Key Takeaways:
-
Static rule engines fail as payer policies update hundreds of times every single year.
-
Automation reduces the cost per claim from $7.13 manually to $1.25 with full automation.
-
OCR, NLP, ML denial prediction, and rules engines must work together as one pipeline.
-
Platform ROI builds progressively, with the strongest gains appearing after six months of deployment.
-
Intellivon builds modular claims automation platforms with payer-aware logic and audit-ready compliance controls.
Automated medical claims processing has become essential in healthcare platforms that deal with overflowing claims requests and delays in claims processing and reimbursement. These delays eventually lead to users opting out of your company because of broken trust. The consequences of such mistrust lead to reduced ROI and high employee burnout rates.
In 2024, US healthcare organizations lost $262 billion to claim denials. Initial denial rates hit 11.8%, up from 10.2% just three years earlier. However, the administrative cost to rework each denied claim runs between $48 and $64, which is a significant monetary loss when compounded across the total number of denied claims.
However, there is a remedy to this. A medical claims automation platform is the infrastructure that changes these circumstances by automating the intake, payer-rule validation, prior authorization, and payment workflows that sit at the root of the problem.
Throughout our years of experience, we have built healthcare AI systems where claims logic and enterprise integrations need to work together rather than in isolation. By the end of this blog, you will know how we build such platforms, their architecture, AI model requirements, HIPAA security controls, ROI modeling, and the development cost.
What Is a Medical Claims Automation Platform?
A medical claims automation platform is a healthcare software system that automates claim intake, payer-rule checks, denial prediction, and exception handling across provider, payer, and clearinghouse workflows.
It is the operational infrastructure that sits between care delivery and reimbursement, converting clinical and administrative data into paid claims without requiring a billing team to manually touch every transaction.
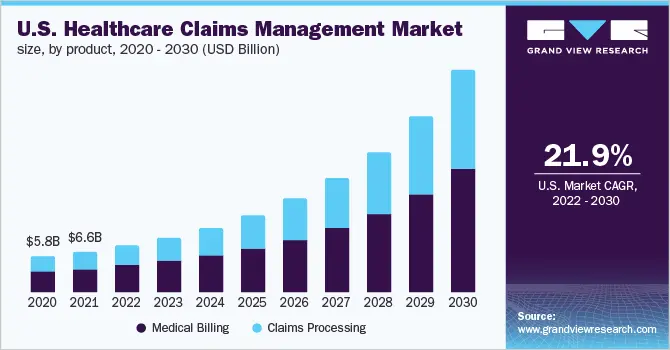
AI-powered segments are expanding considerably faster as platforms like Innovaccer, Waystar, Experian Health, and Goml demonstrate measurable denial reduction at scale.
For healthcare businesses still relying on manual denial workflows, that competitive gap is now turning into a revenue gap.
1. Claims Automation vs. Medical Billing Automation vs. RCM Automation
Engineering teams frequently mistake these three distinct software layers, which creates severe architectural debt during database design phases.
Medical billing software merely provides human-facing data entry screens for generating basic patient invoices. At the same time, Revenue Cycle Management (RCM) suites orchestrate the entire financial lifecycle from patient scheduling down to long-term bad debt collections. In contrast, a custom claims automation platform isolates the middle-tier transaction data processing loop to run algorithmic rules engines.
The table below details the technical boundaries separating these three operational architectures:
| Architectural Layer | Core Technical Focus | Primary Data Integrations | Key Engineering Metric |
| Medical Billing Software | Manual invoice entry and customer statement management | Local practice systems, payment gateways | Daily invoice generation volume |
| Claims Automation Platform | Automated EDI 837 parsing, NLP validation, and rules engines | EHR systems via FHIR APIs, clearinghouses | First-pass acceptance rate |
| RCM Automation Suite | Macro-level healthcare financial lifestyle orchestration | Full hospital ERPs, legacy banking ledgers | Days in accounts receivable (DAR) |
Operating costs drop from $7.13 per manual claim to $1.25 when using automated transaction systems. This structural decoupling ensures that your developers can scale compute resources independently during bulk file transfers.
2. Core Automated Workflows in the Platform
A medical claims automation platform orchestrates six core transactional workflows to eliminate manual intervention in the revenue cycle. These pipelines process high-volume health data while applying programmatic validation gates.
- Claim Submission: Ingests clinical billing data to generate, format, and securely transmit EDI 837 files to clearinghouses.
- Eligibility Checks: Runs automated, real-time insurance verification via X12 270/271 transactions prior to care delivery.
- Coding Validation: Programmatically cross-references ICD-10-CM, CPT, and HCPCS codes against NCCI edits to prevent diagnostic mismatches.
- Denial Prevention: Runs predictive machine learning models to scan claims for potential rejection risks before final submission.
- Payer Communication: Tracks transaction states and automatically updates claim statuses through direct X12 276/277 data loops.
- Remittance Processing: Ingests inbound EDI 835 files to perform automated ERA reconciliation against original provider bank deposits.
Manual workflows increase administrative overhead and drive average claim denial rates up to 11%, per Finance Yahoo News.
Core System Integrations
To achieve straight-through processing, the platform must connect to disparate healthcare software systems using standardized data protocols.
- EHR and Billing Systems: Pulls clinical documentation, patient encounters, and encounter fees using legacy HL7 v2 messages.
- Clearinghouses and Payer APIs: Routes batches and real-time transactions through secure HTTPS endpoints using X12 EDI standards.
- FHIR Integration: Queries modern health data repositories via FHIR R4 Claims APIs using secure JSON structures.
- EDI 837/835 Engines: Translates internal application database fields into compliant X12 837 healthcare claims and parses incoming 835 remittance advice.
Developing decoupled API adaptors prevents legacy protocol changes from breaking your core application logic. Selecting the right integration stack determines the overall data processing velocity of your custom platform.

Why Your Claims Automation Might Fail After 12 Months
Payer rules, authorization requirements, coding policies, contract terms, and denial patterns change faster than static workflows can adapt, causing most claims automation platforms to fail within a year.
If your platform cannot detect, update, and audit these shifting payer rules, its processing accuracy will decline rapidly. This systemic rule decay degrades your clean claim rate and increases days in accounts receivable.
1. What Payer Rule Decay Means
Payer rule decay is the progressive loss of system accuracy that occurs when processing claims using outdated local coverage determinations. Commercial health plans update their medical necessity criteria hundreds of times annually.
This policy volatility leads to immediate electronic rejections at the clearinghouse network if data pipelines lack real-time adjustment capabilities.
2. Why Static Automation Breaks Over Time
Static rule engines rely on hardcoded parameters that cannot accommodate evolving clinical coding standards. The American Medical Association routinely updates thousands of CPT codes and modifier logic rules.
Without dynamic rule lifecycle management, static custom claims processing software development systems trigger the following architectural failures:
- Coding Inaccuracy: The software submits deleted ICD-10-CM codes.
- Authorization Mismatches: Workflows fail to trigger AI-powered prior authorization automation gates.
- Drift: Outdated fee schedules mask systemic payer underpayment trends.
3. How Rule Versioning Protects Claims Accuracy
To mitigate this decay, a high-performance payer rule engine development healthcare infrastructure must treat every rule as a version-controlled object. The system schema must explicitly track:
- Provenance: Rule mapping back to official payer policy documents.
- Temporal Bounds: Effective dates to ensure RAC audit readiness.
- Specificity: Rules restricted by specific insurance plans and exception logic.
CTOs must prioritize rule versioning during the initial automated claims processing system development phase to prevent rapid model drift.
For a deeper breakdown of payer-aware workflows, see our guide on AI Revenue Cycle Management Software Development.
Core Features Every Medical Claims Automation Platform Needs
An enterprise medical claims automation platform should include claim intake, document extraction, payer-rule validation, eligibility verification, prior authorization support, coding review, denial prediction, adjudication support, payment posting, human review queues, analytics, audit logs, and integration management.
Implementing these features within a custom revenue cycle claims automation development project allows healthcare networks to bypass clearinghouse bottlenecks. This unified engineering blueprint ensures high first-pass acceptance rates across all payer configurations.
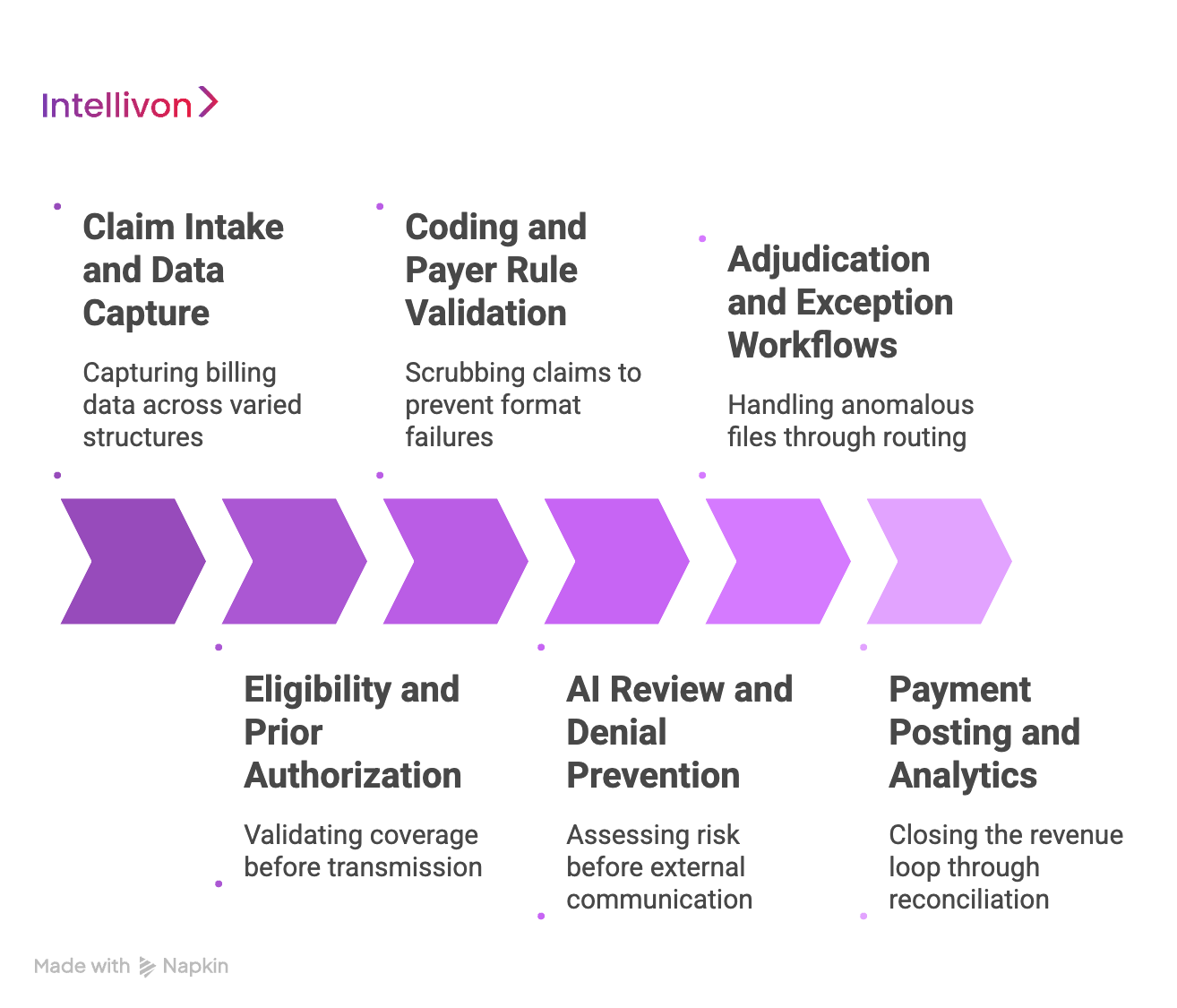
1. Claim Intake and Data Capture
The platform operates an ingestion engine to capture billing data across varied structures.
- Multi-Source Ingestion: Imports unstructured document uploads, paper claim forms, and direct EHR data via legacy HL7 v2 or custom database connectors.
- Advanced Extraction: Uses specialized NLP for medical claims processing to extract structured clinical text fields.
- Standardization: Generates an internal database object containing standardized elements, preparing raw text for strict EDI claims processing automation platform conversion.
2. Eligibility and Prior Authorization
This microservice validates coverage directly against payer nodes before final transactional transmission.
- Coverage Verification: Executes real-time X12 270/271 electronic checks to verify active plan status and copay criteria.
- Requirement Detection: Parses clinical documentation to determine if specific CPT codes require explicit authorization tokens.
- AI-Powered Prior Authorization Automation: Tracks authorization statuses, records approval numbers, and flags impending token expiration dates.
3. Coding and Payer Rule Validation
The validation layer acts as an advanced claim scrubbing microservice to prevent format failures.
- Code Validation: Evaluates combinations of ICD-10-CM diagnostic fields, CPT procedural codes, and HCPCS modifiers.
- Compliance Verification: Programmatically cross-references data arrays against NCCI edits, LCD compliance, and NCD compliance frameworks.
- Payer Rule Engine Development Healthcare: Routes claims through specialized rule matrices that execute distinct validation profiles per commercial insurer.
4. AI Review and Denial Prevention
This predictive intelligence layer assesses transactional risk before external communication.
- Risk Scoring: Generates an explicit denial risk score based on historical payer behavior monitoring data.
- Inconsistency Alerts: Flags missing documentation, authorization mismatches, and specific coding errors.
- Denial Prediction Software Development: Recommends exact clinical documentation fixes to engineers and coders before submission occurs.
5. Adjudication and Exception Workflows
The orchestration layer handles anomalous files through clear programmatic routing rules.
- Exception Routing: Isolates failed claims into an audited human review queue based on role-based access control.
- Appeal Management: Assembles required documentation packs and schedules automated claim resubmission workflows.
6. Payment Posting and Analytics
The final accounting service closes the revenue loop through automated financial reconciliation.
- ERA Parsing: Ingests inbound EDI 835 remittance advice files and maps electronic records against open provider invoices.
- Underpayment Detection: Calculates contract terms against actual payer deposits to isolate underpayment anomalies.
- Performance Dashboards: Tracks micro-level clean claim rate trends, denial rates, and operational cost-per-claim metrics.
Integrating these 6 functional blocks establishes a highly resilient foundation that stops data defects before they turn into expensive rejections.
Mapping out these specific feature dependencies ensures your engineering team can construct a balanced system that directly addresses real-world payer volatile rules.
Claims Architecture That Guarantees Scalable Healthcare Workflows
A medical claims automation system architecture should connect claim intake, data extraction, payer-rule validation, AI models, adjudication workflows, payment posting, analytics, integrations, security controls, and audit logs into one traceable healthcare platform.
The architecture must support automation, compliance, and continuous payer-rule updates. This architectural alignment prevents performance drops when processing high-volume transactions during peak billing cycles.
The table below defines the technologies required to implement each specific architectural layer in production:
| Architectural Layer | Structural Components | Production Technology Stack Options |
| 1. User & Workflow Layer | Admin dashboard, claims workbench, human review queues, appeal workflows, and analytics views. | React.js, Next.js, Tailwind CSS, TypeScript, Apache Superset. |
| 2. Claims Data Layer | Claim records, patient data, provider data, payer data, supporting documents, and payment details. | PostgreSQL (relational logs), MongoDB (unstructured claims), AWS S3 (documents). |
| 3. Rules & Validation Layer | Payer-rule engine, coding rules, authorization rules, medical necessity checks, and rule versioning control. | Drools (Java), Celery Rules Engine (Python), Redis (caching active validation matrices). |
| 4. AI Automation Layer | OCR extraction pipelines, clinical NLP, denial prediction software development, and model confidence scoring. | PyTorch, Hugging Face Transformers (BERT/RoBERTa), AWS Textract, MLflow. |
| 5. Integration Layer | EHR/EMR systems, clearinghouses, FHIR claims integration development, HL7 interfaces, EDI 837/835. | HAPI FHIR server, Apache Camel, Mirth Connect, custom Python/Go X12 parsers. |
| 6. Security & Compliance Layer | PHI tokenization, role-based access control (RBAC), MFA, immutable audit trails, and access monitoring. | AWS KMS (envelope encryption), HashiCorp Vault, OAuth 2.0 / OIDC, Auth0. |
| 7. Monitoring & Governance Layer | Model drift tracking, rule change logs, claim outcome feedback loops, and SLA dashboards. | Prometheus, Grafana, Evidently AI (drift tracking), ELK Stack (log aggregation). |
1. User and Workflow Layer
This presentation layer provides specialized interfaces for system administrators, medical coders, and billing specialists. The claims workbench displays real-time execution logs and isolates failed files into managed human review queues to prevent outright electronic rejections.
Appeal workflows programmatically generate necessary documentation packs, while built-in analytics views track operational performance metrics.
2. Claims Data Layer
The storage layer utilizes a hybrid database approach to manage complex transactional schemas securely. Relational provider data, patient demographic fields, and payment data map cleanly to transactional databases to maintain strict referential integrity.
Unstructured data elements, including supporting documents, clinical PDF uploads, and raw JSON objects, route directly to encrypted object storage.
3. Rules and Validation Layer
This middle-tier execution layer powers your custom payer rule engine development, healthcare mechanics to enforce compliance before external transmission. Coding validation algorithms programmatically cross-reference incoming data packages against updated NCCI edits, CPT codes, and strict medical necessity criteria.
Implemented versioning matrices allow developers to track historical variations across distinct commercial insurance plans.
4. AI Automation Layer
The predictive layer uses custom machine learning pipelines to extract administrative concepts and calculate claim survival metrics. Specialized NLP for medical claims processing translates raw physician clinical notes into structured billing variables.
At the same time, denial prediction software development models evaluate transaction history to flag systemic rejections prior to data serialization.
5. Integration Layer
This communication bus standardizes connectivity with external electronic health record nodes and clearinghouse networks.
The subsystem handles bidirectional HL7 v2 messages, parses inbound files using FHIR claims integration development interfaces, and manages outbound X12 EDI 837/835 batch streams.
This translation bus isolates external messaging changes from your internal microservices logic.
6. Security and Compliance Layer
This foundational block provides the access controls required to comply with the strict HIPAA Security Rule.
The system implements PHI tokenization at the database tier alongside mandatory role-based access control to restrict personal data views.
Centralized security servers maintain immutable audit trails that track all read, write, and export actions for compliance readiness.
7. Monitoring and Governance Layer
The telemetry system monitors operational health to track application performance, model drift, and rule change logs. Feedback loops inject final payer adjudication outcomes back into the training pipelines to update the prediction algorithms regularly.
Meanwhile, operational SLA dashboards give engineering teams immediate visibility into data processing velocities.
Structuring your software platform around these 7 decoupled layers prevents systemic updates from destabilizing your underlying core operational business logic. This modular design gives your engineering team the agility required to scale transaction volume without incurring crippling technical debt.
How to Build a Medical Claims Automation Platform
Building an enterprise medical claims automation platform requires systematic orchestration across engineering, data science, and compliance disciplines. Rather than treating automation as a single software update, our engineering teams deploy a modular pipeline that handles data ingestion, algorithmic validation, and predictive modeling sequentially.
Following this structured development path prevents structural bottlenecks and ensures clear data traceability through every stage of the claim lifecycle.
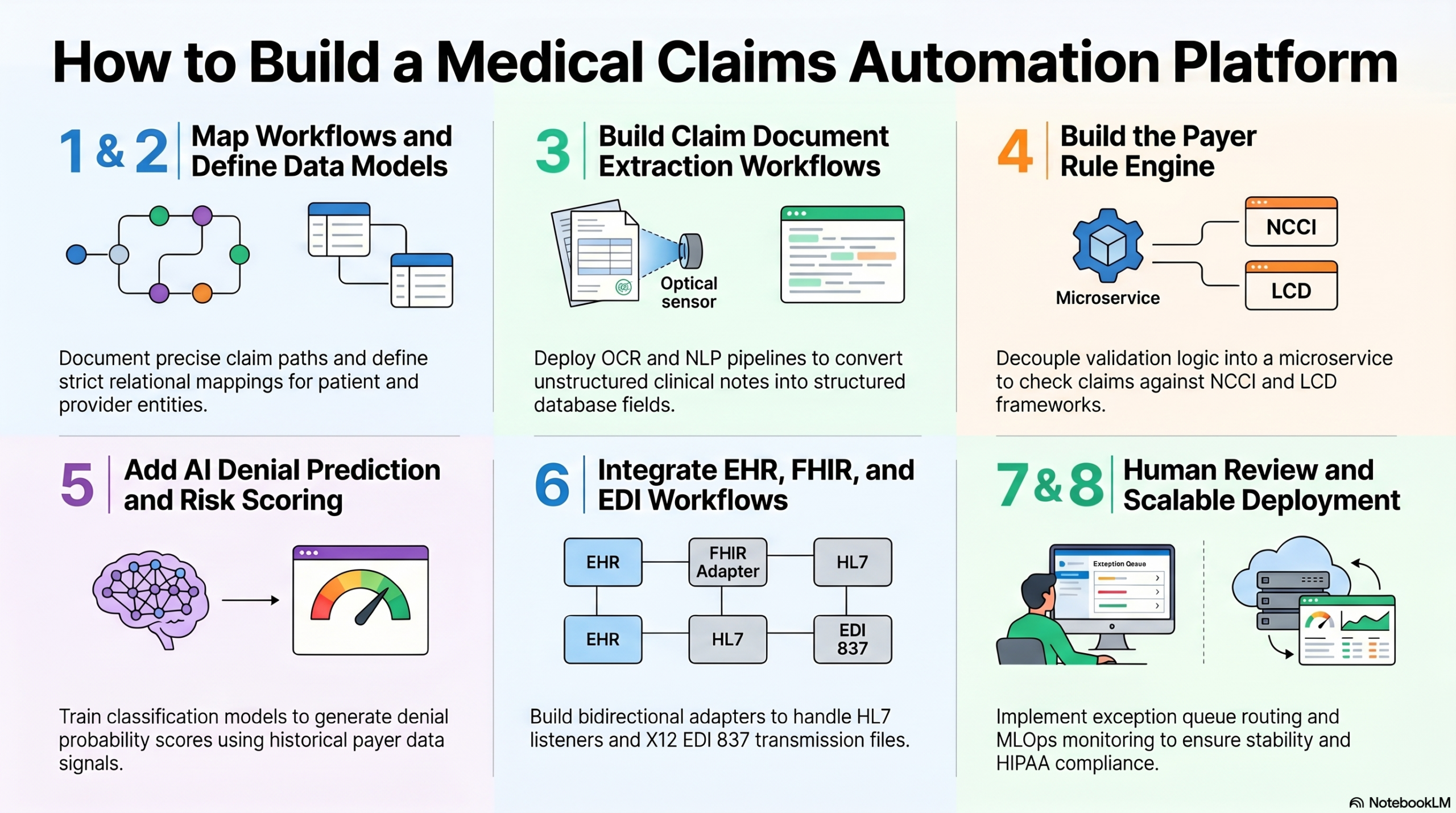
Step 1: Map Claims Workflows and Automation Scope
We start by mapping the full claims lifecycle before choosing AI models or architecture. This includes intake, eligibility, coding, authorization, submission, payer validation, denial handling, resubmission, payment posting, and human review thresholds.
Our development teams perform an exhaustive discovery phase covering:
- Workflow Discovery: Documenting the precise paths that medical claims follow from clinical charting to final bank reconciliation.
- Claim Type Mapping: Categorizing institutional (UB-04) versus professional (CMS-1500) data flow requirements.
- Manual Task Inventory: Documenting repetitive, human-executed steps like manual prior authorization cross-checking and data entry.
- Denial Reason Analysis: Isolating historical claim rejection drivers to prioritize automated intervention strategies.
- MVP Scope Selection: Defining the initial high-value transaction pathways to automate without over-engineering complex edge cases.
If an engineering team skips this comprehensive mapping step, developers risk automating low-value tasks while leaving the true denial drivers completely untouched.
Step 2: Define the Claims Data Model
The claims data model defines how patient, provider, payer, diagnosis, procedure, authorization, document, payment, and denial data move through the platform. A clean data model makes automation reliable and audit-ready.
To construct a resilient system, we build a decoupled relational database schema paired with an extensible document store.
- Claim Entity Structure: Defining strict relational mappings between core patient IDs, National Provider Identifiers (NPI), and specific payer plan codes.
- Coding Field Mappings: Enforcing strict data validation attributes for standard medical vocabularies, including ICD-10-CM diagnostic categories, CPT procedural arrays, and HCPCS modifier fields.
- Status Lifecycle State Machine: Engineering an explicit state machine to track transaction progression from ingestion to final reconciliation.
- Event Logging Arrays: Structuring immutable ledger attributes within the database to record all read, write, and programmatic modifications.
Skipping this foundational data design step causes AI model outputs to become highly inconsistent because downstream components cannot trust or trace the underlying claim properties.
Step 3: Build Claim Document Extraction Workflows
Claim intake workflows bring data into the platform from EHRs, billing tools, clearinghouses, payer portals, PDFs, scanned forms, spreadsheets, and APIs. OCR and NLP then convert unstructured documents into structured claim fields.
The data ingestion pipelines we deploy execute the following programmatic steps:
- Multi-Source Ingestion: Utilizing monitored SFTP endpoints and webhook listeners to automatically capture clinical document uploads and digital claim images.
- OCR Layout Extraction: Running specialized layout-aware models to isolate handwritten text, checkbox states, and structured grid arrays from paper documentation.
- Clinical NLP Classification: Using deep learning architectures to process unstructured physician clinical notes to identify relevant diagnostic and therapeutic variables.
- Confidence Scoring Gates: Assigning a mathematical confidence metric to every extracted entity before database insertion to route low-confidence fields to human review queues.
If this automated extraction layer is missing or poorly implemented, manual data entry continues, and automation only works on clean claims already prepared by humans.
Step 4: Build the Payer Rule Engine
The payer rule engine validates claims against payer-specific requirements before submission. It checks eligibility, authorization, coding, modifiers, medical necessity, documentation, contract rules, and plan-level exceptions.
The underlying software architecture we implement decouples rule validation logic from core application code by utilizing an event-driven rules microservice:
- Rule Authoring Interface: Creating an abstract management console that allows compliance personnel to update validation profiles without developer intervention.
- Temporal Versioning Control: Enforcing precise, effective dates and explicit payer-plan mappings to prevent processing conflicts during retrospectives.
- Compliance Framework Cross-Reference: Programmatically validating transaction records against thousands of active NCCI edits, LCD compliance matrices, and NCD compliance frameworks.
- Exception Logic Paths: Building conditional routing rules to handle specialized modifier logic and the coordination of benefits variables automatically.
Skipping this structural isolation means claims may pass internal checks but still fail at the payer level, destroying your first-pass acceptance rate.
Step 5: Add AI Denial Prediction and Claim Risk Scoring
AI denial prediction models score claims based on historical denial patterns, payer behavior, coding quality, authorization status, documentation gaps, and claim complexity. These scores help teams fix risky claims before submission.
To train these predictive pipelines, we execute a rigorous machine learning engineering process:
- Dataset Normalization: Ingesting a comprehensive historical claims dataset containing normalized denial reason codes across all integrated payers.
- Feature Engineering: Isolating specific signal combinations, such as particular provider taxonomy codes grouped with specific CPT modifiers.
- Model Inference Training: Deploying classification models like XGBoost or specialized transformers to generate an explicit denial probability score alongside localized explainability vectors.
- Outcome Feedback Loops: Structuring telemetry pipelines to feed final adjudication results back into the training data to update prediction weights automatically.
Without predictive scoring, the platform remains entirely reactive and only processes rejections after expensive reimbursement delays have already occurred.
Step 6: Integrate EHR, FHIR, HL7, and EDI Workflows
Claims automation becomes valuable only when it connects to the systems that already hold claims, patient, payment, and payer data. These integrations include EHRs, billing systems, clearinghouses, payer APIs, FHIR, HL7, EDI 837, and EDI 835.
Our integration engineers build bidirectional connection adapters to handle diverse healthcare data standards:
- HL7 Event Listeners: Ingesting real-time ADT (Admission, Discharge, Transfer) messages to capture instant patient demographic updates.
- FHIR Claims Integration Development: Connecting to modern hospital systems via JSON-based FHIR R4 endpoints to query clinical resources directly.
- EDI 837 Serialization Engines: Compiling validated database claim records into highly standardized X12 EDI 837 transmission files.
- EDI 835 Remittance Decoders: Parsing incoming electronic remittance advice files to execute automated financial reconciliation loops.
If these secure interfaces are skipped, teams must manually move data between systems, which severely reduces automation ROI. This protective abstraction guarantees high system availability when processing massive bulk files.
Step 7: Build Human Review and Appeal Workflows
Human review workflows route complex, high-risk, or low-confidence claims to the right team before submission or resubmission. This keeps AI useful without giving it unchecked authority over sensitive healthcare and payment decisions.
The application interfaces we construct manage exception handling through structured UI workflows:
- Exception Queue Routing: Isolating failed claims into targeted worklists based on specific validation errors and role-based access control.
- Contextual Claims Workbench: Displaying the targeted AI risk factors alongside the original clinical source documentation to assist human review.
- Immutable Override Tracking: Recording the exact cryptographic logging and textual justification for every manual data modification.
- SLA Monitoring Dashboards: Tracking the operational velocity of isolated claims to ensure files never stall within human verification steps.
Omitting human review guardrails can create hidden processing errors, compliance exposure, or significant staff resistance to the platform. This balanced design preserves strict compliance with the HIPAA Privacy Rule.
Step 8: Deploy, Monitor, and Scale the Platform
Deployment is not the final step in claims automation. The platform needs model monitoring, payer-rule updates, audit reporting, claim outcome feedback, user analytics, and infrastructure scaling to stay accurate over time.
To maintain production stability, we implement an enterprise infrastructure governance framework:
- MLOps Monitoring Pipelines: Tracking real-time prediction accuracy to detect model drift and data distribution shifts automatically.
- Rule Engine Auditing: Creating automated triggers that flag discrepancies between internal rule versions and external clearinghouse rejections.
- Kubernetes Cloud Scaling: Deploying containerized microservices that scale horizontally to handle intense data processing spikes during end-of-month billing.
- Security Telemetry Dashboards: Monitoring data access patterns to enforce PHI tokenization compliance and detect unauthorized data reads instantly.
Executing these 8 development steps transforms raw billing workflows into a highly secure, automated enterprise asset. Building your custom platform with this level of structural isolation allows your organization to outpace changing compliance demands while minimizing manual engineering maintenance.
Must-Have AI Models for Claims Automation Platforms
Claims automation platforms use OCR for document extraction, NLP for clinical and denial text interpretation, LLMs for summarization and reviewer support, and machine learning models for denial prediction. The strongest systems combine AI models with deterministic payer rules and human review.
This multi-model approach creates an intelligent data pipeline capable of converting unstructured clinical evidence into clean, compliant transaction sets.
1. OCR for Claims Data Extraction
Our development approach uses layout-aware optical character recognition (OCR) to convert static image files into searchable, structured data objects.
- Scanned Forms: Processing paper CMS-1500 and UB-04 submittals without losing spatial formatting.
- Explanation of Benefits (EOB): Extracting line-item data fields, payment amounts, and adjustment codes from complex physical sheets.
- Medical Bills and Supporting Documents: Ingesting multi-page patient encounter itemizations and external laboratory reports.
- Prior Authorization Forms: Capturing approval timestamps, reference numbers, and authorized service thresholds directly from document scans.
2. NLP for Medical and Claims Text
We deploy clinical Natural Language Processing (NLP) models to parse technical vocabulary and map contextual linguistic patterns.
- Diagnosis and Procedure Extraction: Identifying documented patient symptoms, chronic conditions, and surgical techniques from free-text physician logs.
- Denial Reason Classification: Analyzing unstructured text narratives from inbound payer letters to classify the root cause of non-payment.
- Medical Necessity Signals: Scanning clinical progress notes to ensure the documented severity of illness justifies the exact CPT code billed.
- Clinical Note Review: Cross-referencing physician charting against internal database fields to catch structural documentation gaps before submission.
3. LLMs for Claims Review Support
Large Language Models (LLMs) function exclusively as assistant layers within our system architecture to summarize data and accelerate human validation.
- Claim Packet Summarization: Condensing hundreds of pages of medical history into a one-page timeline highlighting relevant procedures and diagnoses.
- Appeal Draft Support: Programmatically generating targeted appeal letter templates by matching rejected claims against embedded contract terms.
- Policy Explanation: Translating dense, complex commercial payer manuals into plain-language summaries for technical billing teams.
- Documentation Gap Summaries: Producing clear, actionable checklists that point out exactly which clinical reports are missing from an audit pack.
4. Machine Learning for Denial Prediction
We implement supervised machine learning algorithms to evaluate overall transactional safety before files leave the secure enterprise network.
- Claim Risk Scoring: Utilizing gradient-boosted decision trees to calculate an explicit probability of rejection before final submission.
- Payer Behavior Modeling: Analyzing historical adjudication data arrays to spot localized payment trend shifts among specific insurers.
- Coding Mismatch Detection: Highlighting statistically rare combinations of ICD-10-CM codes and CPT codes that indicate a potential billing error.
- Authorization Risk Flags: Triggering system notifications when a claim contains high-cost procedures that lack an attached authorization token.
5. Rules Engines for Deterministic Validation
Deterministic rule frameworks work alongside our predictive AI layers to enforce absolute mathematical and regulatory boundaries.
- Payer Policies: Running fixed crosswalk matrices that reflect the explicit coverage requirements of specific commercial groups.
- CPT/ICD Checks: Validating data lines against millions of active federal NCCI edit relationships to block basic formatting errors.
- Modifier Rules: Verifying that administrative modifiers conform to strict timing and conditional processing guidelines.
- Plan-Specific Requirements: Isolating unique, plan-level deductible or coverage exceptions directly at the billing boundary.
[Unstructured Data] ──> [OCR / NLP] ──> [Deterministic Rules Engine] ──> [ML Denial Prediction] ──> [Clean Claim]
6. Architectural Operational Warning
Engineering teams must never position LLMs as final, automated decision-makers within a production revenue cycle environment. At the same time, LLMs are prone to logical hallucinations and lack the rigid traceability required to defend institutional choices during an audit.
Instead, our system designs use LLMs strictly to assist human reviewers, ensuring that every generated summary or appeal reference points directly back to an immutable, traceable database source link.
Combining probabilistic machine learning with deterministic validation matrices guarantees that your platform operates with both administrative flexibility and complete legal compliance.
This balanced AI architecture ensures high operational throughput while insulating your healthcare networks from costly processing anomalies.
AI Model Governance for Claims Automation Platforms
AI model governance ensures that every automated claim recommendation can be monitored, explained, audited, and improved. For claims automation, this means tracking model inputs, confidence scores, output reasons, reviewer overrides, version history, drift, and claim outcomes.
This rigorous transparency framework protects organizations from compliance risks while ensuring long-term model reliability in volatile regulatory environments.
Establishing these structural oversight policies matches established industry security blueprints, such as the NIST AI Risk Management Framework.
1. Model Versioning and Auditing
We design the automation infrastructure to explicitly document the specific deployment states responsible for every transaction decision.
- Production State Tracking: Storing unique model IDs, pipeline architecture variations, and training dataset weights alongside individual processed transaction numbers.
- Auditable Record Maintenance: Retaining explicit version-controlled execution snapshots across multi-year intervals to provide unambiguous data trails during retrospective payer investigations.
- Rollback Safeguards: Enabling engineering teams to instantly revert inference endpoints to historical, verified operational configurations if newly deployed updates produce processing anomalies.
2. Explainability and Local Feature Attribution
Our architectures expose the explicit mathematical logic driving automated risk classifications directly to business users.
- Risk Factor Visibility: Utilizing mathematical framework layers like SHAP (Shapley Additive exPlanations) to display the top three denial-risk drivers on the reviewer screen.
- Clinical Source Referencing: Creating direct, highlighted programmatic linkages between calculated risk alerts and original data items inside physician progress summaries.
- Clear Classification Labels: Replacing ambiguous binary probability variables with explicit contextual reasoning strings that state exactly why a file was flagged.
3. Confidence Scoring and Automated Routing
We build dynamic inference routing gates to isolate high-risk electronic files away from final submission channels.
- Confidence Calculation Gating: Evaluating real-time model calculation vectors against fixed mathematical tolerance percentiles prior to data transmission.
- Straight-Through Execution Boundaries: Allowing transactions that score above a 95% confidence threshold to pass to outbound EDI channels completely unsupervised.
- Automated Exception Routing: Isolating low-confidence transaction packages immediately into managed worklists to enforce multi-point structural checks.
4. Human Override Tracking and Label Auditing
The system records human adjustments to continuously capture operational knowledge and optimize backend learning loops.
- Action Capture Ingestion: Forcing logging modules to document every instance where a billing specialist changes an automated categorization suggestion.
- Justification Code Inventories: Mandating the entry of textual or categorized operational rationales whenever software recommendations are actively rejected.
- Performance Delta Tracking: Monitoring systemic capture errors to determine if human modifications consistently resolve downstream rejection rates.
5. Bias and Error Monitoring Across Demographics
Execute structured telemetry sweeps to isolate localized system decay before it hurts overall clean claim rates.
- Segmented Performance Sweeps: Aggregating baseline model failure metrics categorized explicitly by individual commercial insurance entities, plan tiers, and provider networks.
- Clinical Specialty Isolation: Flagging systematic scoring deviations that surface only during specific clinical procedures or regional laboratory classifications.
- Data Distribution Alarms: Sounding architectural alerts when inbound payload characteristics drift away from parameters used during core training cycles.
6. Closed-Loop Outcome Feedback Mechanics
Our experts implement automated synchronization pipelines that close the operational gap between pre-submission risk scoring and actual financial adjudication.
- Outcome Ingestion Loops: Mapping finalized 835 remittance data elements back to the baseline feature parameters utilized during early inference pipelines.
- Automated Retraining Triggers: Initiating model retraining procedures in automated staging environments when real-world performance falls below predefined SLA tolerances.
- Validation Array Optimization: Continuously updating downstream model test blocks with validated payer rejections to expand prediction breadth systematically.
Enforcing complete technical accountability across your machine learning infrastructure transforms opaque prediction code into an auditable enterprise-grade asset. This structural safety layer guarantees that your software can reliably scale transactional volumes without introducing unpredictable compliance liabilities or hidden revenue cycle leakage
For a deeper breakdown of secure healthcare AI controls, see our guide on HIPAA-Compliant AI RCM Platform Development.
HIPAA Compliance Controls for Medical Claims Automation
A HIPAA-compliant claims automation platform needs administrative, physical, and technical safeguards that protect PHI throughout the claims lifecycle. These controls should appear in product architecture, access policies, integrations, audit trails, vendor workflows, and operational procedures.
Recent regulatory shifts have eliminated the traditional distinction between “required” and “addressable” specifications, making complete technical defense implementations mandatory for all engineering pipelines.
1. Administrative Safeguards
The development framework wraps software delivery in rigid institutional security policies to control organizational risk.
- Workforce Access Rules: Restricting backend server access parameters exclusively to engineers with verified operational clearance levels.
- Security Training Requirements: Enforce automated tracking loops to ensure all system users finish data safety certifications annually.
- BAA Management: Validating that comprehensive BAAs exist for every connected clearinghouse and third-party data stream.
- Incident Response Plans: Building distinct, automated alerting structures to isolate data segments within 24 hours of detecting a data anomaly.
2. Technical Safeguards
The platform enforces mathematical verification and cryptographic isolation across every internal data routing bus.
- Mandatory Encryption Protocols: Implementing AES-256 for all claims data at rest and TLS 1.3 for all data loops in transit. (Source: [NIST, 2025]).
- Role-Based Access Control (RBAC): Restricting application API endpoints so that users only see data rows matching their active job scope.
- Multi-Factor Authentication (MFA): Requiring cryptographic tokens or biometric keys at every user and developer system access node.
- Immutable Audit Logs: Storing system activity logs in detached, append-only databases to track all reads, modifications, and exports.
3. Privacy Controls
Advanced data scrubbing limits the exposure of Protected Health Information during automated processing.
- Minimum Necessary Standards: Restricting database query payloads to pull only the specific clinical attributes needed to process the current transaction line.
- PHI Tokenization and Masking: Replacing direct identifiers like Social Security Numbers and patient names with secure cryptographic tokens in non-production environments.
- Strict Data Retention Execution: Engineering automated cron jobs that permanently purge historical data tables once contractually mandated storage periods expire.
4. Claims-Specific Compliance Controls
The platform maintains strict historical record links to document the exact compliance state of every transaction.
- Coding Traceability Logs: Storing clear snapshots of the clinical notes used by the system to justify selected ICD-10-CM codes during audit checks.
- Payer Communication Archival: Recording all raw outbound X12 EDI 837 payloads and inbound 835 remittance records in audited folders.
- Reviewer Action History: Tracking every manual change made inside human review worklists, including the user ID and text explanation.
5. Enterprise Readiness
Continuous system validation layers satisfy the rigorous security requirements of health network procurement teams.
- Biannual Vulnerability Scans: Running automated testing tools every six months to detect configuration weaknesses across containerized clusters.
- Annual Penetration Testing: Hiring certified third-party ethical hackers every 12 months to simulate adversarial attacks against application boundaries.
- SOC 2 Type II Readiness: Maintaining evidence-gathering systems that continually document operational control performance across multi-month observation windows.
Building a custom platform around these rigid safeguard standards stops expensive structural data breaches and eliminates the threat of regulatory compliance penalties.
This security-first engineering strategy allows organizations to pass enterprise procurement reviews quickly, turning regulatory compliance into a competitive business advantage.
Real ROI From Medical Claims Automation Platforms
Medical claims automation ROI usually appears in phases. Teams often see early gains from reduced manual review and cleaner claim intake, followed by stronger ROI from denial prevention, payment posting automation, and payer-rule optimization after more claims data flows through the system.
The Progressive Realization Timeline
Organizations must plan for a staggered realization model rather than expecting complete automation of the revenue cycle on day one.
System optimization scales proportionally with the volume of transactional telemetry captured by your database layers.
First 60–90 Days After Launch
- Cleaner Claim Intake: Automated parsing layers eliminate basic formatting mismatches at the ingestion boundary.
- Fewer Manual Data-Entry Tasks: Specialized NLP components take over structural text extraction from digital clinical documentation.
- Better Claim Visibility: Unified centralized dashboards isolate processing anomalies immediately.
- Faster Exception Routing: Low-confidence files route to specific user worklists without stalling clean transaction batches.
Months 3–6
- Reduced Rework Loops: The application of local version-controlled validation constraints stops recurring submission mistakes.
- Improved First-Pass Claim Accuracy: Clean claim rates show measurable upward trends as common validation failures drop.
- Better Denial Categorization: Parsing scripts categorize inbound rejection data to expose underlying workflow defects.
- More Reliable Payment Posting: Basic automated matching of incoming electronic remittance advice reduces manual ledger entries.
Months 6–12
- Stronger Denial Prediction: Predictive machine learning pipelines achieve high accuracy as local training sets grow.
- Better Payer-Specific Optimization: The rules engine adapts to localized policy adjustments based on captured contract variances.
- Lower Manual Review Loads: High-confidence straight-through processing paths expand to cover standard transactional paths.
- Reimbursement-Cycle Improvements: Total days in accounts receivable begin dropping as payment velocity increases.
12+ Months
- Rule Optimization: Automated compliance matrices run with minimal maintenance overhead.
- Model Improvement: Continuous closed-loop feedback pipelines minimize model drift across all deployment nodes.
- Enterprise Scaling: The decoupled microservices footprint expands to handle new provider locations seamlessly.
- Advanced Analytics Assets: Long-term transactional ledgers expose systemic payer behavior anomalies to guide strategic contracting decisions.
Core Performance Benchmark Ranges
Actual operational outcomes depend entirely on project scope, EHR integration depth, and local payer complexity.
At the same time, well-engineered platforms target specific performance brackets across six primary financial categories.
| Performance Metric Category | Pre-Automation Baseline | Post-Automation Target Range |
| Manual Review Reduction | 60% – 80% of total claims processed | 10% – 15% exception queue retention |
| Denial-Rate Reduction | 11% average industry rejection rate | 2% – 4% sustained clean target range |
| Claim Cycle-Time Improvement | 7 – 14 days manual validation lag | < 24 hours programmatic transmission |
| Cost-Per-Claim Reduction | $7.13 average manual overhead cost | $1.25 – $2.10 automated processing cost |
| Payment Posting Accuracy | 85% manual ledger allocation rate | 98%+ automated ERA matching precision |
| Appeal Workload Reduction | 45+ minutes manual package assembly | < 5 minutes automated draft compilation |
Average administrative overhead drops by more than 40% when moving from manual processes to automated transactions. These ranges represent realistic engineering targets for teams building dedicated custom platforms.
Designing a platform around this realistic ROI framework ensures that technical leadership can justify ongoing infrastructure development without relying on unrealistic marketing hype.
Build vs Buy: Choosing the Right Claims Automation Strategy
Buy an off-the-shelf claims automation tool when your workflows are standard, your integrations are limited, and speed matters more than product differentiation.
At the same time, build a custom platform when payer logic, AI models, compliance requirements, workflows, integrations, or SaaS ownership are central to your business.
Making the wrong strategic choice here can result in either severe technical debt or restrictive operational limitations that stunt your platform’s long-term scale.
The Strategic Decision Framework
Engineering teams should evaluate their development path against a structured matrix of operational constraints and long-term product objectives.
The chart below breaks down the clear technical signals that justify buying a pre-built software vendor license versus building a custom claims automation platform:
| Core Decision Drivers | Buy an Off-the-Shelf Software Vendor | Build a Custom Claims Automation Platform |
| Workflow Complexity | Standard, highly repeatable billing setups with minimal variations. | Proprietary payer-rule logic and localized medical policies. |
| AI Processing Scope | Basic generic OCR tools and high-level template matching. | Custom denial prediction software development and specialized NLP. |
| Integration Flexibility | Limited endpoints that align perfectly with standard vendor APIs. | Enterprise-grade integrations across legacy HL7 and FHIR networks. |
| Product Ownership Goals | Zero intellectual property accumulation; ongoing recurring licensing. | High asset value; creating a core healthcare SaaS product. |
| Development Timeline | Accelerated deployment; immediate out-of-the-box basic tooling. | Multi-month phased roadmap focused on structural optimization. |
The Hybrid Implementation Path
For enterprise healthcare networks that cannot compromise on workflow flexibility but still require fast engineering velocity, a hybrid software delivery strategy represents the most viable operational compromise.
This architectural approach avoids the classic either-or trap by combining pre-built infrastructure components with proprietary application layers.
When executing a hybrid development model, engineering teams follow a systematic migration process:
- Leverage Existing Foundation: Retain your stable, legacy core databases and basic electronic data interchange connection nodes.
- Layer Proprietary Intelligence: Construct decoupled, custom microservices to handle advanced AI-powered prior authorization automation, specific NLP parsing, and custom claims denial prediction software development.
- Orchestrate Custom Workflows: Build separate, tailored human review worklists and specialized payer rules engine workflows to manage your unique business logic.
- Execute Modular Replacement: Phase out legacy clearinghouse adapters over time, replacing them with modern, direct payer API integration adapters.
At Intellivon, we deliver value through a phased custom development framework that mirrors this exact optimized hybrid philosophy.
We mitigate implementation risk by identifying your highest-ROI workflows during the discovery phase and building out a highly scoped Minimum Viable Product (MVP) first.
This strategy allows your organization to capture early administrative cost savings while systematically scaling your infrastructure into a comprehensive, enterprise-grade claims automation ecosystem.
Why Intellivon For Medical Claims Automation?
At Intellivon, we help healthcare SaaS founders, CTOs, RCM companies, TPAs, insurtech teams, and enterprise healthcare businesses build AI-powered claims processing platforms around real operational needs.
With 500K+ engineering hours, ex-MAANG engineers, and deep experience across AI, SaaS, healthcare platforms, API integrations, and enterprise software development, we help teams move from claims bottlenecks to scalable claims infrastructure.
A. We Help You Define The Right Claims Processing Scope
Before development starts, we map your claims workflow, user roles, payer touchpoints, document flow, denial patterns, and integration needs.
This helps us define what your platform should solve first.
We help you plan:
- Claims intake workflows
- AI automation opportunities
- MVP feature scope
- Payer rule requirements
- EDI and clearinghouse needs
- Compliance controls
- Platform roadmap
This keeps the first version focused, practical, and tied to measurable claims outcomes.
B. We Build AI Workflows Around Real Claims Operations
AI should support claims teams, not create another system they have to fight with.
Intellivon builds AI workflows that help teams review claims faster, detect missing data, flag denial risks, route exceptions, and prioritize high-value work.
Your platform can include:
- AI claims intake
- OCR-based document extraction
- NLP for claim notes and documents
- Claim validation rules
- Denial risk scoring
- Smart work queues
- Exception routing
- Appeal support workflows
- Revenue and claims analytics
Every workflow is designed around how claims teams actually work.
C. We Integrate With Healthcare And Payer Systems
Claims processing software depends on accurate data movement.
That is why Intellivon plans integrations early. We help connect your platform with the systems needed to process, validate, submit, and track claims.
We support integrations across:
- EHR and EMR systems
- Practice management systems
- Clearinghouses
- Payer APIs
- EDI 837 and 835 workflows
- HL7 and FHIR interfaces
- Payment systems
- ERP and finance platforms
- Document storage systems
These integrations help your platform move claims from intake to adjudication support, denial prevention, payment tracking, and reporting.
D. We Design Claims Platforms With Security From Day One
Claims software handles PHI, payer data, financial data, and sensitive operational records. Security cannot be treated as a final-stage checklist.
Intellivon designs claims platforms with healthcare-grade controls from the start.
This can include:
- PHI protection
- Data encryption
- Role-based access control
- Secure authentication
- Audit trails
- User activity tracking
- Admin permissions
- Secure cloud deployment
- Compliance-ready documentation
This helps your platform support enterprise buyers, healthcare teams, and regulated claims workflows with confidence.
Ready To Build AI Claims Processing Software?
If you are planning to build AI healthcare claims processing software, Intellivon can help you define the right roadmap before development begins.
We will help you identify the best AI use cases, map payer and EDI workflows, plan integrations, design secure architecture, and build a scalable platform around real claims processing outcomes.
Conclusion
Treating a medical claims automation platform as core infrastructure, rather than just workflow software, is essential for long-term revenue resilience. Success depends on three foundational decisions, which include dynamic payer-rule design, strict AI governance, and a compliant, integrated architecture.
By scoping this automation in phases, engineering teams can systematically control risk, prove early ROI, and safely build toward true enterprise scale.
Things To Know About Claims Automation Platforms
Q1. How much does it cost to build a medical claims automation platform?
A1. Building an enterprise platform ranges from $50,000 to $200,000 based on AI scope, multi-payer integrations, and HIPAA controls. A focused MVP costs $50,000 to $150,000, while deep denial prediction pipelines require the full investment with annual maintenance tracking at 15% to 20% of initial build costs.
Q2. How long does it take to develop AI medical claims processing software?
A2. Developing a production-ready system takes 6 to 12 months. Initial workflow mapping and a focused MVP require 3 to 6 months of active engineering. Conversely, scaling to an enterprise-grade ecosystem with direct FHIR integrations, custom payer rules engines, and advanced automated workflow routing typically demands 12 or more months.
Q3. What AI models are used in claims automation?
A3. The architecture combines layout-aware OCR for document data capture, clinical NLP for diagnostic text extraction, machine learning for denial prediction scoring, and LLMs for reviewer summary support. These probabilistic models must function strictly as an operational layer alongside deterministic rules engines and audited human review workflows to guarantee traceability.
Q4. Can a claims automation platform reduce denial rates?
A4. Yes, it systematically drops denial rates by programmatically catching coding validation gaps, authorization mismatches, eligibility issues, and localized payer-rule non-compliance before submission. The highest clean claim rate gains occur when predictive machine learning denial scoring isolates risky transaction files directly into managed exception worklists for human verification.
Q5. Is a medical claims automation platform HIPAA-compliant?
A5. A custom platform achieves strict compliance by hardcoding AES-256 encryption, role-based access controls, immutable audit trails, and PHI tokenization layers directly into its core infrastructure. Your engineering team must enforce these technical safeguards across all external API endpoints and clear signed vendor BAAs before processing real patient records.