workflow Owner Matching: Assign distinct failure categories to specific operational leaders across your coding, billing, and front-desk registration teams.
What Goes Wrong: If you skip this initial scoping step, the AI platform will flag hundreds of low-value administrative claims, creating alert fatigue that causes staff to ignore the system.
Intellivon begins every project by conducting a deep workflow discovery phase and historical root-cause analysis to ensure the machine learning models focus on your highest financial liabilities. Once the target denial categories are clear, the data audit decides whether the model can learn anything useful.
Step 2: Audit Claims And Clearinghouse Data
Audit the available data before model design. AI denial risk scoring software builds decisions that depend on whether claims, remittance, payer, authorization, eligibility, and EHR data are complete enough to train reliable models. Missing 835 remittance history or inconsistent payer mapping weakens every prediction downstream.
- EDI 837 Data Extraction: Pull historical outbound claim logs to analyze every procedural code and billing modifier that your network previously submitted.
- EDI 835 Outcome Assembly: Gather matching inbound insurance response files to establish the clear “pay” or “deny” labels needed for model training.
- Payer API Schema Analysis: Inspect the documentation and response structures of active clearinghouse feeds to ensure real-time technical compatibility.
What Goes Wrong: Skipping the data readiness audit results in severe data gaps that train the models on incorrect assumptions, causing the platform to output inaccurate risk scores in production.
Intellivon runs rigorous data quality checks, label validation scans, and integration feasibility audits before writing any machine learning code to ensure your underlying databases are production-ready. After data quality is confirmed, the next step is feature engineering.
Step 3: Design Feature Engineering Claims Logic
The model needs structured variables that explain why claims fail, such as missing authorization, payer-specific modifier behavior, eligibility mismatch, diagnosis-procedure inconsistency, or prior denial history. Strong features often matter more than model complexity.
- Payer Frequency Calculations: Compute real-time rolling rejection metrics for individual insurance networks across specific code groups.
- Mismatched Code Flagging: Create automated indicators that catch instances where an applied CPT code does not match the primary diagnostic code.
- Time-Based Variable Building: Measure the exact days elapsed between the initial patient encounter and the final claim creation date.
What Goes Wrong: Without intentional feature engineering, your machine learning models turn into a black box that spits out random risk numbers without providing clear context to your billing team.
Intellivon combines data science expertise with deep revenue cycle context to build expressive, high-value data features that directly expose the hidden operational reasons behind claim rejections. The feature store then feeds the first model training cycle.
Step 4: Train Denial Risk Scoring Models
Train the first model on historical claim outcomes, then validate it against recent claims that were not used during training. The model must correctly identify high-risk, high-value claims early enough for staff to fix them before submission.
- Chronological Data Splitting: Separate your training and testing datasets by specific historical dates to ensure your models are validated against realistic timeline progressions.
- Supervised Model Optimization: Run gradient-boosted tree algorithms to maximize your precision and recall scores on high-cost rejection classes.
- Probability Calibration Verification: Adjust model outputs to guarantee that a calculated 80% risk score corresponds to an actual 80% rejection rate in real-world environments.
What Goes Wrong: Rushing through the model training phase leads to an overfitted system that performs perfectly on paper but fails to catch real-world contract updates or sudden insurance policy shifts.
Intellivon designs its model validation metrics around your actual financial impact and net recovery thresholds rather than chasing vanity accuracy statistics that fail to protect revenue. After the model predicts risk, the system must route the claim to the right human workflow.
Step 5: Build Pre-Submission Claim Review Queues
Prediction only creates value when it changes the claim before submission. Build review queues that route high-risk claims to billing, coding, eligibility, authorization, or documentation teams based on the predicted reason. This turns AI output into daily operational action.
- Dynamic Threshold Routing: Move outbound billing files automatically into manual inspection queues the second a claim crosses your designated risk limit.
- Automated Action Item Generation: Translate cryptic model feature weights into clear instructions, telling billers exactly what text or code needs to be verified.
- System Override Tracking: Record every instance where a human billing expert overrides a software warning to capture fresh training signals for future model updates.
What Goes Wrong: If you fail to build direct integration queues, your expensive predictive models end up as a passive reporting screen that staff ignore because it complicates their workday.
Intellivon embeds automated risk scoring directly into active administrative work queues, allowing your revenue cycle staff to review, fix, and clear problematic claims without logging into a separate software program. Workflow value depends on tight integration with hospital systems.
Step 6: Integrate EHR And Payer Systems
Hospital denial prediction platform development requires integration with the systems where claims are created, reviewed, submitted, adjudicated, and paid. The key integrations are EHR, practice management, billing software, clearinghouses, payer APIs, eligibility systems, authorization tools, and remittance feeds.
- FHIR and HL7 Data Pipelines: Create secure network listeners to pull live clinical updates and patient charts directly from core electronic health records.
- Secure File Transfer Automation: Build automated data tasks to securely upload and download transaction files from external insurance clearinghouses.
- Bidirectional Database Syncing: Ensure that corrections made within the AI prediction interface sync back to your primary billing software instantly.
What Goes Wrong: Skipping deep systems integration forces your administrative employees to manually download, copy, and upload claim spreadsheets all day, which slows down operations and introduces human entry errors.
Intellivon engineers custom API connectors and data ingestion streams that link directly with legacy hospital platforms, keeping data synchronized without disrupting daily clinical workflows. Once integrations move PHI, compliance and explainability become non-negotiable.
Step 7: Add Explainable AI And Human Review
Explainability and HIPAA controls must be part of the software design, not a final checklist. Every denial prediction should show the drivers behind the score, the data used, the model version, the staff action, and the final decision. This protects adoption and audit readiness.
- Local Data Encryption Mandates: Apply advanced cryptographic protections to all patient health information, keeping data fully secure both during transit and while sitting in databases.
- Role-Based Permission Controls: Restrict software screens so that employees can only view the specific patient records required to perform their daily billing tasks.
- Model Decision Explanations: Display simple text justifications on screen so human operators can understand the exact data points driving a high risk rating.
What Goes Wrong: If your software operates as a mysterious black box with no clear tracking trail, your compliance department will block it from production, and your billers will refuse to trust its alerts.
Intellivon integrates comprehensive system logs, data privacy protections, and clear model explanations directly into the platform architecture from day one. After launch, the model needs monitoring because payer behavior changes.
Step 8: Monitor Model Drift And Revenue Impact
Monitor the system after launch because denial prediction accuracy changes when payer rules, coding policies, documentation habits, and authorization requirements shift. Model drift denial prediction controls help the team see when predictions weaken and when retraining is needed.
- Model Quality Monitoring: Track live precision decay metrics to alert engineers the moment a model’s prediction accuracy drops below baseline levels.
- First-Pass Acceptance Auditing: Chart the long-term trends of your clean claim submissions to prove the concrete financial return on your software investment.
- Automated Retraining Cycles: Schedule regular database updates to refresh your models with recent transaction logs, keeping them aligned with the latest insurance rules.
What Goes Wrong: Failing to build post-launch drift monitors means your software will quietly lose its predictive power over time as insurance companies alter their adjudication rules without telling you.
Intellivon incorporates automated model monitoring and performance dashboards as a core element of our software builds, ensuring your system maintains peak accuracy as insurance environments evolve. These integrated development steps are what allow a health system to maintain total financial control while keeping data safe.
These distinct statistical steps and development phases must operate as an interconnected execution pipeline to properly secure a hospital’s cash flow. If your core data ingestion layers fail to sync with downstream work queues, high-risk billing errors will slip through your infrastructure and trigger immediate rejections from external payers.
HIPAA Compliant Denial Prediction Software Controls
Building HIPAA-compliant denial prediction software requires implementing strict data privacy protections across your entire machine learning infrastructure. Because pre-submission risk engines process sensitive patient health information and financial transaction logs, security cannot exist as a final software patch.
Instead, development teams must embed precise administrative, technical, and physical safeguards into every microservice layer to guarantee complete data safety.
Failing to establish a protected network footprint exposes your health system to immediate regulatory penalties and expensive security vulnerabilities.
- Zero-Trust System Design: Restricting background network access ensures that data pipelines can only interact with authorized, verified service accounts.
- Encrypted Processing Zones: Creating separate data microservices prevents decrypted medical information from leaking into public system logs.
- Immutable Transaction Ledgers: Using unalterable database structures ensures that your security teams can track every instance of data access.
1. Administrative and Infrastructure Protections
These foundational administrative controls govern how your organization manages partner agreements, isolates development work, and responds to data incidents.
- Vendor BAA Execution Requirements: You must secure official Business Associate Agreements with every cloud infrastructure supplier and external database tool used in your stack.
- Production and Training Isolation: Engineering teams must maintain completely separate server environments to ensure that live patient records are never used during testing.
- Comprehensive Incident Response Frameworks: The system must include automated monitoring tools that flag and isolate unusual data download patterns the moment they occur.
- Data Retention and Deletion Schedules: The underlying database must run automated script tasks that completely scrub old patient records according to local state laws.
2. Technical Data and Access Controls
These software mechanics restrict who can see patient data, encrypt information as it moves across networks, and log every automated system decision.
- Granular Role-Based Permissions (RBAC): Software screens must restrict data visibility so that users can only view the specific billing fields required for their jobs.
- Mandatory Multi-Factor Authentication (MFA): Every employee login attempt must pass a second verification layer before accessing the central patient dashboard.
- Complete System Audit Logging: The database must record an unalterable history trail tracking exactly who viewed, edited, or exported a claim file.
- In-Transit and At-Rest Encryption: All data fields must use AES-256 encryption keys while sitting in storage tables, and use TLS 1.3 network channels during transfer.
3. Machine Learning and Pipeline Safeguards
These specific data science guardrails protect patient identity fields during model verification cycles and restrict model execution access.
- Automated PHI Data Inventories: Programmatic scrapers must scan incoming claim files to identify and isolate explicit identifiers like names, social security numbers, and birth dates.
- Minimum Necessary Access Limits: The machine learning pipelines must only ingest the specific clinical attributes needed to run a risk prediction, stripping out all extra data.
- Secure API Endpoint Formats: All model entryways must run behind strict authentication walls that reject unauthorized external data requests.
- De-Identification for Model Testing: Engineering teams must use automated masking scripts to substitute real patient identifiers with synthetic placeholders during staging runs.
- Model Access History Logs: The platform must save precise logs detailing every instance where an algorithm processed a specific claim record.
- Human Approval Interface Gates: The software must block the system from executing final financial decisions without explicit review from a human billing specialist.
These administrative rules and technical data safeguards must operate as a single, unified compliance envelope around your machine learning models.
If your engineering team fails to integrate strict logging controls into your daily billing interfaces, unauthorized data access can occur unnoticed, leading to immediate regulatory audit failures.
AI Denial Prediction Software Development Cost For
AI denial prediction software development usually costs $90,000–$320,000+, depending on data readiness, model scope, integrations, compliance depth, and deployment scale.
A focused MVP costs less because it usually includes denial risk scoring, basic dashboards, limited payer logic, and one or two core integrations. A hospital-grade platform costs more because it needs richer claims data, EDI 835 remittance mapping, denial reason code classification, explainable AI, user roles, audit logs, and live revenue-cycle workflows.
The largest cost drivers are usually data preparation, payer-specific feature engineering, EHR integration, clearinghouse connectivity, and model validation. These areas decide whether the platform becomes a useful denial prevention system or just another reporting layer.
Cost Breakdown By Development Phase
| Development Phase | Estimated Cost | What It Covers |
| Discovery, denial workflow mapping, and scope planning | $8,000–$20,000 | Denial categories, payer mix, workflow ownership, MVP scope, ROI baseline |
| Data audit and claims dataset preparation | $12,000–$35,000 | Claims history, EDI 835 remittance, denial labels, payer mapping, data quality checks |
| UX/UI for dashboards and review queues | $10,000–$28,000 | Risk queues, claim review screens, executive dashboards, and user roles |
| Data pipeline and feature store development | $20,000–$60,000 | ETL, normalization, feature engineering, data warehouse, model-ready datasets |
| ML model development and validation | $25,000–$85,000 | Denial scoring, reason classification, calibration, evaluation, and explainability |
| EHR, RCM, payer, and clearinghouse integrations | $25,000–$95,000 | EHR, PMS, clearinghouse, payer APIs, 835/837, eligibility, claim status |
| HIPAA security and audit controls | $15,000–$45,000 | RBAC, encryption, audit logs, BAA-ready controls, PHI governance |
| QA, compliance testing, and UAT | $12,000–$35,000 | Workflow testing, model validation, integration testing, and user acceptance |
| Deployment, MLOps, and monitoring | $15,000–$50,000 | Cloud setup, CI/CD, model monitoring, drift alerts, dashboards |
Cost Tiers For AI Denial Prediction Software
- A focused MVP usually costs $90,000–$140,000. This version works best for hospitals or RCM teams that want to validate denial risk scoring on a limited dataset, test payer-specific patterns, and launch a small review workflow before expanding the system.
- A hospital-grade internal platform usually costs $140,000–$240,000. This version includes stronger EHR and clearinghouse integration, structured work queues, denial reason code classification, HIPAA audit trails, explainable predictions, and dashboards for revenue-cycle leaders.
- A multi-facility or RCM SaaS platform usually costs $240,000–$320,000+. This build supports multiple facilities, payer groups, client accounts, user roles, advanced analytics, model monitoring, integration layers, and commercial-grade deployment controls.
Ongoing Maintenance Cost
Plan for 18%–30% of the initial build cost per year for ongoing maintenance. This covers payer-rule updates, model retraining, compliance reviews, security patches, integration maintenance, MLOps monitoring, and new workflow improvements.
For example, a $180,000 denial prediction platform may require $32,000–$54,000 per year in maintenance. That budget keeps the system useful as payer behavior changes, denial reason codes shift, and claim workflows evolve.
Planning an AI denial prediction platform budget? Intellivon can help estimate the cost based on your payer mix, claim volume, EHR environment, clearinghouse setup, AI model scope, HIPAA controls, and launch timeline.
Conclusion
Building custom AI denial prediction software allows hospital systems to move past reactive financial logging and secure stable, predictable cash flows. This platform serves as a core revenue infrastructure layer that links historical claims, shifting insurance patterns, electronic health records, and active billing queues into a single protected environment.
Implementing these interconnected machine learning models allows product leaders to intercept transactional errors before data ever leaves their network, maximizing first-pass acceptance rates and minimizing avoidable cash losses.
Ultimately, AI denial prediction software works best when hospitals treat it as a production revenue-cycle system, not an experimental analytics project.
Build AI Denial Prediction Software With Intellivon
At Intellivon, we help hospitals, health systems, RCM companies, and healthcare SaaS teams build custom denial prediction platforms around real revenue-cycle operations.
Our approach covers product scope, architecture, ML model development, EHR and clearinghouse integration, compliance controls, and post-launch model monitoring.
A. Help You Define The Right Denial Prediction Scope
Not every hospital needs the same denial prediction system. Some teams need a focused MVP for pre-submission risk scoring. Others need a multi-facility platform with payer analytics, appeal prioritization, and executive revenue dashboards.
Intellivon helps define the right scope based on your claim volume, payer mix, denial categories, existing RCM workflow, and internal technology stack. This gives your team a clear roadmap before development begins.
B. Build AI Models Around Real Claims Data
Denial prediction depends on strong historical data. The platform needs approved claims, denied claims, EDI 835 remittance, denial reason codes, authorization status, eligibility records, coding data, and payer-specific patterns.
Intellivon designs the ML layer around these real revenue-cycle signals. This helps the system predict denial risk, classify likely denial causes, and explain why a claim needs review before submission.
C. Connect The Platform To Your Revenue Cycle Systems
A denial prediction platform only works if it fits into daily claim workflows. That means connecting with EHR, RCM, practice management, clearinghouse, payer, eligibility, authorization, and remittance systems.
Intellivon builds the integration layer, so denial risk scores, review queues, claim corrections, and analytics sit inside the workflow your teams already use. This helps reduce manual exports, duplicate checks, and disconnected reporting.
D. Make Denial Prediction Explainable And Compliant
Hospital teams need to understand why a claim has been flagged. Compliance teams also need audit trails, PHI safeguards, access controls, and clear user activity records.
Intellivon builds explainable AI controls, HIPAA-ready architecture, role-based access, audit logs, model versioning, and human review workflows into the platform. This makes the system easier to trust, review, and maintain.
Intellivon designs post-launch monitoring, so your team can see which payer patterns are changing, where the model needs retraining, and how much revenue the platform is helping protect.
Things To Know About AI Denial Prediction Software Development
Q1. How much does AI denial prediction software development cost?
A1. AI denial prediction software development usually costs $90,000–$320,000+. A focused MVP with basic risk scoring and dashboards may cost $90,000–$140,000, while a hospital-grade platform with EHR integration, 835/837 data, payer-specific models, HIPAA controls, and MLOps can reach $240,000–$320,000+. Annual maintenance usually adds 18%–30% of the initial build.
Q2. How long does it take to build AI denial prediction software hospitals can use?
A2. A usable MVP usually takes 3–5 months if the claims data is clean and integrations are limited. A production hospital platform usually takes 6–12 months because teams must prepare historical claims data, map denial reason codes, connect EHR and clearinghouse systems, validate ML models, and complete compliance testing. Multi-facility SaaS builds can take 12–18 months.
Q3. Can HIPAA-compliant denial prediction software use real claims data?
A3. Yes, HIPAA-compliant denial prediction software can use real claims data when PHI safeguards are built into the architecture. The system needs role-based access, encryption, audit logs, secure model training environments, data minimization, vendor BAAs, and strict access controls. For testing and experimentation, teams should use de-identified or limited datasets whenever possible.
Q4. What AI models are required to build AI denial risk scoring software?
A4. A strong AI denial risk scoring software build usually combines supervised classification models, denial reason code classifiers, NLP for documentation review, rules engines for deterministic payer edits, and explainability methods. Tree-based models often work well for structured claims data because they support clearer feature explanations. LLMs should support summaries and appeals, not make final billing decisions.
Q5. Which integrations matter most for hospital denial prediction platform development?
A5. The most important integrations are EHR, EMR, practice management, RCM software, clearinghouse connectivity, EDI 837 claims, EDI 835 remittance, eligibility checks, authorization systems, payer APIs, and claim status feeds. Without these integrations, the model may predict risk but fail to affect live claim workflows. Integration depth usually drives both cost and implementation timeline.