

Key Takeaways:
- LLMs improve AML compliance by retrieving approved case evidence and generating cited SAR draft narratives.
- RAG pipelines, structured outputs, private deployment, and hallucination testing are core production stack requirements.
- Role-based access, immutable audit logs, and GenAI governance controls protect SAR-confidential material throughout.
- Focused MVPs cost $60,000 to $120,000 while integrated production platforms reach $120,000 to $280,000.
- How Intellivon builds LLM workflows around reviewer authority, evidence traceability, and measurable compliance productivity gains.
AML investigators usually spend more time writing than investigating. This is because a single SAR narrative averages 3 to 4 hours to draft, therefore pulling time from actual case judgment. As a result, LLMs for AML compliance solve that problem at the source. They read transaction histories, summarize entity relationships, and produce draft SAR narratives in minutes. This means compliance becomes faster and more consistent, without adding headcount.
However, an LLM without regulatory grounding produces outputs that read well but fail examiner review. Without retrieval-augmented generation (RAG) anchored to FinCEN advisories, FFIEC manuals, and internal typology libraries, the model ends up hallucinating and produces inconsistent results. Institutions that build the RAG layer first report 40–80% reductions in SAR drafting time for Level 1 and Level 2 analysts. Consequently, narrative quality also holds under regulatory examination.
Intellivon has spent a decade building LLM compliance systems for financial institutions. Specifically, audit trails and explainability are built into the architecture from day one, and not added later. This blog post covers model selection, RAG design, hallucination controls, FFIEC model validation, and productivity benchmarks. By the end, you will have the framework and technical grounding to make that decision.

What Is an LLM-Run AML Investigation Platform?
An LLM-run AML investigation platform is a controlled software workspace that uses a large language model to gather approved evidence, summarize case context, and review customer files.
Consequently, it helps human analysts explain transaction patterns and draft Suspicious Activity Report (SAR) narratives for final approval. It supports the work after a system flags an alert, but it never replaces your core risk models or filing authority.
1. What the Platform Does
An LLM-run AML platform manages the tedious documentation that slows down human compliance teams during complex reviews. Therefore, it changes how analysts interact with unstructured data by turning disparate records into clear summaries.
Human investigators maintain full decision authority, while the AI operates strictly as an automated processing assistant.
| Platform Responsibility | What the LLM Does | What It Does Not Decide |
| Evidence retrieval | Finds permitted records, regulatory guidance, policies, and customer files. | Whether the observed activity is actually suspicious. |
| Investigation summarization | Produces a source-linked case chronology and explains transaction patterns. | Whether the case requires escalation to management. |
| Document interpretation | Extracts KYC, CDD, EDD, ownership, and adverse-media context. | Whether the customer should be approved or exited. |
| SAR narrative assistance | Structures facts, dates, amounts, and entities into an initial draft. | Whether a SAR should be filed or officially certified. |
This functional separation ensures that the software accelerates data collection and case narrative generation without overstepping regulatory boundaries. Because the system includes a mandatory human-in-the-loop LLM review, compliance officers can verify every single source document before submitting a final report.
Thus, the technology optimizes your existing workforce instead of replacing human judgment.
2. What Makes It Different From Transaction Monitoring
A transaction monitoring system flags suspicious account activity based on rigid rules, whereas an LLM financial crime investigation tool analyzes and summarizes the data after an alert triggers. Monitoring engines look for anomalies in raw data streams, but they cannot explain the underlying story.
An LLM platform reads the context, structures the evidence, and simplifies the review process.
| System Type | Core Technology | Primary Output | Regulatory Focus |
| Transaction Monitoring | Hardcoded rules, SQL queries, machine learning models. | Raw alerts and risk scores based on numerical thresholds. | Detection of anomalous activity patterns. |
| LLM Investigation Software | Generative AI, natural language processing, RAG pipelines. | Automated investigation summarization and written draft reports. | Documentation and narrative explanation of evidence. |
By maintaining this clear boundary, banks ensure that their automated detection models remain completely separate from their text-generation tools. Graph analytics or machine learning scores might expose network risks, but the LLM simply explains those findings in plain English This distinction prevents the platform from making unverified compliance decisions.
Why Should Banks Adopt LLMs to Improve AML Compliance?
Banks should adopt an LLM for AML compliance and FinCrime workflows because analysts spend significant effort collecting, reading, organizing, and explaining evidence before they can make a compliance judgment. Therefore, an evidence-grounded system reduces that preparation burden, improves narrative consistency, and supports faster policy retrieval.
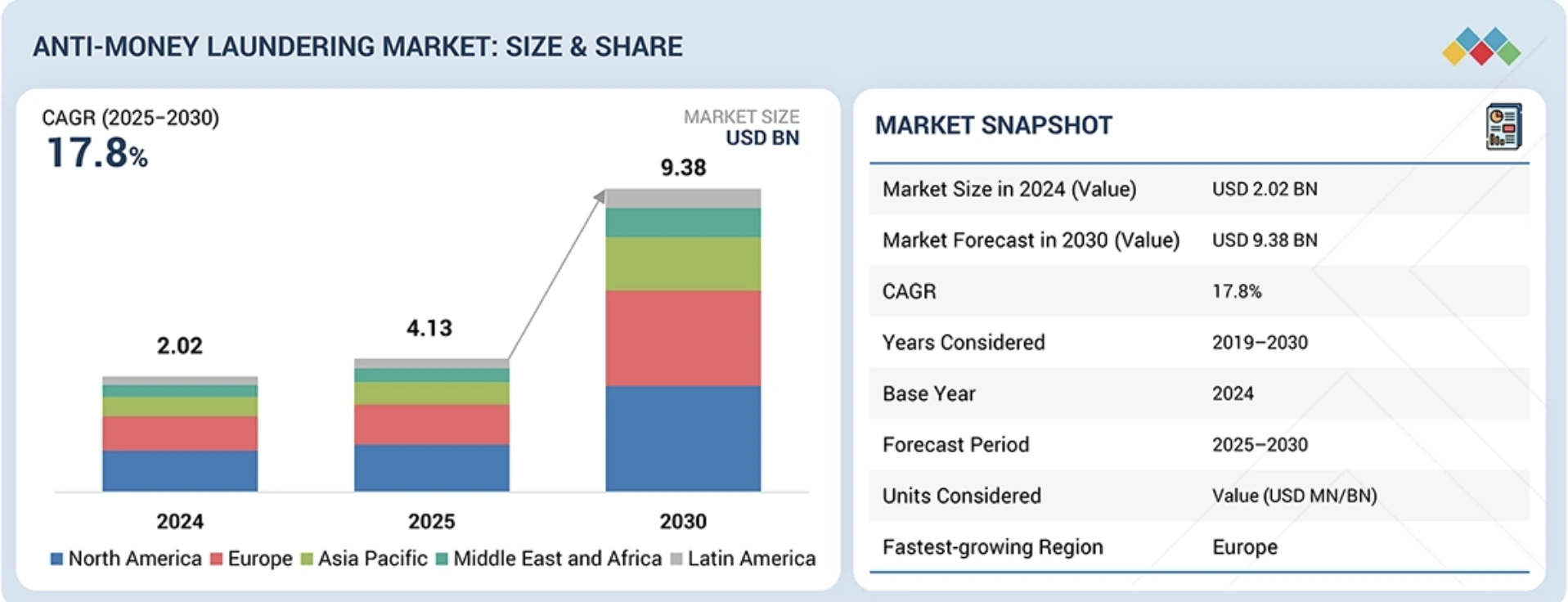
This critical technology transition helps banks manage global regulatory pressures, which pushed financial crime compliance spending past $34.7 billion according to Celent’s 2024 Compliance Market Report.
Because of these rising structural costs, the global anti-money laundering technology market is expanding rapidly at a 17.8% CAGR through 2030. Consequently, automation helps specialist teams focus their energy directly on high-risk cases that require human intelligence.
1. Banks Need Better Investigation Throughput
Financial institutions face massive backlogs because traditional tools fail to synthesize unstructured narrative evidence. Therefore, leaders should not adopt large language models simply because they write quickly. Instead, senior technology teams use them to optimize specific operational metrics across the following areas:
- Evidence Collation: Time spent retrieving case evidence from internal bank databases drops when an AI gathers files automatically.
- Customer Due Diligence: Time spent reviewing KYC and beneficial ownership documents decreases through automated text extraction.
- Drafting Bottlenecks: Time spent drafting case summaries and SAR narratives reduces when an LLM formats the initial report layout.
- Quality Uniformity: The overall consistency of evidence presentation improves across global operational teams.
- Regulatory Updates: Access to current regulatory and internal policy guidance becomes instant via indexed data repositories.
- Capacity Allocation: Analyst capacity for complex FinCrime investigation work expands as routine administrative data processing disappears.
Because compliance teams save hours on manual file collation, they can decrease document reading and case assessment times by up to 80% based on data highlighted in Sanction Scanner’s 2026 Financial Technology Report. This shift directly improves overall operational output. Thus, technology changes human capacity from clerical tracking to active risk mitigation.
2. FinCrime Investigations Depend on Unstructured Information
Traditional transaction monitoring engines identify numerical anomalies, but they cannot interpret text-heavy background files. Consequently, investigators must open multiple screens to manually evaluate varied context sources during an audit.
This unstructured material holds the actual story behind the transactional alerts:
- Customer Records: Onboarding documents, identification forms, and customer-provided balance letters.
- Corporate Registries: Official corporate filings, business licenses, and regional registry updates.
- Ownership Files: Ultimate beneficial ownership records and complex entity tracking charts.
- Public Data: Adverse-media articles, local news publications, and open-source intelligence records.
- Internal Notes: Formal requests for information, past investigator notes, and account manager commentary.
- Regulatory Text: Dynamic policy documents, regional compliance handbooks, and FinCEN advisory notices.
- Cross-Border Data: Wire transfer descriptions, SWIFT message text strings, and international trade invoices.
An LLM creates immediate software value because it processes and summarizes this unstructured material with source traceability.
In fact, banks deploying AI infrastructure report a 20% to 25% productivity increase across their risk and compliance departments according to the Global Skill Development Council’s Generative AI Research.
Therefore, analysts can view verified citations for every data point extracted by the AI. This specific documentation matches the exact standards that regulatory examiners require during bank reviews.
3. Adoption Must Be Linked to Measurable Outcomes
Financial leaders must tie generative AI deployment to clear, trackable key performance indicators rather than vague productivity promises. When banks deploy technology to improve anti-money laundering speed, the entire framework must emphasize auditability and data quality.
According to Infosys BPM’s 2025 Financial Services Analysis, top-tier financial institutions achieve up to a 10.3x return on investment when integrating AI deeply into core compliance workflows.
The following matrix maps core compliance objectives directly to their corresponding operational metrics:
| Adoption Objective | What the LLM Should Improve | What the Bank Must Measure |
| Faster case preparation | Retrieves and summarizes approved case evidence automatically. | Total research minutes spent per compliance case. |
| Better narrative quality | Structures facts into complete draft narratives without omissions. | Reviewer correction rate and mandatory-fact coverage percentage. |
| Faster regulatory interpretation | Retrieves relevant policy and advisory sections instantly. | Time to answer policy questions and citation accuracy. |
| Better KYC review support | Extracts material facts from ownership and due diligence records. | Extraction accuracy and subsequent escalation quality. |
| Reduced analyst administration | Automates repeated evidence collation and summary preparation. | Total analyst time reallocated to complex cases. |
By tracking these specific numbers, banking teams can prove the financial return on their development budget. Consequently, these metrics demonstrate to internal auditors that the system operates within predictable, controlled risk boundaries. Clear tracking transforms AI from an experimental software tool into a reliable enterprise asset.
How Do LLMs Improve AML and FinCrime Investigations?
LLMs improve financial crime investigations by accelerating text-heavy administrative tasks, which traditionally consume 80% of an analyst’s time. Specifically, they automate unstructured data extraction, synthesize complex customer chronologies, and generate consistent report drafts.
This immediate automation allows compliance teams to process backlogs faster while maintaining strict data tracking controls.
1. Mapping the AI Investigation Workflow
Deploying a generative AI AML investigation workflow allows compliance teams to systematically address manual document processing bottlenecks. Therefore, integrating language models directly into the case management structure provides a clear division of labor.
The matrix below details how software features support human investigators at every operational stage:
| AML / FinCrime Workflow Stage | Existing Operational Problem | LLM Contribution | Human or Deterministic Control Required |
| Alert review | Analysts open multiple systems to understand why an alert triggered. | Produces an evidence-linked case summary. | Final alert disposition approval. |
| KYC and CDD review | Ownership and business documents require slow, manual reading. | Extracts names, entities, and missing information during LLM AML document review. | Customer-risk decision. |
| Enhanced due diligence | Complex companies require deeper international business context. | Provides EDD narrative generation and adverse media summarization. | Escalation and remediation decision. |
| Regulatory research | Analysts search policy libraries and public guidance manually. | Facilitates fast regulatory document interpretation. | Policy interpretation and control approval. |
| Investigation report drafting | Evidence must be turned into a consistent written narrative manually. | Powers customer risk narrative generation with citations. | Investigator sign-off. |
| SAR narrative preparation | Facts must be communicated clearly and completely for filings. | Produces a structured draft using approved case evidence. | SAR approval and filing decision. |
By separating data collection from final compliance judgments, banks keep human intelligence at the center of their operations. For a deeper breakdown of end-to-end case workflows, see our guide on how fintech companies build AI AML investigation systems. This structural setup ensures that the technology remains a pure productivity enhancer.
The best starting workflows involve high document volume, repeatable review steps, and clear human approval gates. They give banks measurable value without placing final compliance decisions inside the model. To support those workflows safely, the platform needs a defined set of core production features before advanced intelligence capabilities are added.
Core Features of an LLM AML Compliance Platform
A production LLM AML compliance platform needs six core capabilities: permissioned evidence retrieval, automated document review, regulatory knowledge access, controlled narrative drafting, human workflows, and complete audit tracking. Consequently, without these integrated pillars, a bank may generate readable text but cannot prove its source data or maintain necessary compliance controls.
1. The Six Core Platform Features
Building a production-ready enterprise solution requires a strict architectural blueprint rather than a simple text-generation API interface. Therefore, engineering teams must embed data boundaries directly into the application layer.
The table below lists the six mandatory technical capabilities that compose a compliance-safe enterprise platform:
| Core Feature | What It Must Do | Why It Matters in AML Compliance | Required Evidence or Control |
| Permissioned case evidence retrieval | Retrieve only records the investigator may access for the assigned case. | Prevents unauthorized customer or SAR-sensitive information exposure. | Role, case permission, retrieval history, source version. |
| KYC, CDD, and EDD document review | Extract entities, ownership details, missing records, and risk-relevant facts. | Reduces manual document reading while supporting review consistency. | Extracted field source, confidence, reviewer correction. |
| Regulatory and policy knowledge base | Retrieve current FinCEN, FFIEC, FATF, OCC, and internal policy sections. | Prevents reliance on outdated model memory. | Document version, effective date, source citation. |
| Investigation summary generator | Produce case chronologies, evidence summaries, and open questions. | Helps analysts assess cases without assembling every record manually. | Evidence citations and missing-information flags. |
| Controlled SAR narrative drafting | Draft facts, dates, amounts, parties, suspicious indicators, and rationale. | Supports narrative quality without automating the filing decision. | Reviewer edits, approval, final narrative history. |
| Analyst workflow and audit trail | Route drafts for review, correction, escalation, and approval. | Proves accountable human control during examinations. | Model version, prompt version, retrieved records, reviewer action. |
By codifying these functional layers, financial institutions ensure their artificial intelligence infrastructure meets the rigorous standards expected by state banking regulators. Thus, the software transforms messy operational data into clean, structured compliance evidence.
2. Core Features Must Be Evidence-First
LLMs must not receive unfiltered access to a financial institution’s entire data estate. Instead, the core platform should systematically restrict data exposure to the narrowest set of records needed for an active file. This controlled boundaries setup utilizes specific parameters to maintain a secure environment:
- Case-Scoped Permissions: System structures ensure that the model can only query files associated with the active investigation ID.
- Document Versioning: Platform maps external regulatory updates or internal policy changes to precise time-stamps to prevent information from drifting.
- Source Citations: Every extracted name, address, or transaction pattern includes a hyperlinked connection back to the raw source file.
- Missing-Data Indicators: Model proactively flags incomplete customer records or gaps in the corporate registry history instead of guessing.
- Structured Output Fields: System forces text generations into rigid formats like JSON to ensure predictable downstream data parsing.
- Reviewer Correction Logging: Application captures every manual text edit made by an investigator to create a precise machine-learning feedback loop.
Our development teams prioritize these specific security and indexing layers during platform engineering. For instance, creating an isolated, evidence-grounded ingestion pipeline ensures that user prompts never leak outside your protected database architecture.
3. SAR Drafting (Highest Value Workflow)
Suspicious Activity Report (SAR) narrative generation represents the highest-value workflow within financial crime operations because narrative quality directly impacts law enforcement effectiveness.
Consequently, the platform assists investigators by organizing complex transaction patterns around the core pillars of who, what, when, where, why, and how. The technology acts as a specialized writing companion rather than an independent operator:
- Fact Organization: The system converts raw transaction tables into chronological text outlines that highlight unusual velocity changes.
- Typology Mapping: Software aligns the written case explanation with specific regulatory red flags, such as structuring or shell company indicators.
- Regulatory Alignment: System formats the draft text to meet the explicit content expectations detailed in official banking guidelines.
However, the software does not file reports independently. A human investigator evaluates the generated draft, checks the source citations, and makes the final escalation decision. This strict control loop satisfies the risk management mandates that federal banking examiners review during audits.
Advanced Features Improving FinCrime Investigations
Advanced AI-powered FinCrime features become valuable when complex financial investigations require deep network relationship discovery, multi-source reasoning, or specialized asset tracing.
Therefore, these advanced capabilities extend an LLM platform beyond basic automated drafting, but they also require stronger model validation, wider system integration, and higher deployment budgets.
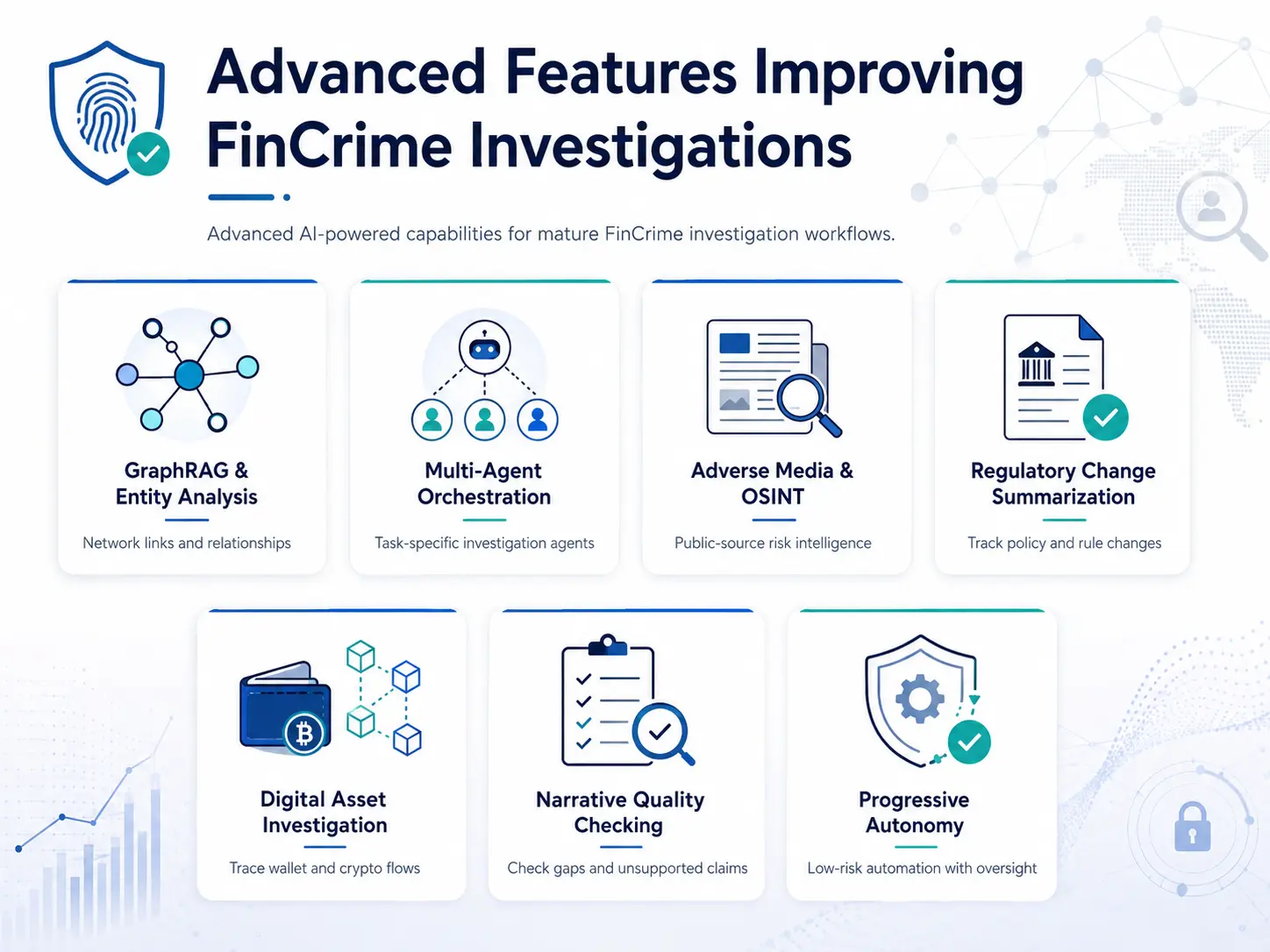
1. The Advanced Capability Matrix
When financial institutions scale past a focused minimum viable product, they require advanced algorithmic features to parse complex criminal patterns. Consequently, these structural upgrades enable real-time analysis across distributed international transaction networks.
The table below outlines the core advanced features designed for mature enterprise compliance frameworks:
| Advanced Feature | What It Adds | Best-Fit Institution or Use Case | Additional Risk Control |
| GraphRAG and entity relationship analysis | Links customers, accounts, devices, beneficial owners, and counterparties before producing an explanation. | Banks or fintechs investigating layering, mule networks, shell entities, or shared identifiers. | Entity-match confidence levels and graph evidence logs. |
| Multi-agent investigation orchestration | Assigns separate controlled tasks for research, document review, pattern explanation, and QA. | High-volume FinCrime teams with defined workflows and mature governance. | Task-level permissions, agent audit identity, and escalation gates. |
| Adverse-media and OSINT intelligence automation | Summarizes relevant public sources and links findings to known network entities. | KYC, EDD, sanctions, PEP, and reputational-risk reviews. | Source reliability grading and prompt-injection filtering. |
| Regulatory change summarization | Compares new guidance with internal policies and flags affected compliance controls. | Multi-jurisdiction banks and regulated payment firms. | Versioned document comparison and compliance approval. |
| Digital asset investigation narration | Explains wallet flows, exchanges, mixers, counterparties, and suspicious transaction paths. | Crypto platforms, payment firms, and banks exposed to virtual asset activity. | Blockchain-source provenance and specialist reviewer sign-off. |
| Automated narrative quality checking | Checks missing facts, unsupported claims, chronology gaps, and absent typology references. | Institutions producing large SAR or investigation-report volumes. | Evidence coverage score and reviewer exception handling. |
| Progressive-autonomy case handling | Allows low-risk tasks to be completed automatically while higher-risk cases remain reviewer-led. | Mature institutions with validated workflows and controlled queues. | Queue-specific autonomy rules and sample-based QA. |
By implementing these high-tier features, banks transform raw database connections into actionable intelligence paths. Thus, operational teams can dismantle hidden criminal rings that easily bypass standard relational database filters.
2. Integrating Network and Entity Analytics
Advanced platforms merge structural network graphs with language generation to resolve complex corporate ownership mazes.
Consequently, this engineering approach addresses hidden layering techniques used by financial criminals to obscure illicit asset origins:
- GraphRAG AML Investigations: This system combines graph database queries with language generation to trace capital across multiple account hops. It outlines the specific flow of funds rather than analyzing single transfers in isolation.
- LLM Entity Resolution: The platform utilizes advanced relationship extraction financial crime models to determine if disparate profile records belong to the same individual. Therefore, spelling variations or altered birth dates are flagged dynamically.
- Sanctions Evasion Detection LLM: The network software automatically uncovers shell company patterns, shared physical addresses, or indirect connections to banned corporate entities during onboarding.
- PEP Narrative Generation: The tool builds comprehensive political exposure summaries by scraping international database registries and structuring public family connections into clear text files.
Our development teams establish explicit prompt injection controls banking protocols during the deployment of these multi-source data connectors. For instance, creating strict data sanitation boundaries ensures that untrusted external documents can never alter the system’s core execution instructions.
3. Tracing Emerging Virtual Asset Risks
Cross-border financial crime increasingly relies on distributed public ledger systems to move illicit assets rapidly through global corridors. Therefore, modern platforms must combine specialized blockchain intelligence feeds with natural language processing to demystify complex on-chain behavior:
- Crypto Transaction Narrative LLM: The application converts complex cryptographic hashes, smart contract interactions, and mixer activity into readable, audit-ready timelines.
- Digital Asset Investigation LLM: The software maps unhosted wallets to known real-world entities by combining proprietary attribution data with advanced open-source intelligence automation tools.
- Typology Translation: The system automatically translates technical blockchain parameters into standard banking terminology, allowing traditional risk officers to easily review cross-asset alerts.
However, advanced autonomous modules do not execute final compliance actions or freeze customer funds independently. Human control remains a structural requirement, meaning the software acts strictly to accelerate investigative velocity.
This architecture protects the institution against unverified automated file updates while preserving overall compliance defensibility.
Top LLM-Based FinCrime Investigation Platforms
LLM-based FinCrime platform results remain limited, but several enterprise software providers now disclose meaningful operational outcomes and production adoption. The strongest evidence currently concerns case investigation speed, SAR narrative preparation time, adverse-media review automation, and production deployment.
Banks should treat these examples as implementation signals, then validate expected outcomes against their own internal historical baselines, policy rules, and reviewer quality standards.
1. Lucinity (Luci AI Agent)
This platform uses Microsoft Azure OpenAI to provide automated case summarization, money-flow analysis, adverse-media search, and regulatory reporting support. In an official Microsoft-linked enterprise implementation, Lucinity reports that average case investigation time fell sharply from 3 hours to just 30 minutes.
The software streamlines every step from initial case assessment to final documentation, allowing banks to scale up investigative velocity. However, it operates purely as an advisory copilot; human analysts retain sole authority to edit the text or confirm the final disposition.
2. Unit21 (AI Investigation Agents)
Operating in production across multiple customer footprints, this technology automates L1 alert triage and structures complex case evidence for human review.
Their integrated deployment with digital asset platform Uphold reduced manual regulatory narrative preparation times from approximately one week down to under 30 minutes.
The platform’s agentic framework handles the investigation end-to-end—triaging the alert, pulling histories, and assembling the evidence package. Analysts review and approve the auto-generated SAR text rather than writing it from scratch.
3. WorkFusion (GenAI-Enhanced Digital Workers)
This platform deploys focused digital analysts like “Evelyn” and “Evan” to handle sanctions screening and adverse-media tracking.
WorkFusion reports straight-through processing automation rates of up to 95% for its enhanced AI-agent workflows while capturing extensive audit trails.
These pre-trained digital workers extract material facts, execute entity matching, and write initial narrative findings. This specific capability helps institutions offload high-volume, routine screening queues while maintaining a strict historical audit record for regulatory compliance examiners.
4. Lucinity and Finshark
Open banking platform Finshark selected Lucinity’s operating framework to reduce manual compliance tasks and scale its cross-border financial operations. This implementation provides consistent case traceability across new regional markets, though a specific quantitative time-reduction metric was not publicly disclosed.
This deployment proves that high-growth fintechs are actively embedding large language models to ensure operational uniformity during rapid cross-border expansion. The software assists developers and analysts by standardizing data ingestion and report generation across varied regulatory jurisdictions.
5. Buyer’s Evidence-Reading Framework
Senior financial technology buyers must avoid choosing software based on generic marketing demos or basic text-writing speed. Therefore, technology leaders should use a structured framework to evaluate platform case studies before allocating development budgets.
The evaluation matrix below highlights the key operational questions that compliance teams must ask vendor teams:
| Question Buyers Should Ask | Why It Matters in AML Platforms | Required Evaluation Factor |
| Was the outcome produced in a live regulated workflow? | Production evidence is far more useful than an isolated feature capability demonstration. | Live production telemetry versus static testing sandboxes. |
| Did the LLM draft text only, or did it retrieve and validate evidence? | Generating rapid text descriptions alone does not prove core investigation or audit value. | Verification of active data grounding and source-linked citations. |
| Was a human reviewer still responsible for escalation and filing? | Regulated anti-money laundering accountability cannot be legally passed to an AI model. | Presence of mandatory human-in-the-loop review screens. |
| Was the reduction in time measured against a baseline? | High productivity claims lack engineering value without a documented historical context. | Clear definition of the manual baseline process being replaced. |
| Were confidentiality, audit, and quality controls disclosed? | Speed without proper model governance substantially increases your operational risk. | Model validation status and data isolation proof. |
These operational examples indicate that LLM-assisted financial crime investigations are moving rapidly past the prototype phase. However, published industry outcomes mostly highlight inner-loop productivity gains rather than an automatic reduction in regulatory penalties. To produce truly defensible results, a bank still needs a technical architecture that rigidly governs what the model can retrieve, generate, and expose to human reviewers.
Architecture of an LLM AML Compliance Platform
A generative AI AML compliance platform requires six controlled engineering layers: approved evidence sources, data normalization, permissioned retrieval, model drafting, analyst review, and audit monitoring. Therefore, every output remains completely traceable to permitted records, current policy material, and explicit reviewer approvals before it touches a regulated reporting workflow.
1. The Six Architecture Layers
Designing a reliable platform requires isolating untrusted text models from raw database records. Consequently, developers must pass transactional data through structured verification layers to guarantee compliance safety.
The table below outlines how each infrastructure tier functions:
| Architecture Layer | What It Does | Example Components | Evidence It Must Preserve |
| Approved source layer | Collects permitted records for investigation support. | Transactions, KYC/KYB records, adverse media, internal policy, guidance. | Source system, document version, timestamp, access purpose. |
| Normalization & entity layer | Standardizes customer, account, ownership, and transaction data. | Canonical data model, entity resolution, NER, relationship extraction. | Field mapping, match confidence, linkage reason. |
| Retrieval layer | Retrieves relevant evidence and guidance for the task. | RAG pipeline, vector store, metadata filters, role permissions. | Query, retrieved chunks, access rule, policy version. |
| LLM drafting layer | Produces summaries, extracted fields, and narrative drafts. | Private model endpoint, prompt templates, structured JSON output. | Prompt version, model version, generated claims, confidence state. |
| Reviewer workflow layer | Routes generated output to analysts for correction and approval. | Case-management integration, approval queues, disposition controls. | Reviewer edits, timestamps, final action. |
| Audit & monitoring layer | Measures performance, security, and quality over time. | Evaluation tests, leakage monitoring, drift tracking, access logs. | Unsupported claims, model changes, exception history. |
2. Build Approved Evidence Layer Before Choosing Model
A common mistake is selecting a commercial model endpoint before mapping the underlying banking records. Therefore, software architects must define a rigid data containment boundary first.
This baseline layer ingests structured ledger transactions alongside unstructured risk profiles, beneficial ownership charts, and public adverse-media scrapers.
Additionally, engineers must enforce role-specific access restrictions at the database level.
This ensures the text tool cannot access confidential records that are off-limits to the active investigator.
3. Use RAG for Current Guidance and Case Evidence
RAG models remain superior to standalone text engines because they stop information hallucination by grounding generations in verified source documents. During ingestion, external regulatory files are split into small chunks and stamped with effective-date metadata filters. The system applies permission-filtered retrieval to fetch only the narrow files relevant to the active case file.
Furthermore, the pipeline converts raw tables into structured JSON output strings while embedding visible evidence citations into the text drafts. The software also uses automated prompt injection screening tools to prevent external customer documents from hijacking the system’s core execution commands.
4. Connect Generation to Review and Audit
The application workspace must preserve a permanent historical log of the original model outputs alongside any manual text corrections. Consequently, when an investigator alters an auto-generated draft, the platform logs those changes to calculate a reviewer redline score.
This tracking architecture retains complete audit trails for model versioning and prompt histories.
For a deeper breakdown of detection inputs and alert generation architecture, see our guide on how do you build an AI transaction monitoring platform today?. Capturing these granular metrics ensures that your system remains fully defensible during formal regulatory audits.
Architecture determines whether an LLM output is merely readable or genuinely defensible during an audit. Banks need traceable evidence and controlled review before generated language can support regulatory work.
Fine-Tuning LLM Vs RAG for AML Investigations
Banks should start with retrieval-augmented generation AML frameworks and structured prompting for financial crime workflows rather than model fine-tuning. Consequently, a RAG configuration keeps shifting regulatory policies and live case evidence outside model weights while making each answer citable.
Fine-tuning should never become a shortcut for loading confidential customer data directly into a model’s long-term memory.
1. Framing the Technical Decision Table
Choosing the wrong training path increases data leakage risk and creates massive model update backlogs. Therefore, banks must separate dynamic background information from the stable formatting styles of their software applications.
The decision matrix below outlines the best technical approach for core investigation use cases:
| AML Use Case | Recommended Approach | Why It Fits | Main Control |
| Regulatory interpretation | RAG over approved, versioned guidance documents. | Rules and advisories change rapidly over time. | Effective-date and citation checks. |
| Investigation summarization | RAG plus structured JSON output templates. | Every material fact must map directly to evidence. | Evidence coverage testing. |
| SAR narrative drafting | RAG plus approved narrative schemas and review. | Drafts require current facts and controlled language. | Reviewer sign-off and output history. |
| KYC document extraction | OCR document models plus LLM explanation. | Extraction and explanation require different controls. | Field-level confidence and review. |
| Stable institutional terminology | Limited domain-specific LLM training or adapters. | Helps output stylistic consistency. | Data-governance approval. |
| Risk scoring or prioritization | Separate ML or graph models with LLM text. | Language generation is not risk detection. | Model validation and explainability. |
By maintaining these clear software boundaries, engineers can safely execute foundation model compliance adaptation without risking ungrounded hallucinations. Thus, the text engine remains a pure processing pipeline rather than an unauthorized storage vault for sensitive information.
2. Separating Data Streams for Clean Model Grounding
A resilient financial crime architecture must separate dynamic data components from static software code layers.
Consequently, this clear separation ensures that your platform can update its operational knowledge base without needing constant model retraining cycles:
- Dynamic Knowledge Bases: Regulatory rules, public advisories, and internal policies change over time, so they must stay in an indexable RAG compliance knowledge base.
- Live Case Evidence: Transnational wire records and unverified customer profile uploads are treated as ephemeral inputs that never enter the model’s permanent weights.
- Stable Style Terminology: Large language model fine-tuning AML techniques should only be used to teach an application standard internal bank taxonomy and structural report templates.
- Analytical Risk Scores: Neural networks and graph tools run separate detection calculations, while the language layer simply explains those results to human operators.
Ultimately, your platform achieves robust model grounding compliance documents verification by enforcing these engineering divides. This split-layer design guarantees that human investigators remain the sole source of legal decision authority.
RAG is not a complete compliance control by itself. It controls grounding only when retrieval permissions, source versions, prompt rules, and analyst review are also enforced. This becomes especially important when the proposed retrieval corpus contains prior SAR narratives or information revealing earlier filing decisions.
Should Existing SAR Narratives Enter the LLM Context Window?
The primary question is whether historical filing text should guide live case reviews. Filed SAR narratives should not become a default retrieval corpus for live LLM AML investigations because they expose confidential data, repeat outdated structural habits, and introduce severe decision bias into new cases.
Therefore, banking platforms must restrict past report text to isolated evaluation environments while forcing live models to build summaries purely from fresh transaction ledger files.
1. The SAR Retrieval Firewall
Building a secure financial crime platform requires establishing an absolute separation between live case files and highly restricted past regulatory submissions. Therefore, engineering teams must deploy strict data-filtering controls within the core retrieval pipeline.
The table below outlines the mandatory data segregation boundaries required to protect operational confidentiality:
| Information Category | Examples | Default Retrieval Rule | Approved Use |
| Routine case evidence | Transactions, customer KYC/KYB files, beneficial ownership charts. | Available only to assigned roles and permitted case IDs. | Active case review and draft narrative support. |
| Approved public guidance | FinCEN advisories, FATF text, FFIEC manual updates. | Versioned, indexed, and routinely retrievable by the system. | Regulatory interpretation and narrative structuring. |
| Restricted SAR material | Filed SAR text, draft decisions, internal filing commentary. | Excluded entirely from default LLM retrieval pipelines. | Access only through expressly controlled audit workflows. |
| QA evaluation data | Redacted, synthetic, or approved benchmark case histories. | Isolated within a separate evaluation database corpus. | Testing narrative quality and analyst team training. |
2. Historical SAR Retrieval Can Harm Quality
Historical SAR retrieval harms quality because it forces the model to copy outdated writing habits and defensive filing biases from old cases. Consequently, the text engine mimics past human mistakes instead of evaluating fresh evidence.
This repetition leads to messy narrative structures, introduces unverified facts, and can cause severe data leakage across completely unrelated customer files.
- Outdated Formatting: Old narrative wording frequently fails to reflect current regional expectations or modern typology definitions.
- Defensive Bias: Historical defensive filing patterns can skew new AI text drafts into over-reporting non-suspicious transactions.
- Incomplete Patterns: Relying on past flawed narratives can inadvertently teach the model to omit critical data fields (Source: [FinCEN, Suggestions for Addressing Common SAR Narrative Errors]).
- Analyst Prejudging: Seeing a historical decision can bias an investigator before they fully evaluate the active evidence package.
- Data Leakage: Confidential SAR information may cross-contaminate unrelated case workflows, violating strict privacy laws (Source: [FinCEN, Guidance on Maintaining SAR Confidentiality]).
- Fact Omission: The model may mimic historical conclusions verbatim instead of reasoning directly from fresh transaction ledgers.
Our development teams prevent these issues by physically separating reporting databases from active LLM context indexing tools. This ensures the language engine builds summaries based on real-time facts rather than copying old text blocks.
3. Evidence Coverage Score Instead of Historical Data
An evidence coverage scorecard improves reporting by scanning generated drafts against strict regulatory rules instead of letting an LLM guess based on historical data. Therefore, the system automatically checks every draft for mandatory elements like names, dates, amounts, and specific transaction locations.
This strict mechanical check ensures the report remains fully accurate, completely verifiable, and ready for regulatory audit.
| Required Narrative Element | Validation Question the System Executes |
| Who | Are all relevant persons, businesses, identifiers, and counterparties completely extracted? |
| What | Is the core suspicious activity and financial typology stated clearly without vague prose? |
| When | Are the transaction dates, frequencies, and relevant review periods mathematically accurate? |
| Where | Are all regional jurisdictions, digital wallets, bank branches, and funding channels identified? |
| Why | Does the draft explain precisely why the observed activity is unusual or economically irrational? |
| How | Does the text clearly detail the suspected laundering method, pattern, or criminal typology? |
| Evidence | Is every material text claim hyperlinked directly back to permissioned case data? |
The bank should evaluate an LLM by whether it uses permitted evidence correctly, not by whether it closely resembles historical filings. A restricted retrieval architecture protects both narrative quality and legal confidentiality.
Once the retrieval boundary is clear, the institution must prove that generated outputs remain accurate, secure, reviewable, and fully governed.
How Should Banks Secure LLM FinCrime Workflows?
Banks must validate large language model FinCrime workflows through structured performance scoring, continuous data privacy auditing, and strict human review controls. Therefore, your engineering team must run explicit tests for grounding quality, numeric accuracy, and structural completeness before introducing an application into live operations.
This careful testing strategy ensures the platform operates safely within your established enterprise compliance limits.
1. The Technical Validation Scorecard
Deploying an LLM for AML compliance requires moving past subjective human assessments to track clear, quantitative software performance metrics. Consequently, data engineers run continuous regression suites against a standard bank benchmark data collection to intercept information drift.
The matrix below defines the primary validation areas and corresponding acceptance rules required to verify an enterprise system:
| Validation Area | What to Test inside the Platform | Example Technical Acceptance Rule |
| Evidence grounding | Whether every material text statement maps directly to retrieved evidence. | Zero uncited material case claims are allowed in approved outputs. |
| Numeric fidelity | Whether dates, transaction amounts, and counterparty counts remain accurate. | Zero material numeric discrepancies exist across your testing batch. |
| Narrative completeness | Whether mandatory who, what, when, where, why, and how fields are addressed. | Mandatory-fact structural checklist must hit 100% before approval. |
| Unsupported assertion risk | Whether the model invents internal suspicion reasons or customer history details. | Unsupported material claims automatically trigger a text rejection flag. |
| Restricted-data leakage | Whether SAR-sensitive material enters unauthorized prompts or logging tables. | System must pass a comprehensive data isolation leak test suite. |
| Prompt injection resilience | Whether hostile external customer text changes underlying software behavior. | System passes all adverse-media and document red-team test suites. |
| Reviewer control | Whether analysts can easily edit, reject, and document system outputs. | All material case edits retain a permanent named reviewer log history. |
| Change monitoring | Whether model, prompt, corpus, or policy updates degrade final quality. | Automated regression test pipeline triggers after every material update. |
| Token cost and latency | Whether processing times and API token usage remain economically viable. | Per-case inference cost and round-trip latency are tracked hourly. |
2. Navigating the 2026 Model Risk Regulatory Reality
Building a compliant validation roadmap requires tracking specific, regional regulatory mandates that govern bank technology deployments.
For instance, the FFIEC sets strict expectations for final SAR narrative quality, while FinCEN heavily polices SAR confidentiality obligations to protect sensitive data estates.
Furthermore, the Federal Reserve, FDIC, and OCC released their joint SR 26-2 / OCC Bulletin 2026-13 Revised Guidance on Model Risk Management, which explicitly places generative AI and agentic AI models outside the formal definition of a quantitative financial model.
However, this same interagency material notes that institutions must rely on their broader risk management frameworks to determine controls for out-of-scope tools. Therefore, banks still require a fully documented internal control protocol to defend their generative applications during state examinations.
3. Private Deployment and Security Requirements
Financial institutions should never utilize public consumer endpoints that use customer prompts to train future commercial models.
Instead, engineers must deploy a zero-trust LLM architecture inside an isolated cloud perimeter to protect personally identifiable information (PII). This secure deployment model requires choosing an infrastructure strategy that matches your internal technical capacity:
- Controlled Enterprise API Endpoint: Best for low-volume pilots using restricted, non-sensitive data pools because it offers the fastest development setup.
- Private VPC Model Endpoint: Best for active production workflows handling live case data since it preserves absolute corporate data ownership.
- Institution-Hosted Private LLM: Best for massive tier-one banks requiring total physical infrastructure control despite having massive operational overhead.
For a deeper breakdown of controlled model hosting, see our guide on how to build private LLMs for enterprise use. Isolating your deployment network protects your repository against external prompt injections while keeping client identities anonymous.
A secure LLM AML deployment is not simply a private model endpoint. It is a governed system of permissions, evidence controls, validation tests, audit records, and reviewer ownership. With those controls defined, banks can estimate what a realistic build costs and which scope belongs in the first release.
How Much Does LLM AML Compliance Platform Development Cost?
LLM AML compliance platform development usually costs $60,000 to $220,000+ depending on workflow scope, evidence integrations, private deployment requirements, and the number of regulated business lines involved. Therefore, a focused investigation assistant costs far less than a bank-wide FinCrime platform supporting advanced network intelligence and automated workflows.
This variability allows institutions to align their initial financial allocation directly with immediate regulatory pressures.
1. Complete Phased Cost Breakdown
Building an enterprise solution requires mapping expenditures across specific, sequential development phases rather than relying on general software estimates. Consequently, separating initial infrastructure setup from advanced machine learning layers prevents budgeting surprises during deployment.
The table below details the specific dollar ranges associated with each engineering block:
| Development Phase | What It Includes | Estimated Cost Range |
| Workflow discovery and mapping | Use-case definition, evidence permissions, SAR handling rules, reviewer ownership, KPI planning. | $8,000–$18,000 |
| Data and case-system integrations | Transactions, alerts, customer records, KYC/KYB, adverse-media sources, case platform connections. | $15,000–$55,000 |
| RAG compliance knowledge base | Regulatory corpus, internal policies, document metadata, retrieval filters, version control. | $12,000–$35,000 |
| Core LLM investigation workspace | Case summaries, document review, regulatory retrieval, narrative drafting, structured outputs. | $15,000–$55,000 |
| Security and private deployment | IAM, encryption, private endpoints, audit logging, restricted-content controls. | $15,000–$60,000 |
| Validation and controlled pilot | Test cases, hallucination checks, leakage tests, reviewer QA, monitoring dashboards. | $10,000–$40,000 |
| Advanced FinCrime capabilities | GraphRAG, crypto narratives, agentic workflows, sanctions intelligence, multi-region controls. | $35,000–$150,000+ |
2. Budgeting by Operational Tier
Financial institutions must select a production deployment strategy that matches their precise transaction volume and network risk exposure. Therefore, teams should evaluate initial build costs alongside engineering timelines to plan their long-term infrastructure roadmap.
The table below contrasts the three primary architectural tiers deployed in commercial banking environments:
| Build Type | Suitable First Scope | Estimated Build Cost | Typical Timeline |
| Focused LLM AML investigation MVP | Case summarization, KYC review, regulatory retrieval, controlled narrative drafts. | $60,000–$120,000 | 10–14 weeks |
| Integrated production platform | Private deployment, case integration, SAR drafting, validation, audit controls. | $120,000–$280,000 | 4–7 months |
| Advanced FinCrime platform | GraphRAG, digital assets, sanctions workflows, agent orchestration, multi-region support. | $280,000–$450,000+ | 7–12 months |
By tracking these historical baseline ranges, banks can systematically build out capabilities without interrupting their live transaction monitoring queues. For a deeper breakdown of AML copilot budget drivers, see our guide on what does it cost to build an AI AML compliance copilot?.
3. Managing Long-Term Operational Expenditures
Annual software maintenance, ongoing model evaluation, token consumption tracking, and vector database updates should be budgeted at 18% to 25% of the initial build cost.
This recurring allocation fund covers model drift monitoring, continuous privacy validation, and immediate ingestion modifications when regional policies change. Thus, allocating a dedicated maintenance layer preserves your core platform defense over time.
Our comprehensive procurement kit includes phased development cost estimators, strict database integration checklists, zero-trust private deployment blueprints, model validation scorecards, and live pilot KPI worksheets.
How Should Banks Build an LLM AML Compliance System?
Banks should build an LLM AML compliance system in six controlled phases: select a measurable workflow, map permitted evidence, establish the RAG knowledge base, develop analyst-facing outputs, validate security, and pilot with named reviewers.
Consequently, production expansion must follow measured data improvements rather than a demonstration of fluent text generation. This phased deployment path guarantees complete system tracking.
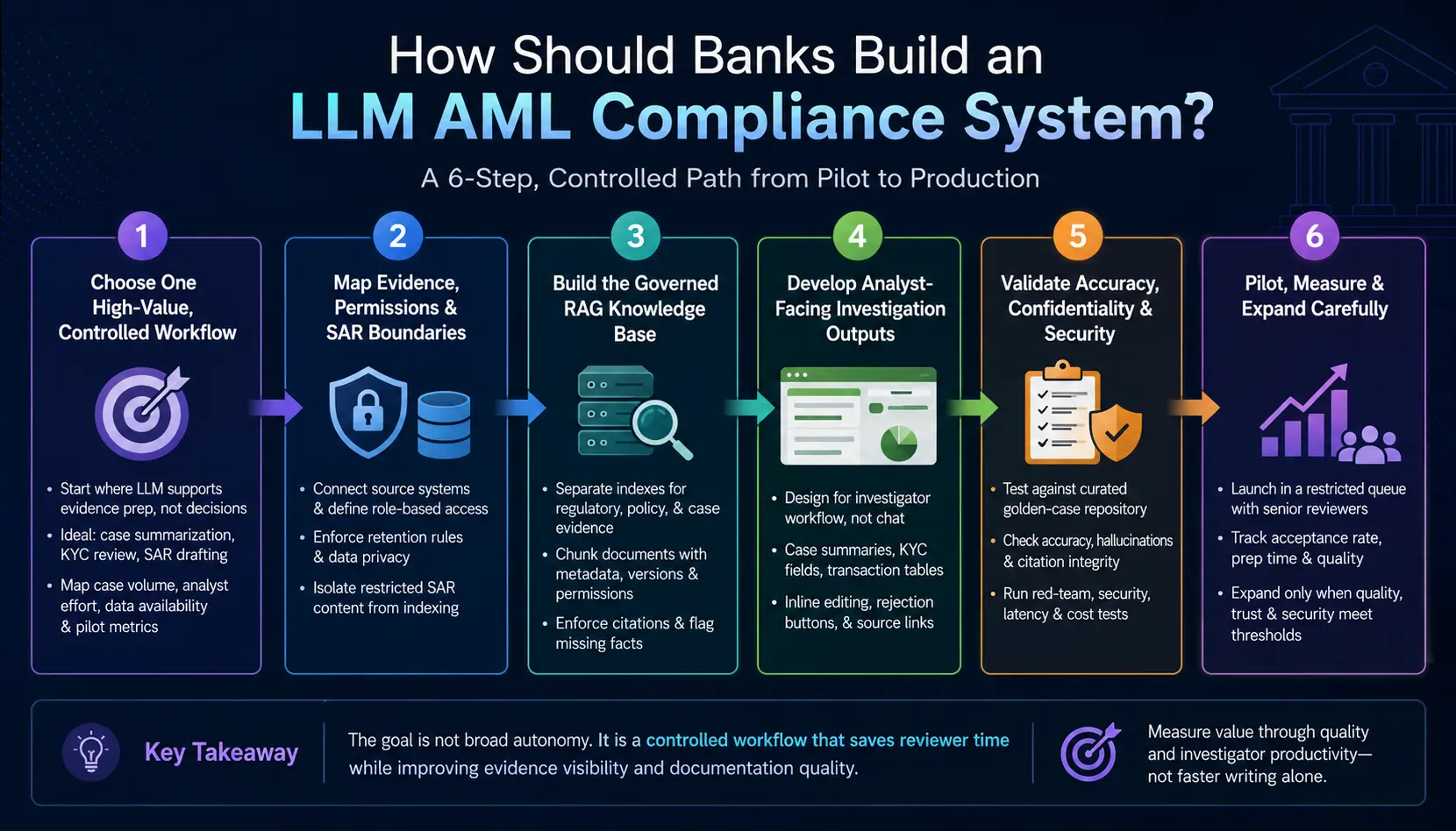
Step 1: Choose One High-Value, Controlled Workflow
Begin with a workflow where the model supports evidence preparation but does not independently make a regulatory decision. Therefore, compliance technology teams should target heavy document bottlenecks like automated case summarization, KYC file review, or drafting SAR narratives under direct reviewer control.
Our development team maps active case volume, analyst labor, data availability, and pilot metrics before writing a single line of software code. Once the workflow is selected, the team must define exactly which information the model may access.
Step 2: Map Evidence, Permissions, and SAR Boundaries
Map all permitted database connections and security groups before selecting a language model endpoint. Consequently, this step defines the specific source systems, role permissions, and retention rules required to protect customer data privacy. Engineers must explicitly isolate restricted past SAR text from the active indexing pipeline to ensure total regulatory confidentiality.
We construct an unbreachable data-boundary matrix before implementing any retrieval architectures or prompt templates to prevent unauthorized information exposure across system layers.
Step 3: Build the Governed RAG Knowledge Base
Build separate retrieval indexes for public regulatory guidance, internal bank policy files, customer evidence records, and isolated evaluation material. Therefore, data pipelines split ingestion documents into small text chunks, stamping each item with metadata version controls and strict permission access filters. The system enforces citation formatting rules to tie every generated claim directly to a verifiable file link while highlighting missing facts automatically.
Our platform engineering approach utilizes separate cloud storage buckets to keep internal banking records physically isolated from outside data streams.
Step 4: Develop Analyst-Facing Investigation Outputs
Design user screens around how investigators review case evidence rather than offering a generic, conversational chatbot interface. Consequently, the user workspace must present clear, structured case summaries, field-level KYC extraction fields, and side-by-side transaction explanation tables. The user interface embeds direct text editing blocks and clear rejection buttons to allow analysts to modify or scratch generated content easily.
We build custom case management components that help analysts check underlying evidence sources with a single click.
Step 5: Validate Accuracy, Confidentiality, and Security
Run comprehensive testing suites against a curated repository of approved golden-case histories before pushing software into production. Therefore, quality assurance engineers trigger automated checks to verify narrative completeness, catch hallucinated claims, and run red-team scripts to test prompt injection resilience.
The platform also evaluates round-trip latency and token utilization costs under peak enterprise transaction volumes. Every single code modification or prompt adjustment automatically triggers our regression testing suite to keep the platform perfectly calibrated.
Step 6: Pilot, Measure, and Expand Carefully
Launch the validated platform inside a highly restricted pilot queue using a small group of senior compliance officers. Consequently, managers restrict initial case handling to simple alert types while tracking reviewer acceptance rates and document preparation speed against your historical baseline.
This gradual roll-out ensures that the operational framework remains stable before scaling up to secondary business lines. We expand platform scope only when evidence quality, reviewer trust, security metrics, and audit history parameters satisfy pre-agreed performance thresholds.
The first production goal is not broad autonomy. It is a controlled workflow that saves reviewer time while improving evidence visibility and documentation quality. The bank should then evaluate value through quality and investigator productivity together, rather than celebrating faster writing alone.
Conclusion
An LLM for AML compliance becomes valuable when it helps investigators retrieve permitted evidence, interpret complex documents, explain case context, and draft clear narratives without taking ownership of regulated decisions. Therefore, banks must start with a controlled workflow, prioritizing core features over advanced autonomy.
Because published FinCrime examples demonstrate real productivity potential, establishing a strict SAR retrieval firewall remains essential for confidentiality and narrative quality. Consequently, securing a private deployment, validating output accuracy, and maintaining immutable audit trails are mandatory prerequisites before expanding any automated compliance system across enterprise banking operations.
Build an LLM AML Investigation Platform With Intellivon
Banks do not need another AI interface that produces confident answers without evidence. They need an LLM for AML compliance that retrieves permitted case information, supports FinCrime investigators, drafts traceable SAR narratives, protects restricted data, and keeps compliance officers in control.
Intellivon builds these platforms around your workflows, evidence sources, governance boundaries, and production requirements.
1. Define the Right LLM AML Workflow First
An effective build begins with the investigation activity where language processing creates measurable value without shifting regulatory accountability to the model.
Intellivon helps banks select the right first workflow, map reviewer responsibilities, and define how success will be measured before architecture or model decisions begin.
- Identify high-effort workflows across SAR drafting, KYC review, and case summarization.
- Map the evidence analysts currently gather before making escalation decisions.
- Separate analyst-support activities from regulated decisions that require human approval.
- Define pilot KPIs for review time, evidence coverage, corrections, and auditability.
- Set clear boundaries for restricted SAR material before model access begins.
2. Design a Private, Evidence-Grounded LLM Architecture
A bank-grade LLM AML compliance platform must generate answers from approved evidence, not general model memory.
Intellivon designs a controlled RAG architecture that connects customer, transaction, regulatory, and investigation data while preserving permissions, document versions, retrieval history, and security controls across each generated output.
- Build permissioned retrieval across case records, KYC documents, and regulatory guidance.
- Connect internal policies, FinCEN material, FFIEC guidance, and approved typologies.
- Use private deployment options for sensitive customer and investigation context.
- Add role-based access controls, encryption, audit logs, and retention rules.
- Create SAR retrieval boundaries that prevent uncontrolled use of filing history.
- Generate source-linked summaries with missing-evidence flags for investigator review.
3. Build Core and Advanced FinCrime Capabilities
Banks should begin with reliable core features, then expand into advanced FinCrime intelligence only after evidence controls and reviewer workflows are proven.
Intellivon develops modular platforms that can support immediate investigation needs while creating a controlled path toward deeper entity, network, sanctions, and digital asset analysis.
Core platform capabilities:
- LLM-assisted investigation summaries built from approved case evidence.
- KYC, CDD, EDD, and beneficial ownership document review.
- Regulatory knowledge retrieval across current policies and advisories.
- Human-reviewed SAR narrative drafting with complete version histories.
- Case-management integration for escalation, correction, and approval workflows.
- Immutable audit trails covering prompts, sources, outputs, and reviewer actions.
Advanced AI-powered capabilities:
- GraphRAG analysis for connected accounts, entities, devices, and counterparties.
- Adverse-media and OSINT summarization with entity-level source verification.
- PEP and sanctions-risk narrative generation for enhanced investigations.
- Crypto transaction explanations for digital asset and wallet-based activity.
- Regulatory change summarization linked to impacted internal controls.
- Agentic workflow support for controlled research, drafting, and quality checks.
4. Validate Every Output Before Production Expansion
Readable narratives are not enough for AML compliance. The platform must prove that generated summaries and SAR drafts remain accurate, source-grounded, confidential, and reviewable.
Intellivon establishes validation controls before expansion, so banks can assess productivity gains without weakening evidence quality or governance ownership.
- Test generated claims against approved source records and transaction evidence.
- Measure narrative completeness across facts, amounts, entities, dates, and rationale.
- Detect unsupported statements, missing citations, and retrieval-quality failures.
- Run confidentiality tests for SAR-sensitive material and restricted case information.
- Test prompt-injection risks within uploaded files and adverse-media sources.
- Record reviewer edits, rejections, approvals, and final case outcomes.
- Monitor model, prompt, policy, and retrieval changes after deployment.
5. Plan a Controlled LLM AML Compliance Pilot
Your first release should not attempt to automate every FinCrime workflow. It should prove that one controlled use case can reduce investigator administration, improve evidence access, strengthen narrative preparation, and maintain human accountability.
With Intellivon, your pilot roadmap can include:
- A defined AML investigation or SAR drafting use case.
- An approved evidence and restricted-data access framework.
- A RAG and private deployment architecture plan.
- A core and advanced feature roadmap.
- A validation, security, and audit-readiness checklist.
- A phased development estimate aligned to your systems and compliance scope.
Build a governed FinCrime investigation platform that helps analysts work faster, document evidence clearly, and retain full control over every compliance decision with Intellivon.
Things To Know About LLM for AML Compliance Development
Q1. How much does it cost to build an LLM AML compliance platform?
A1. A controlled LLM AML compliance MVP usually costs $60,000–$120,000 for investigation summaries, KYC review, RAG-based policy retrieval, and reviewer-approved drafting. However, production platforms with private deployment, case integrations, validation, and audit controls cost $120,000–$280,000. In practice, advanced FinCrime builds using GraphRAG, digital asset intelligence, or multi-agent workflows can exceed $450,000.
Q2. How long does LLM AML compliance platform development take?
A2. A focused LLM AML compliance platform development pilot generally takes 10–14 weeks. However, a production release integrating alert records, customer data, case workflows, private deployment, and output-validation controls usually takes 4–7 months. Overall, broader FinCrime platforms with graph intelligence, crypto narratives, sanctions workflows, or multi-jurisdiction retrieval typically require 7–12 months.
Q3. Can an LLM SAR narrative generation banking workflow prepare a compliant draft?
A3. An LLM SAR narrative generation banking workflow can prepare a reviewable draft when it retrieves approved evidence and structures facts, transaction activity, chronology, and suspicious indicators. However, it should never decide whether reporting is required. A qualified reviewer must correct, approve, and file the report while preserving evidence and edits.
Q4. Does an LLM financial crime investigation tool need private deployment?
A4. An LLM financial crime investigation tool needs private or tightly controlled deployment when it handles customer records, case evidence, internal procedures, adverse-media findings, or SAR-sensitive information. Limited pilots may use governed enterprise endpoints. However, production environments usually require private infrastructure, encryption, access logging, retention controls, and permission-filtered retrieval by design.
Q5. Should banks train LLMs on historical SAR narratives?
A5. Banks should not use filed SAR narratives as a default training or live-retrieval corpus. These records may reveal confidential filing information and reproduce incomplete historical reasoning. Instead, live generation should use approved evidence and current guidance, while redacted, synthetic, or approved narrative examples remain isolated for testing and quality assurance.



